深度学习模型蒸馏(Model Distillation)是一种将大型、复杂模型(称为教师模型)的知识传递给小型、简单模型(称为学生模型)的技术。这种技术的目的是减少模型的大小和计算复杂性,同时尽量保留原始模型的学习能力。通过蒸馏,学生模型可以学习到教师模型的决策边界,从而提高其性能。同时,由于学生模型通常更简单,它的决策过程也更容易解释。
原理:
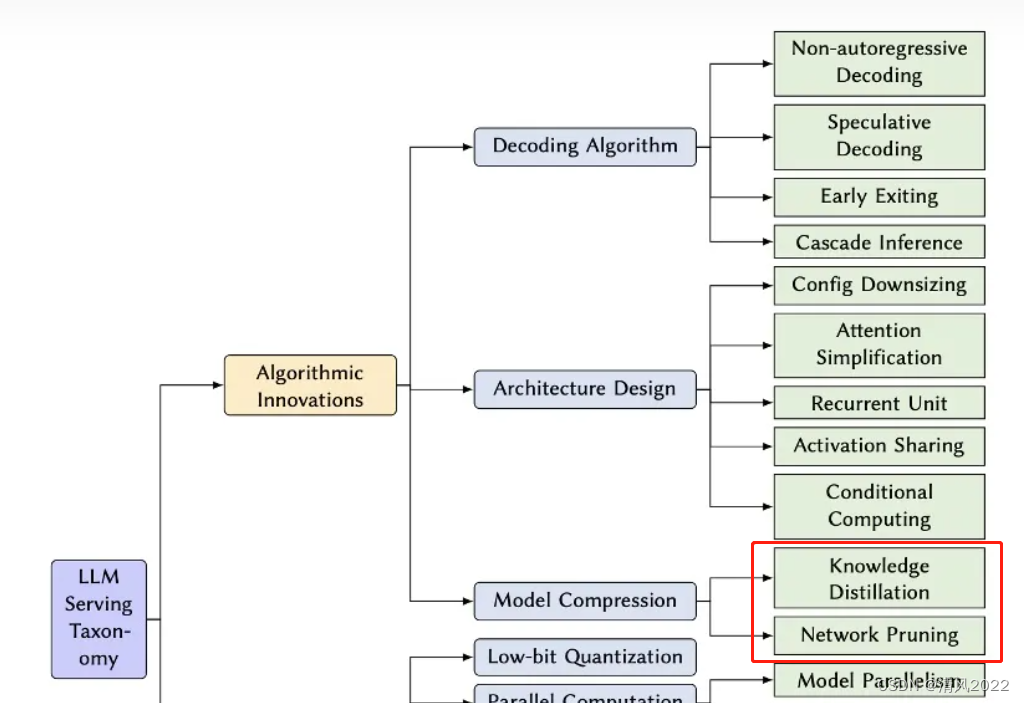
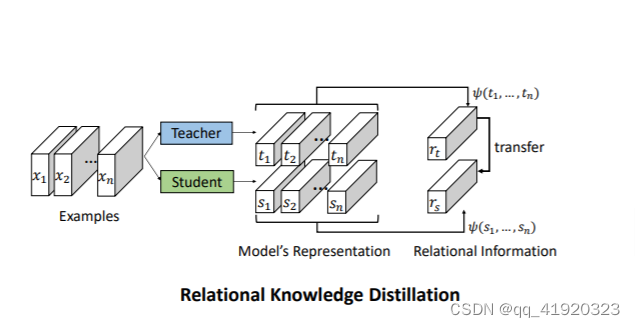
- 知识蒸馏框架:蒸馏通常涉及一个训练好的教师模型和一个未训练的学生模型。教师模型在训练数据上生成软标签(即类别的概率分布),而不是硬标签(即类别标签)。
- 软标签训练:学生模型使用这些软标签进行训练,而不是使用硬标签。这允许学生模型学习到教师模型对不同类别的相对置信度,而不仅仅是最终的预测。
- 决策边界学习:通过这种方式,学生模型不仅学习到了正确分类数据,还学习到了如何区分易混淆的类别。
流程:
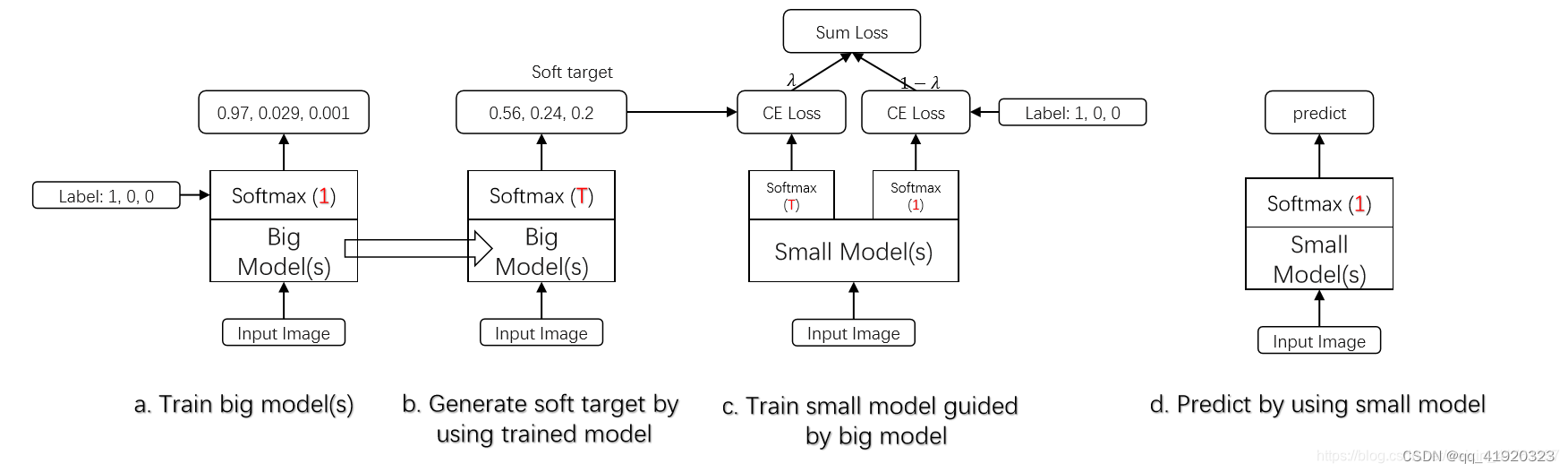
- 训练教师模型:首先,您需要训练一个大型、复杂的模型,即教师模型。这个模型应该能够在其任务上达到较高的性能。
- 生成软标签:使用教师模型对训练数据进行预测,生成软标签。这些软标签包含了模型对每个类别的预测概率。
- 训练学生模型:使用这些软标签来训练一个较小的学生模型。学生模型的结构应该比教师模型简单,以便于解释和理解。
- 评估学生模型:一旦学生模型训练完成,您可以在测试数据上评估其性能。理想情况下,学生模型应该接近教师模型的性能,同时具有更高的可解释性。
目的:
- 减少模型大小:通过蒸馏,可以将大型模型的知识压缩到更小的模型中,减少模型的参数数量,从而降低计算成本。
- 提高可解释性:较小的模型通常更容易解释,因为它们具有更简单的决策过程和更少的参数。
- 保持性能:蒸馏的目的是尽量保留教师模型的性能,同时获得一个更小、更易解释的模型。
在您的模型中实施蒸馏,您需要按照上述步骤进行。首先,确保您的教师模型已经训练好了。然后,使用该模型生成软标签,并用这些软标签来训练一个更简单、更易于解释的学生模型。最后,评估学生模型的性能和可解释性。