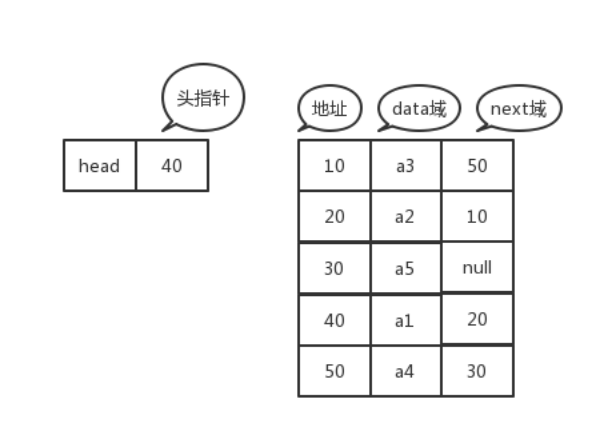
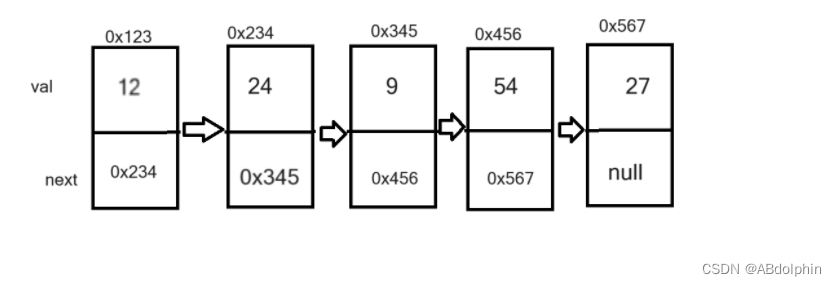
链表:链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的
自己实现一个链表:
public class SingleLinkedList {
//头插法
public void addFirst(int data){
}
//尾插法
public void addLast(int data){
}
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data){
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key){
return false;
}
//删除第一次出现关键字为key的节点
public void remove(int key){
}
//删除所有值为key的节点
public void removeAllKey(int key){
}
//得到单链表的长度
public int size(){
return -1;
}
public void clear() {
}
public void display() {}
}
首先,链表分为无头(有头),双向(单向),循环(非循环)链表。我们主要研究的是无头单向非循环链表和无头双向非循环链表。
无头单向非循环链表:一个链表有多个节点构成,节点中既要存放要存放的数据,还要存放下一个节点的地址,从而实现将多个节点连接起来。所以构建一个链表的类,再构建一个节点的内部类,内部类的成员变量有,存放的数据和一个地址,在链表的类中定义一个存放地址的变量来存放这个链表的首元素地址。
class MySingleLinkedList{
ListNode head;
static class ListNode{
public int val;
public ListNode next;
public ListNode(int val) {
this.val = val;
}
}//内部类
}
1, 得到单链表的长度 size():我们要遍历链表,然后count++;
问:遍历链表时,循环的条件是什么?
答:建立一个变量,这个变量指向头结点,通过.next访问下一个节点,进行遍历。当这个遍历为null时停止,也就是指向最后一个节点的下一个节点。
public int size(){
int count=0;
ListNode cur=head;
while (cur!=null){
count++;
cur=cur.next;
}
return count;
}
2,display():遍历链表(遍历方法与上一个方法相似),注意判断链表为空的时候,防止空指针异常
public void display() {
if (head==null){
return;
}
ListNode cur=head;
while (cur!=null){
System.out.print(cur.val+" ");
cur=cur.next;
}
System.out.println();
}
3, clear();两种方法,法一:直接将头结点置为空,法二:遍历链表,将每个节点置为空
public void clear() {
head=null;
}
public void clear2(){
while (head!=null){
ListNode cur=head.next;
head.next=null;
head=cur;
if (cur!=null){
cur=cur.next;
}
}
}
4,头插法 addFirst:判断head是否为空(也就是链表中是否有节点),如果没有节点,创立一个节点,head等于这个节点的地址,如果链表中有节点,则创建一个节点,将这个节点的next的值改为下一个节点的地址,也就是头结点的地址,再将头结点的地址改为新建的这个节点的地址。
public void addFirst(int val){
if (head==null){
ListNode node=new ListNode(val);
head=node;
return;
}
ListNode node=new ListNode(val);
node.next=head;
head=node;
}
5,尾插法 addLast:首先,判断链表是否为空,如果为空,则直接建立一个节点,并将头结点指向这个节点,如果链表不为空,则需要遍历这个链表找到最后一个节点的位置,将最后一个节点的next改为创立的这个新节点的地址。
public void addLast(int val){
if (head==null){
