问:介绍一下你做个实习项目吧?
我的实习项目呢,他是基于微服务框架体系的物流项目中,主要负责人,货,车三者之间的调度关系。主要的黄金链路就是用户下单 -> 快递员揽收->通过一系列的调度完成商品运单的运输->再到快递员派送商品->用户签收的整个流程。主要的模块主要就是调度模块,通过调度模块来异步的调度其他模块,包括运单模块,订单模块,路线规划模块等等。
问:讲讲用户支付流程吧?(应届生不要讲该模块,支付涉及的问题太多了,讲出来也很假。涉及的表:交易单表,退款单表,渠道表)

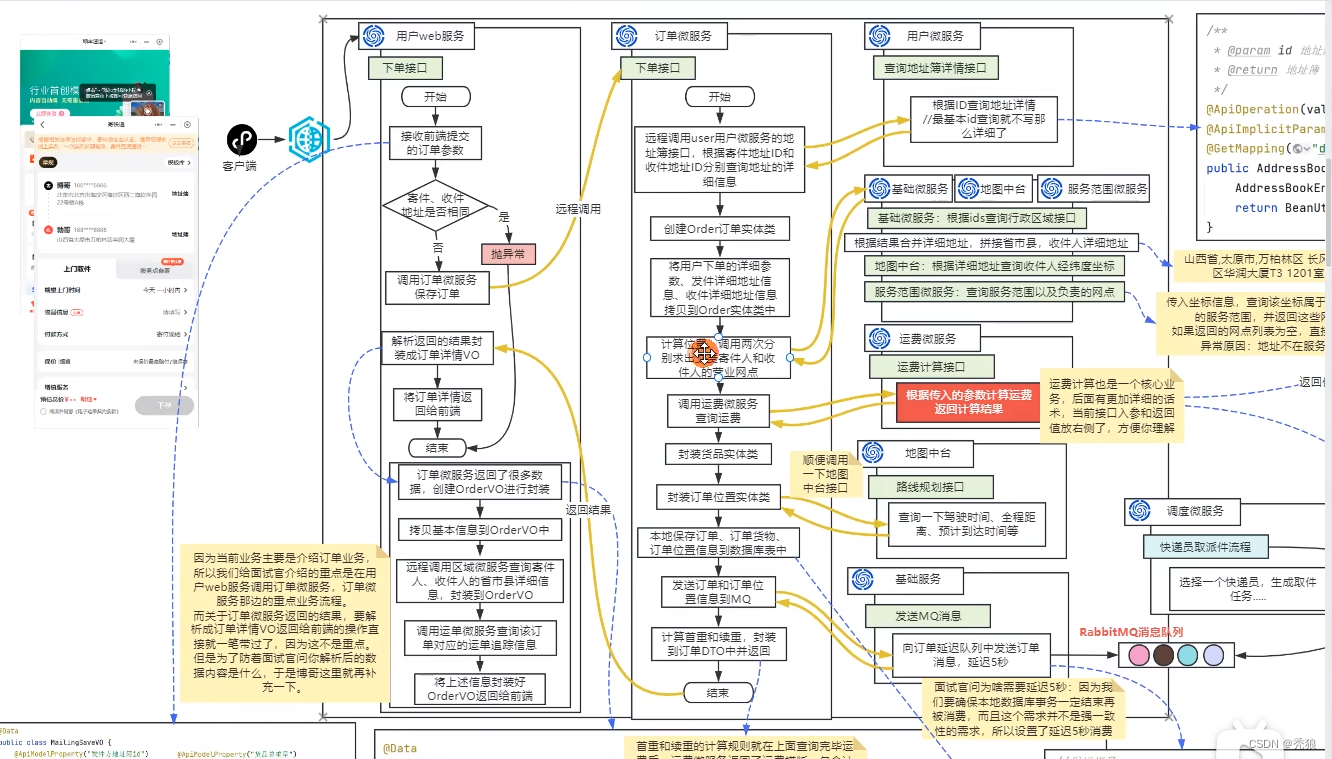
在用户下单前主要就是填写,起点和终点的地址,及快递员取件时间(先保存在前端)。在下单(此时还未付款)后会就会发送一次消息到调度执行,调度中心发送对应的延迟消息到快递员服务找到对应的快递快递员进行取件,在快递员取件后会计算对应的体积和重量,此时我们需要计算出对应的快递费用,我们主要根据用户填写省/市匹配对应的计费模板,模板主要就是包括,同城寄,省内寄,经济区互寄,配合模板计算出费用,最终展示给前端。用户点击支付,就会生成订单数据并调用easySDK生成对应的字符二维码。在这个过程中,我们需要考虑支付的幂等性,防止用户多次支付问题,最常见的解决方法就是使用交易单唯一ID来做判断,但是,在这个业务场景中我们还需要考虑用户更换支付方式的问题,更换支付方式时交易单ID也是一样的。所以我们这里的解决方案就是使用分布式锁+判断订单状态来实现的。我们使用redisson实现分布式锁锁住订单id,并判断订单的状态,如果是已支付就直接报错,如果是支付中,我们就要判断支付方式是否发生改变,如果改变就重新生成交易ID,否则报错。如果是取消订单的话修改交易单状态。
