在数据仓库中,聚集(Aggregation)是一个重要的概念,它涉及到对大量详细数据进行统计和汇总,以便更高效地执行查询和分析。以下是关于数据仓库中聚集的详细解释:
- 概念:聚集是指按照维度粒度、指标和计算元的不同,依据实际分析需要对底层数据进行记录行压缩、表连接、属性合并等预处理,是对底层的详细数据进行相应的统计的数据加工形式。这些统计可能包括求和、求平均值等。聚集计算的结果是根据用户可能的查询预先计算好的汇总数据。
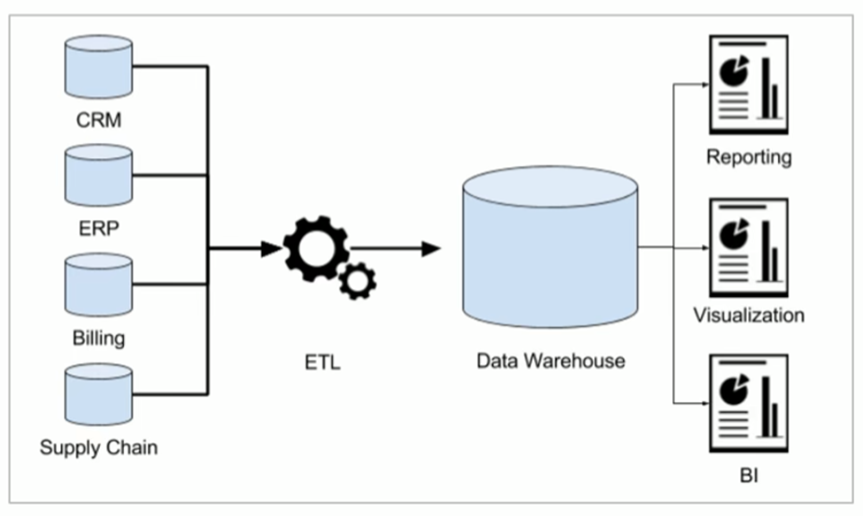
- 数据立方:给定维度集合的所有方体形成的方体格成为该维集合的数据立方(data cube)。数据立方的建立是通过聚集实现的。当数据立方的维数超过3时,它被称为超立方体或超维数聚集。
- 性能提升:数据聚集用于提升数据仓库系统进行OLAP(联机分析处理)时的性能。通过在问题提出之前就准备好答案来缩短查询相应时间,是OLAP技术能够快速相应的基础。聚集降低了直接访问基础数据对前端应用的影响,减少了对基础数据的重复计算,使用聚集可以在一定程度上保证数据一致性。
- 应用:在星型模式(Star Schema)中,聚集星型模式是一种特殊的数据结构,其中事实和维度属性与基本星型模型中相关的事实和维度属性一致。对于利用聚集的查询,可能涉及替换表名和关键字列的重写工作。在选择星型模式时,为了获得最理想的性能,可能需要考虑采用在事实表中具有行数最少并且能够回答查询的聚集星型模式。
- 设计原则:在设计聚集时,应遵循一些最佳实践。例如,仅仅允许有经验的开发人员拥有访问聚集的权利,而终端用户和没有经验的开发人员仅允许访问基本星型模式。此外,从原始星型模式构建聚集模式时,应围绕性能的原则开展设计工作,并确保采用一致性的概念指导聚集设计,以保证汇总获得一致的结果并使重写查询的过程变得尽可能简单。
- 工具支持:许多数据仓库和商业智能工具都支持聚集功能,如Tableau、Microsoft Power BI、IBM SPSS Modeler等。这些工具提供了丰富的数据分析和可视化功能,可以帮助用户更有效地管理和分析数据仓库中的数据。
数据仓库中的“聚集”是一个核心概念,它涉及到对大量详细数据的统计和汇总,以支持高效的查询和分析。以下是关于数据仓库中聚集的详细阐述:
1. 定义和目的
聚集是指按照维度粒度、指标和计算元的不同,对底层的详细数据进行预处理的过程。这种预处理可能包括记录行压缩、表连接、属性合并等操作,目的是对数据进行相应的统计加工,如求和、求平均值等。聚集的结果是预先计算好的汇总数据,这些数据是根据用户可能的查询需求来计算的。
2. 数据立方(Data Cube)
在数据仓库中,给定维度集合的所有方体形成的方体格被称为数据立方(Data Cube)。数据立方的建立是通过聚集实现的。数据立方中的每个单元格都代表一个特定维度组合的聚合数据值。当数据立方的维数超过3时,它被称为超立方体或超维数聚集。
3. 性能提升
聚集在数据仓库中的主要目的是提高查询性能。通过在问题提出之前就准备好答案,聚集可以显著缩短查询响应时间。此外,聚集降低了直接访问基础数据对前端应用的影响,并减少了对基础数据的重复计算。使用聚集可以在一定程度上保证数据一致性,从而提高数据仓库的可靠性和稳定性。
4. 应用场景
- 销售数据分析:销售数据、库存数据、客户数据等可以通过数据仓库进行综合分析,以了解市场需求及产品销售情况。聚集可以帮助企业快速计算销售额、销售量、库存周转率等指标,从而支持决策制定。
- 市场营销分析:数据仓库可以整合和分析大量的市场数据,如用户调研数据、产品销售数据、竞争对手数据等。通过聚集,企业可以了解市场趋势和竞争状况,优化营销策略,提升市场份额和盈利能力。
- 客户关系管理:数据仓库可以整合和分析客户数据,包括客户的基本信息、购买记录、客户反馈等。通过聚集,企业可以了解客户的需求和购买行为,精准定位目标客户,制定个性化的营销策略,提升客户满意度和忠诚度。
- 金融风控:数据仓库可以整合和分析各类金融数据,如贷款数据、信用卡交易数据、欺诈数据等。通过聚集,企业可以快速计算风险指标、评估贷款申请人的信用状况,从而制定有效的风控策略。
5. 设计原则
在设计聚集时,应遵循以下原则:
- 一致性:确保聚集数据与原始数据保持一致,避免出现数据不一致的情况。
- 简洁性:尽量简化聚集过程,减少不必要的计算和数据传输。
- 灵活性:考虑未来可能的查询需求和分析场景,设计具有灵活性的聚集方案。
- 安全性:限制对聚集数据的访问权限,确保数据安全。
6. 工具支持
许多数据仓库和商业智能工具都支持聚集功能,如Tableau、Microsoft Power BI、IBM Cognos等。这些工具提供了丰富的数据分析和可视化功能,可以帮助用户更有效地管理和分析数据仓库中的数据。
总之,数据仓库中的聚集是一种重要的数据处理技术,它可以提高查询性能、减少数据冗余并保证数据一致性。在设计和实施聚集时,应遵循最佳实践并考虑使用适当的工具来支持。