ListNode node=new ListNode(val);
head=node;
return;
}
ListNode node=new ListNode(val);
ListNode cur=head;
while (cur.next!=null){
cur=cur.next;
}
cur.next=node;
}
6,任意位置插入,第一个数据节点为0号下标 addIndex:首先,判断输入坐标的合法性,如果不合法,抛出异常,如果合法,找到指定下标的位置的前一个节点,创建一个新的节点,将新节点的next改为前一个节点的next,将前一个节点的next改为新节点的地址。
public class IndexException extends RuntimeException {
public IndexException(){
}
public IndexException(String mag){
super(mag);
}
}//异常
private void IndexNotLegal(int index)throws IndexException{
if (index>size()||index<0){
throw new IndexException("坐标异常");
}
}//判断下标是否合法
public void addIndex(int index,int val){
try{
IndexNotLegal(index);
}catch (IndexException e){
e.printStackTrace();
return;
}
if (index==0){
addFirst(val);
return;
}
if (index==size()){
addLast(val);
return;
}
ListNode node=new ListNode(val);
ListNode cur=head;
while ((index-1)!=0){
cur=cur.next;
index--;
}
node.next=cur.next;
cur.next=node;
}
7,查找是否包含关键字key是否在单链表当中 contains:遍历链表,找到关键字返回true,没找到返回false
public boolean contains(int key){
if (head==null){
return false;
}
ListNode cur=head;
while (cur!=null){
if (cur.val==key){
return true;
}
cur=cur.next;
}
return false;
}
8,删除第一次出现关键字为key的节点 remove:首先,解决链表为空的情况,然后遍历链表,找到该节点,将该节点的上一个节点的next改为该节点的下一个节点的地址
注意:找到节点的val为关键字的节点时,不能用cu.val==key来判断,因为这样虽然找到了数值为关键字的节点,但是没有办法找到该节点的上一个节点的地址,所以不能将该节点的上一个节点的next改为下一个节点的地址。所以应该用cur.next.val==key来判断,这样是利用上一个节点来访问下一个节点的数值是与关键字相等。
public void remove(int key){
if (head==null){
return;
}
ListNode cur=head;
if (head.val==key){
head=head.next;
}
while (cur.next!=null){
if (cur.next.val==key){
cur.next=cur.next.next;
return;
}
cur=cur.next;
}
}
9,删除所有关键字为key的节点 removeAll:我们可以多次使用 remove来删除,但是如果想要时间复杂为O(n)也就是只遍历一次链表,我们可以用两个变量来遍历,一个变量cur负责找到目标节点,另一个变量prev来储存目标节点的前一个节点。如果cur的节点为目标节点,那么prev.next等于cur.next。如果cur的节点为不是目标节点,cur和prev同时往下一个节点走。但这样遍历之后不能对头节点的数值进行判断,所以最后要另外对头节点进行判断
问:为什么要最后判断头节点的值
答:因为如果先判断的头节点的值后,头节点就变成的原链表的第二个节点了,经过遍历判断,还是判断不了头节点,也就是现在的第二个节点
public void removeAllKey(int key){
if (head==null){
return;
}
ListNode cur=head.next;
ListNode prev=head;
while (cur!=null){
if (cur.val==key){
prev.next=cur.next;