用户完成支付后,会调用回调函数发送订单数据到调度中心,修改订单的支付状态。我们orderId主要就是通过雪花算法生成的。这边需要考虑的就是网络波动得问题,网络波动就可能不会调用回调函数。所以我们会有一个兜底策略。主要就是使用定时任务定时查看支付状态在发送并修改订单状态和发送消息。哦对了,这边还做了个小小的优化,最开始的时候我们生成二维码直接通过hutool来生成的,但是呢,在后续进行测试的时候,当吞吐量表较高的时候,生成二维码的效率明显很低,那我不如直接将生成二维码的操作交给客户端,通过前端来生成二维码,主要就是通过QRCode.js来实现的,效率上明显就提高了。
我们支付模块中主要用两种支付方式,但是呢在后续可能会增加其他的饿支付方式,所以我们将这个做了个支付中台。主要就是通过自定义注解+工厂模式+ioc+反射实现支付模板切换。我给您介绍一下大概的流程,您看行吗?
不同的支付类都会实现一个工厂接口,支付类的主要方法就是支付,退款等等。都会配置到ioc中,支付模板表主要就是支付标签,appId,密钥,私钥,商户id等等。调对应的工厂类就会通过反射获取ioc中的所有的实现支付类(主要就是提高hutool.getBean(.class)来实现的),通过自定义注解的支付标签进行匹配返回对应的支付类。
问:如果用户下单的是到付的话,是怎么实现的呢?
我们会在用户下单的时候发送取件消息,在快递员取件成功后,直接发送消息生成运单,完成对应的调度后,在快递员完成派送且用户签收前生成对应的订单数据,最终生成支付二维码完成支付操作。
问:你们这个地图状态是怎么匹配出负责网点的呢?
用户会提供起点和终点,且会选择对应的省,市,区。我们通过调用高德地图接口计算出对应的经纬度。服务网点的作用范围我们使用Mongdb进行存储的,主要就是通过经纬度集合做交集来判断网点的负责范围。最终返回对应的负责网点id,如果没有找到就直接报错。
问:退款是怎么做的呢?
有支付的话,肯定就需要退款的业务,退款对应一张退款表,退款表的主要字段就订单id,退款金额,退款状态等等。系统中退款需要在收货七天前退,并且修改终点及起点的信息,再计算最短路径的时候计算出的集合做拼接的操作。调用支付类的退款方法,发送对应的消息到调度中心,
问:运费模板和运费计算是怎么设计的呢?
