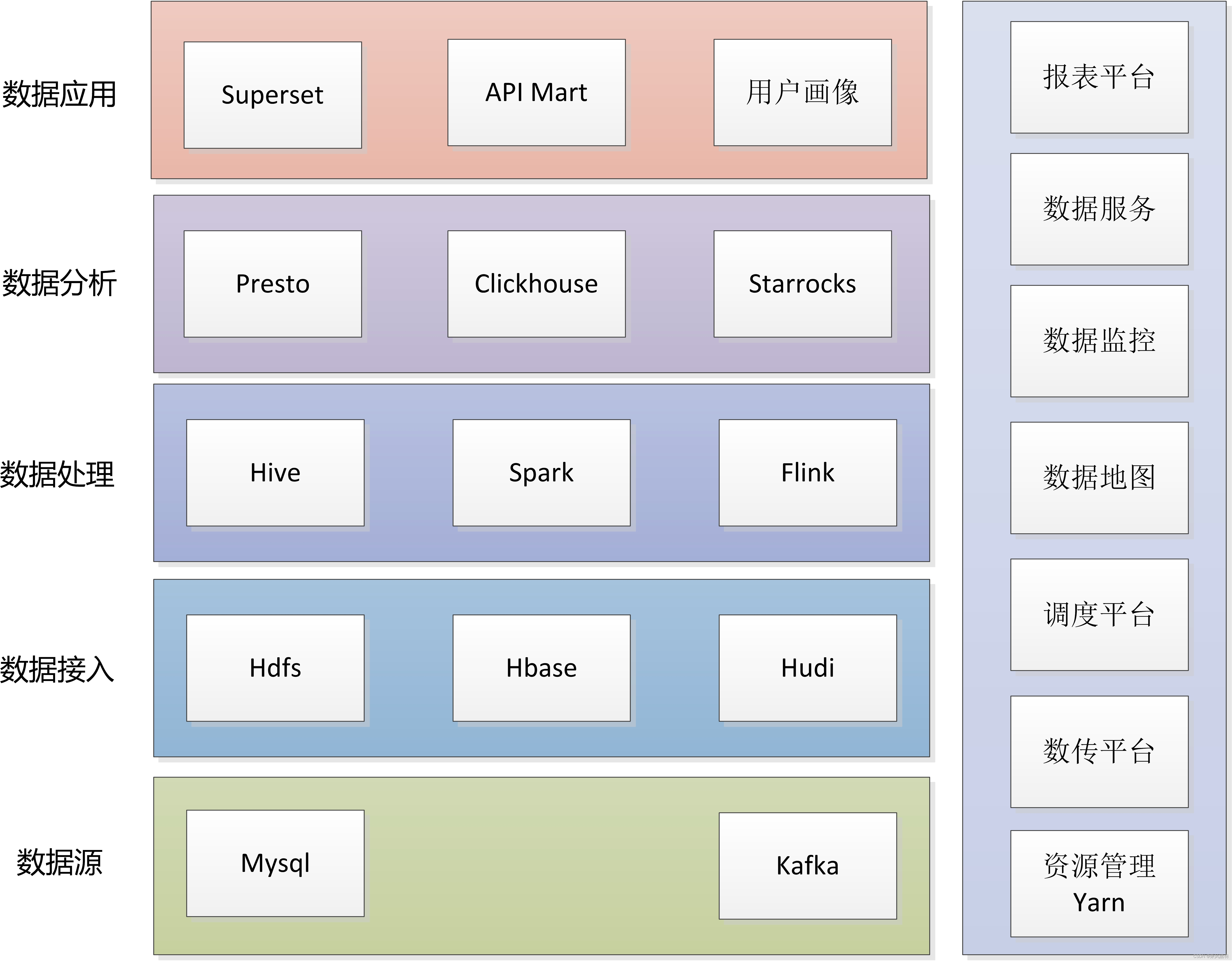
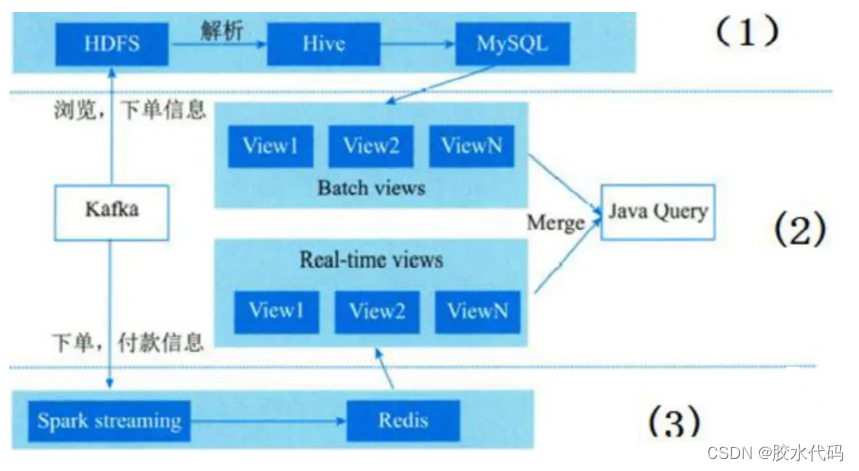
某网广告平台展示的数据指标包含两类:曝光类(包括曝光数、点击数、点击单价、花费),转化类(包括转化下单数、转化下单金额、转化付款数、转化付款金额)。前一类的数据主要由流量方以接口的方式提供(比如对接的腾讯广点通平台),后一类则是某网特有的数据,通过买家的浏览、下单、付款日志算出来。
批处理层:将Kafka中的浏览、下单消息同步到HDFS中,再将HDFS中的日志数据解析成Hive表,最终将Hive表导出到MySQL。通过定时任务调用第三方API获取曝光和点击数,每天定时写入另一张MySQL表。
实时处理层:用Spark Streaming程序监听Kafka中的下单、付款消息,计算出每个追踪链接维度的转化数据,存储在redis中。
服务层:Java服务读取两张MySQL表和一个Redis库的数据。
【问题1】
该平台采用了典型的Lambda架构形式,架构图如图所示。图中,(1)(2)(3)分别是哪三层?
(1) 批处理层
(2) 服务层
(3) 流处理层(实时处理层)
【问题2】
典型的大数据架构,除了Lambda架构之外,还有kappa架构,这两个架构的区别如下标所示,请补充表中空(1)-(4)
| 对比内容 | Lambda架构 | Kappa架构 |
| 复杂度与开发、维护成本 | 需要维护两套系统,复杂度高,开发、维护成本高 | (1) 只需要维护一套系统,复杂度低,开发、维护成本低 |
| 计算开销 | (2) 需要一直运行批处理和实时计算,计算开销大 | 必要时进行全量计算,计算开销相对较小 |
| 实时性 | 满足实时性 | (3) 满足实时性 |
| 历史数据处理能力 | (4) 批示全量处理,吞吐量大,历史数据处理能力强 | 流式全量处理,吞吐量相对较低,历史数据处理能力相对较弱 |
【问题3】
该平台目前的架构存在两个问题:
第一,其数据处理层比较简单,性能的瓶颈在Java服务层。服务层需要关联两张MySQL表,查询过程很复杂。
第二,实时数据只对接了内部的kafka消息,没有实时的获取第三方的曝光、点击、浏览数据。
请问应该如何改进这两个问题?
1. 在数据层面只维护一张包含所有指标的MySQL表,表中的stday字段作为索引,stday=当天的保存实时数据,stday<当天的保存离线数据。
2. 在实时处理层做了一个常驻后台的python脚本,不断调用第三方API的小时报表,更新stday=当天的曝光类字段。