}else {
prev=cur;
}
cur=cur.next;
}
if (head.val==key){
head=head.next;
}
}
无头双向非循环链表:一个节点类中,成员变量有想要存放的数据,下一个节点的地址,和上一个节点的地址。在链表类中,成员变量有头节点的地址和尾节点的地址。
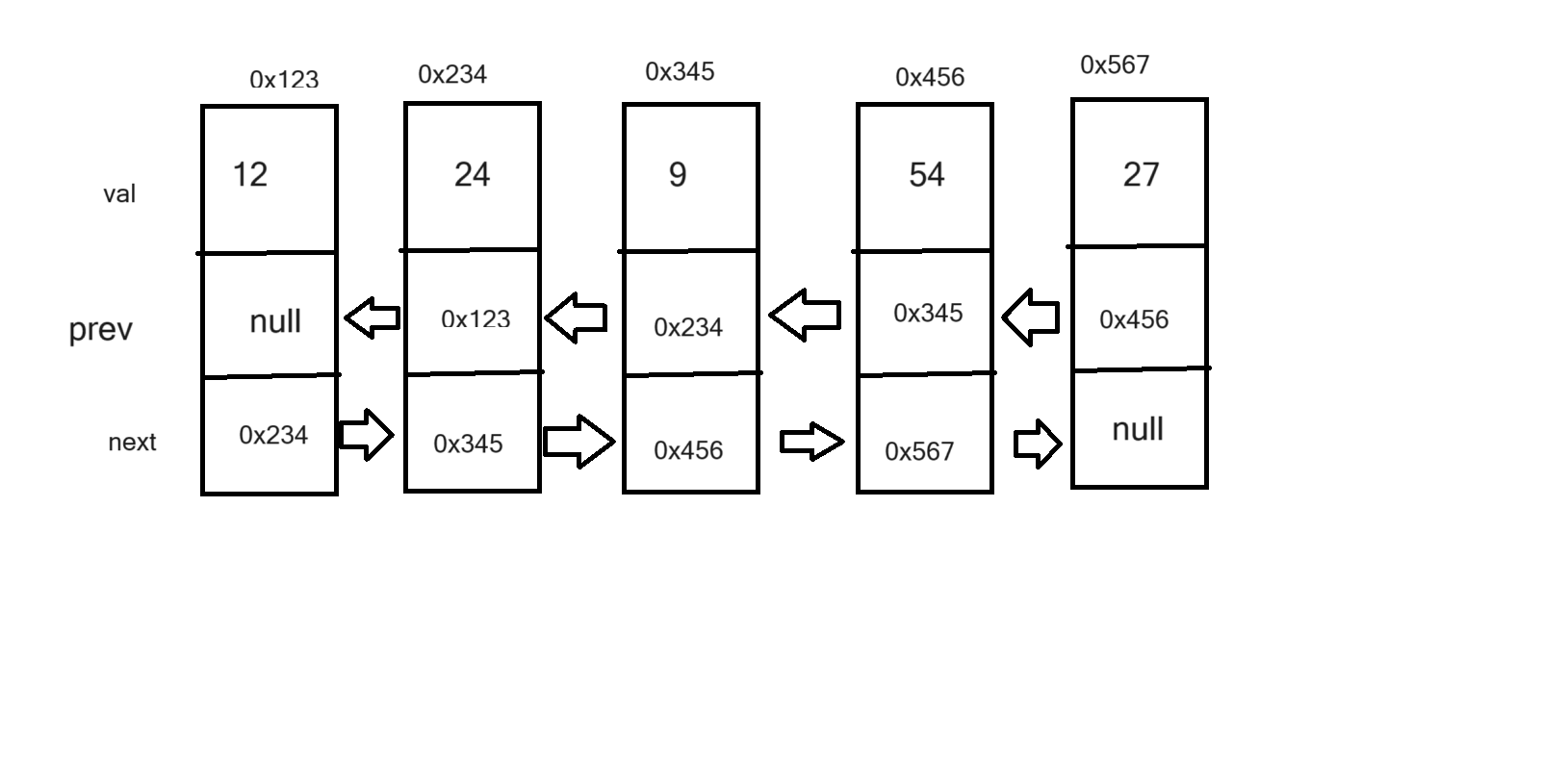
public class MyLinkedList {
//头插法
public void addFirst(int data){ }
//尾插法
public void addLast(int data){}
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data){}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key){}
//删除第一次出现关键字为key的节点
public void remove(int key){}
//删除所有值为key的节点
public void removeAllKey(int key){}
//得到单链表的长度
public int size(){}
public void display(){}
public void clear(){}
}
class MyLinkList{
ListNode head;
ListNode last;
public static class ListNode{
public int val;
public ListNode prev;
public ListNode next;
public ListNode(int val) {
this.val = val;
}
}//内部类
}
1, size()display() clear():均与无头单向非循环链表长度求法相似,不再过多赘述
public int size(){
ListNode cur=head;
int count=0;
while (cur!=null){
cur=cur.next;
count++;
}
return count;
}
public void display(){
ListNode cur=head;
while (cur!=null){
System.out.print(cur.val+" ");
cur=cur.next;
}
System.out.println();
}
public void clear(){
head=last=null;
}
public void clear2(){
ListNode cur=head;
while (cur!=null){
ListNode curN=cur.next;
cur.prev=null;
cur.next=null;
cur=curN;
}
head=last=null;
}
2,addFirst():如果链表为空,则创立一个新的节点,头节点和尾结点都指向这个节点。如果链表不为空,那么创立一个新节点,新节点的next等于头节点,头节点的prev等于新节点,让后将头结点的指向向前移,指向这个新节点
public void addFirst(int val){
if (head==null){
ListNode node=new ListNode(val);
head=last=node;
return;
}
ListNode node=new ListNode(val);
node.next=head;
head.prev=node;
head=node;
}
3,addLast:因为双向列表具有尾结点,所以不需要像单向链表一样,需要遍历得到最后一个节点的地址,首先,如果链表为空,与头插法的解决方法一样,如果不为空,则创一个新节点,新节点的prev等于尾结点的地址,尾结点的next等于新节点的地址,然后尾结点向后指向,指向新节点
public void addLast(int val){
if (last==null){
ListNode node=new ListNode(val);
head=last=node;
return;
}
ListNode node=new ListNode(val);
last.next=node;
node.prev=last;
last=node;
}
4,addIndex:首先,判断下标的合法性,不合法则抛出异常,创建一个变量cur,找到目标下标的节点,将新节点的next改为cur节点的地址,将新节点的prev改为cur节点的prev,将cur.prev.next改为新节点的地址,将cur的prev值改为新节点的地址
private void IndexNotLegal(int index)throws IndexException {