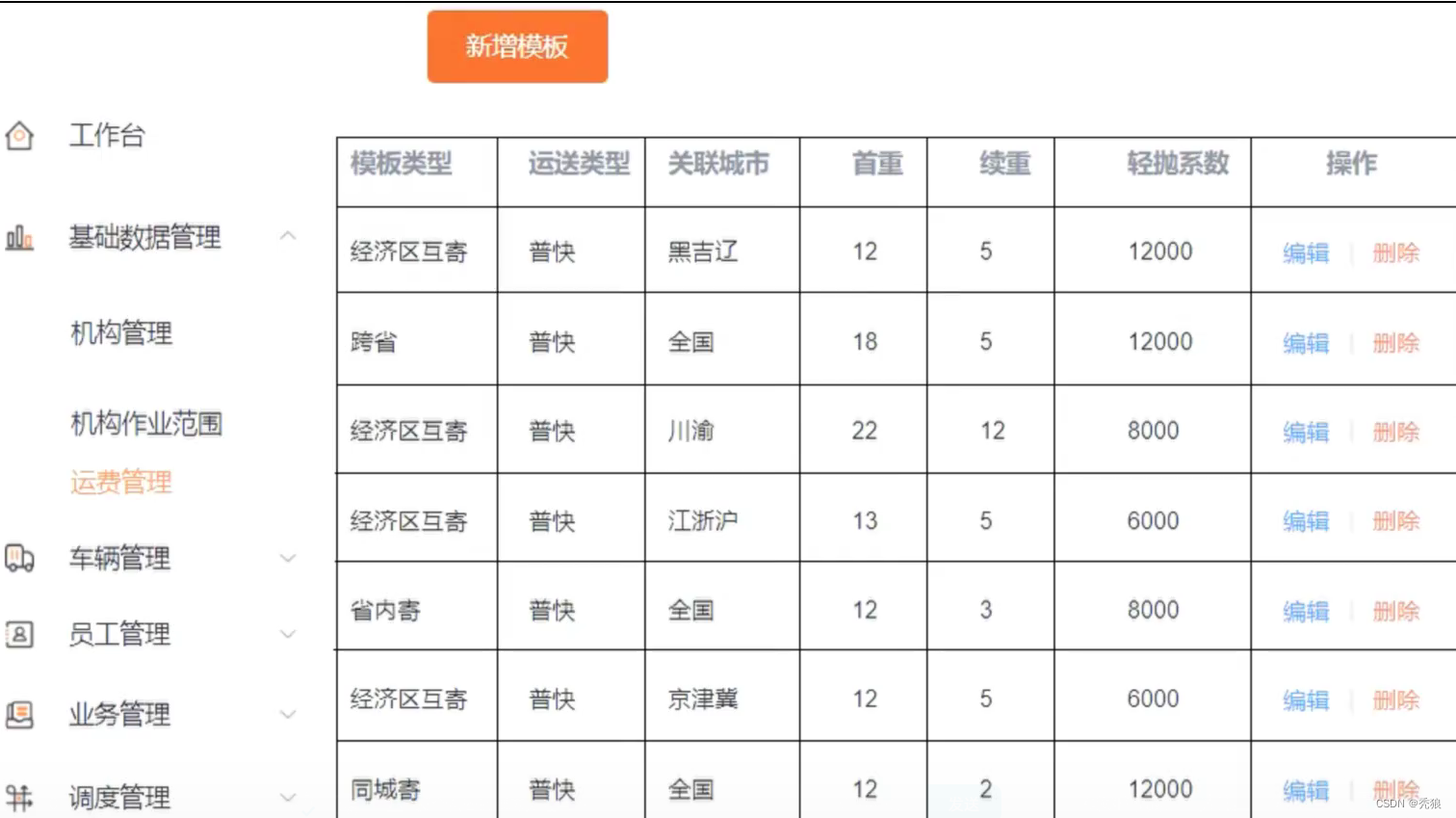
我负责的主要就是运费模板和运费计算的实现,给您分别介绍一下这两个功能点吧。
主要就是根据运费模板(这个会存放在运费模板表中)类来计算的,您可以运费模板当做一种寄件规则,运费模板包括:同城寄,省内寄,经济区互寄(京津冀,江浙沪,川渝),省外寄。根据运营根据不同的情况,计算出的不同的首重价格和续重价格。包括模板的curd也是我完成的,这里需要注意的就是在模板具有唯一性,就比如在插入经济区互寄的时候,我们还需要判断关联的城市的集合是否已经存在,否则无法进行插入操作。保证同一个快递只有一种寄件规则。
根据用户选择的区级id调用基础微服务,查询当前区域的信息,主要的就是其对应的父id及父父id,调用运费微服务从同城寄到省外寄类型的顺序依次进行判断。在计算出模板后,我们会使用体积(通过前端的长宽高进行计算)除以轻抛系数计算出最终的重量,取该值和重量更大的值作为最终重量。这里我们还设定了一系列的重量规则:当重量<1的时候就直接使用1作为重量,当重量 1<&&<10的时候四舍五入保留一位小数进行计算,当10<&&<100的时候,保留一位小数,小数部分小于0.5就按0.5,大于0.5就直接进1,当重量>100的时候直接舍弃小数部分的数据。最终通过(重量 -1)*续重 价格+ 首重价格计算出费用,返回给前端。

问:路线规划模块是怎么设计的呢?
在我们做技术选型的时候呢,我们先是想到使用mysql进行网点之间的关系,但是呢这就会导致需要多张表,以及在查询最短路径的时候呢,需要大量的做联表的操作,在效率上及后续表的维护上是非常麻烦的。因此我们就使用图型话数据库neo4j,它的结构非常适合做路线的规划,节点表示网点,关系表示两个网点的距离,属性存储网点的id,标签存储网点的类型,类型主要就是用来计算成本的,类型主要就是三种。一级转运中心,二级转运中心,基础网点。这个标签主要就是做成本的计算的,一级转运中心到一级转运中心为支线,一级转运中心到二级转运中心为干线,二级转运中心到基础网点为接驳路线,对应的路线的成本都是由运营进行控制的。在调度中心会做订单转运单的操作,此时需要计算两点的最短路径就是使用ShortPaths进行计算的,我们会将结果集合存到在运单表的字段中,后续修改当前及下一网点会持续使用到。我们的司机主要就是在两个网点之间的来回运输,所以在创建两点关系的时候会同时设置往返关系,对了,因为网点的信息是固定的,就好比身份证的家庭住址,所以在neo4j中网点的信息和关系是不能进行修改的,如果需要做修改的操作的话,我们需要先进行删除操作再做新增的操作。
问:介绍一下调度微服务吧?(在项目中遇到的难点?业务流程就是难点)
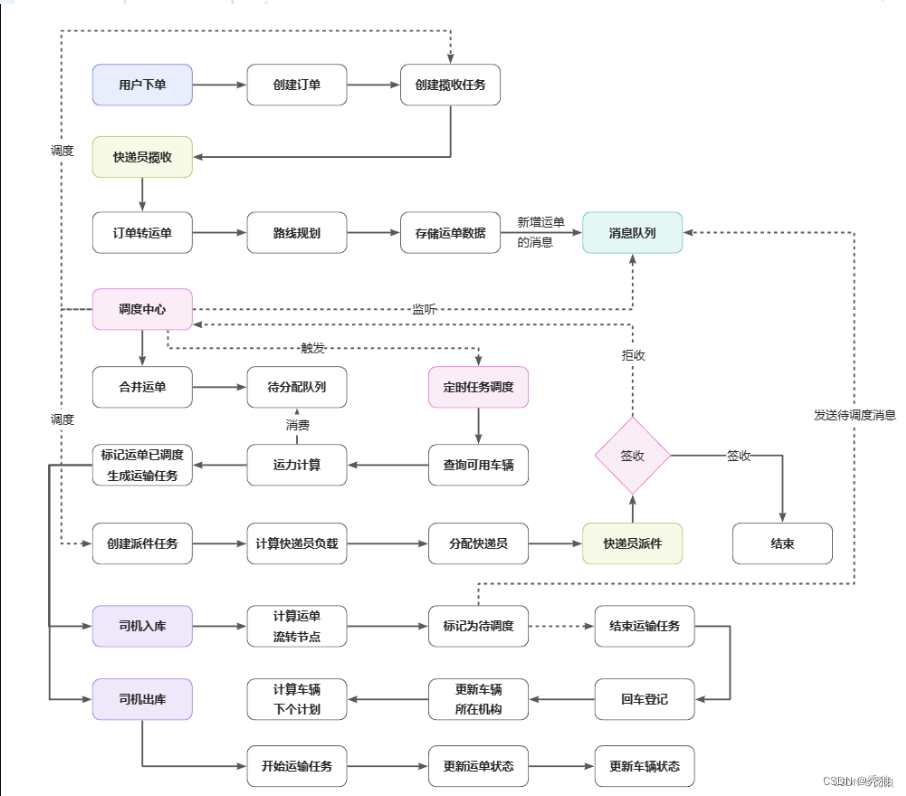
这个模块是物流微服务中最重要的就是调度微服务。其中主要就是包含订单转运单,运单合并,计算运力,司机出入库,快递员派件等流程。那我就按执行流程给您介绍一下调度微服务模块,您看行吗?