if (index>size()||index<0){
throw new IndexException("坐标异常");
}
}//异常的书写与单向链表的一致,不在重复书写
public void addIndex(int index,int val){
try {
IndexNotLegal(index);
}catch (Exception e){
e.printStackTrace();
}
if (index==0){
addFirst(val);
return;
}
if (index==size()){
addLast(val);
return;
}
ListNode node=new ListNode(val);
ListNode cur=head;
while (index!=0){
cur=cur.next;
index--;
}
node.next=cur;
node.prev=cur.prev;
cur.prev.next=node;
cur.prev=node;
}
5, contains:与单向链表一致
public boolean contains(int key){
ListNode cur=head;
while (cur!=null){
if (cur.val==key){
return true;
}
cur=cur.next;
}
return false;
}
6,remove:(较难)分情况讨论

public void removeAllKey(int key) {
if (head == null) {
return;
}
ListNode cur = head;
while (cur != null) {
if (cur.val==key) {
if (head == cur) {
head = head.next;
if (head != null) {
head.prev = null;
return;
} else {
last = null;
return;
}//注意:这里要小心,只有一个节点时,该如何处理!!!
} else if (last== cur) {
last.prev.next = null;
last = last.prev;
return;
} else {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
return;
}
}
cur = cur.next;
}
}
7,removeAllKey,与上述思路一致
public void removeAllKey(int key) {
if (head == null) {
return;
}
ListNode cur = head;
while (cur != null) {
if (cur.val==key) {
if (head == cur) {
head = head.next;
if (head != null) {
head.prev = null;
} else {
last = null;
}//这里要小心,只有一个节点时,该如何处理
} else if (last== cur) {
last.prev.next = null;
last = last.prev;
} else {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
}
cur = cur.next;
}
}
LinkedList类的使用:
1,实现了List接口
2,底层为双向链表
3,随意插入和删除效率高,比较适合在任意位置插入节点
实例化链表:

遍历链表:
法一:
System.out.println(linkedList);
法二:
for (Integer x:linkedList){
System.out.print(x+" ");
}
System.out.println();
法三:
for (int i = 0; i < linkedList.size(); i++) {
System.out.print(linkedList.get(i)+" ");
}
System.out.println();
法四:(迭代器)
Iterator<Integer> it=linkedList.iterator();
while (it.hasNext()){
System.out.print(it.next()+" ");
}
System.out.println();
ArrayList和LinkedList的区别:
1,前者物理连续,后者逻辑连续
2,前者头插法,需要搬移元素,效率低,后者修改引用指向,时间复杂度为O(1)
3,前者满时需要扩容,后者没有容量概念
4,前者适用于元素高效储存或频繁访问,后者,任意位置插入删除频繁