订单转运单
在交易单完成支付后就会发送消息到调度中心让运单微服务执行订单转运单的方法,订单的id是使用雪花算法生成的,但是呢雪花算法依赖于时间戳,因为有重复的风险且我们的运单号要求的个数为俩位字母+16为数字,所以我们使用美团leaf来生成id,使用其的号段模式来实现的,也就是会提前从数据库中取一定数量的id作为号段减少db操作。但是呢这个模式存在尖刺问题也就是在获取号段的时候效率一下就低了,我们可以使用它的另一个模式双buffer模式来解决。对应的运单表主要的字段就是运单id,运单状态(默认为待调度),当前网点,下一网点,及最短路径信息。在创建运单后判断当前网点和下一网点是否相同,如果相同向调度中心发送带派送任务消息,否则发送运单信息到调度中心。
运单合并
如果我们在每次车次要发车前直接取运单中查询并做装车的操作,那效率是非常低的且存在幂等性的问题。我们的设计是这样的,使用redis的list和set结构进行存储,list作为运单待消费队列,使用运单当前网点id和下一网点id拼接做为key,vlaue就是存储对应运单id集合。在运单生成后就会发送消息到调度执行执行运单合并的操作,通过运单对应的消息存储到对应的list中,为了防止运单在计算运力的时候被重复消费,就是使用set解决幂等性的问题,结构类似list。并且将运单状态设置为等待。
在调度中心中会使用xxl-job做定时任务,每隔五分钟会从到基础微服务中查询当前两个小时内会发车的车次做运力计算的操作。车次表主要就是起点和终点id,司机id,车次状态(默认为未完成),装载状态,可装载重量,当前装载重量。一般车次的数量在几百,所以只使用一个调度微服务节点来做运力计算明显是不合适的,我们在部署的时候会部署多个调度服务节点搭建集群,所以在xxl-job的策略上我们使用分片广播,主要就是按车次id做取模的操作,达到负载均衡的效果。按照车次起始和终点id找到对应集合消费运单id进行运力的计算也就是装车。这边需要注意的就是运单可能会出现车次重复消费的问题,所以会创建可重入锁,这里主要就是使用redisson来实现的,我们使用递归的方法计算出运载的运单id集合及车次的装载重量,通过批量插入操作修改车次运单关系表(多对多的关系)。我们规定80%为装满,5%内为空车,当然即使没有转载司机需要进行运输。及发送消息实现批量的修改运单的状态为运输中。最终发送消息到调度中心执行司机的出库操作。
这些车次的司机匹配都是运营设置好的,在完成完成运力计算后,此时对应的司机就有新的任务,当然我们需要使用基础微服务存储司机任务的信息,将信息封装为对象,主要的属性就是司机id,车次id,车牌,起始就终点信息。存储消息表中,便于获取司机在app查看任务。那这里我们在设计表的时候还添加了一个以已读状态的字段,用于后续展示未读消息数。
根据时间的推移,数据量明显是非常庞大的,在查询的时候就会存在一定的压力,所以我们还会对用户id建立索引的操作及使用redis来缓存每一个活跃用户的站内消息,使用定时任务同步到数据库(实现批量操作)。另外呢,我们也考虑到数据表的数据量增长,我们在后续优化的时候会使用shardingShpere JDBC来实现水平分表的操作。
这个就是我负责生成司机任务的大概流程。
司机出入库
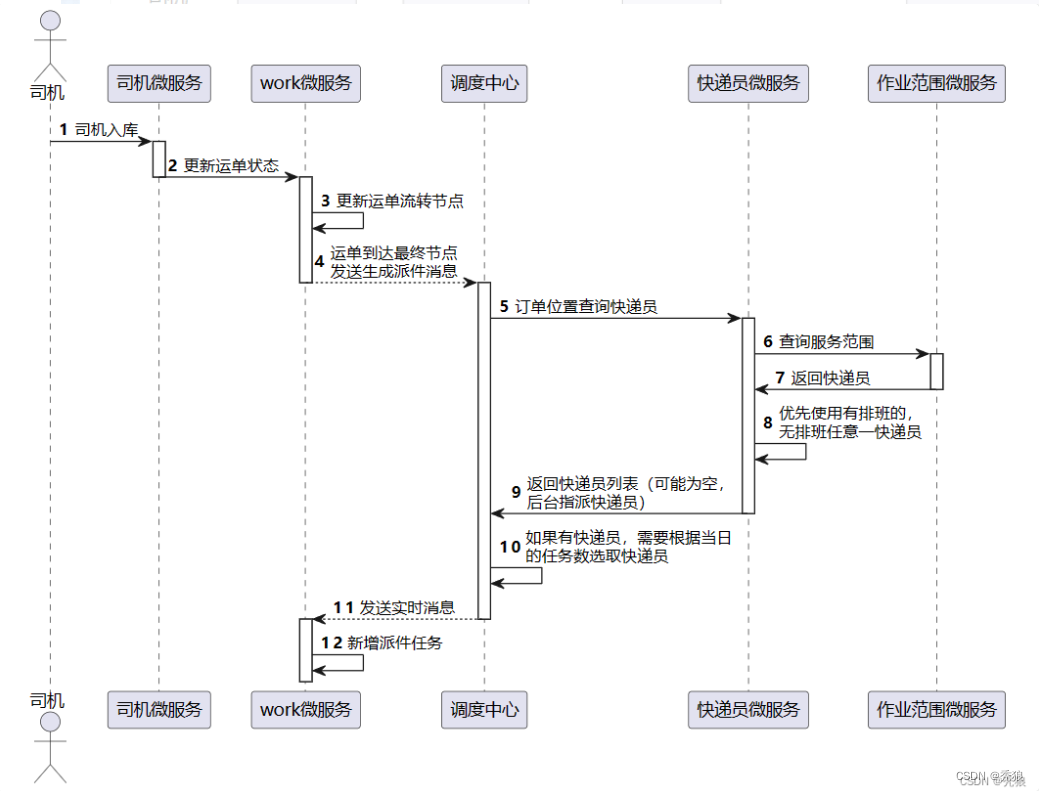
司机按照对应的时间进行出库的操作并且每个司机运输的路线基本是规定的,司机在做发车前需要拍照提交触发出库流程(将照片消息存储到车次表中),在司机运输完成之后就会做入库的操作。此时修改车次的状态并修改每个运单的当前网点和下一网点通过存储的最短路径集合进行修改,如果当前网点和下一网点相同的话,发送派送消息到调度中心,否则发送运单信息到调度中心继续做一系列的调度操作。
问:快递员负责的派送范围怎么设计的呢?
这里呢,我们没有使用传统的mysql进行存储,因为服务范围是一个坐标集合,会存储大量的数据,判断交集的时候也很麻烦,因此我们使用Mongdb进行存储,Mongdb的polygons属性可以存储坐标集合,且在判断坐标点负责网点及快递员的时候可以使用intersects计算交集。并且呢快递员和网点的关系是这样的,一个网点中可能存在多个快递员,快递员又负责该网点服务范围中的子范围。(其他就是一些增删改查,通过Spring Data Mongdb进行整合)
快递员的派送及派送
快递员的取件主要就是在用户下单的时候通过调度中心进行调度的,而快递员的派送呢,它是在订单转运单及车辆入库是当前网点和下一网点相同的时候通过调度中心进行调度的。调用基础微服务,查询当网点又排班的快递员集合(对应基础微服务中快递员排班表),因为快递员的服务范围使用Mongdb进行存储的,直接调用intersect方法,查询出对应的快递员基本,最终选择任务量少的快递员。这边主要就是要考虑如果没有符合服务范围的快递员就从有排班的快递员中选择。如果没有排班的话,就直接返回空的结果,后续直接走人工判断。
调用快递员微服务,发送对应的任务消息给快递员端,对应一个任务表,主要的字段:快递员id,运单id,任务类型,派送状态,签收状态等等,为了提高用户的体验,我们在设计上要求消息要在快递员进行派送取件前两小时,我们通过调度中心发送消息到快递员微服务(work)生成快递员任务。如果派送时间小于两小时的话直接发送消息,如果大于两个小时的话就使用延迟队列发送一个延迟消息(主要使用死性队列来实现延迟对列的),完成派送后用户进行签收并修改运单的状态及派送任务的状态。
当然我们还需要考虑快递员无法派送的问题,就比如当前快递员因为其他的原因无法派送,我们需要修改基础微服务中快递员的排班表移除当前快递员的排班及对应的任务信息,重新发送对应的快递员派送消息,重新将任务分配给其他的快递员的派送任务,最终完成派送任务。
问 :如果用户拒收的话,是怎么处理的呢?
如果用户进行拒收的话,那就需要快递进行原路返回,此时需要调换运单的起点和终点,重新计算对应的最短路径,判断当前及下一网点是否相同,相同发送对应的派送信息,反之发送调度消息。
问:Redisson的底层实现方式有了解过吗?
我是有看过Redisson的实现方式。Redisson实现的分布式锁它的特点就是:支持锁的重入性,支持锁ttl重置机制,支持堵塞重试机制。
- 支持锁的重入性:基于redis的hash结构实现的,大key存储上锁的字段,小key存储线程的id,value存储锁重入的次数。
- 支持ttl重置机制:底层主要就是基于Watch Dog来实现的,当创建锁的时候没有设置过期时间就会触发ttl重置机制,Watch Dog的底层是一个定时任务,每隔30秒就会重新设置锁的过期时间。
- 支持堵塞重试机制:基于redis的发布与订阅模式实现的,当一个线程获取锁失败的时候就会去订阅一个频道,获取锁成功并且解锁后的线程会向频道手动发送对应的获取锁消息,然后失败的线程就会重新获取锁。
问:那你们物流信息模块是怎么设计的呢?
这个模块主要就是展示运单的运输信息,算是用户访问较频繁的模块。它的格式一个集合列表也就是每到一个网点就会记录一条信息,那使用mysql的话就会存在大量的记录,随着时间的推移,数据的堆积就会导致查询效率降低,所以我们使用Mongdb来进行存储,使用它的嵌套document经过进行存储的,每一个运单对应一个document记录。在刚开始的时候,我们就直接读取数据库,没有做然后的缓存操作,但是呢,我们后来考虑到了并发的场景(业务要求能抗住1万的qps),所以我们就添加了缓存的操作,并且采用二级缓存方案。
但是呢,不能完全依赖软件,说实话,即使是在牛逼的技术选型也离不开底层硬件的资源,无论是内存,宽带,还是cpu的处理速度,我们都应该进行综合的考虑。
我们的一级缓存主要就是通过 Nginx + Lua + redis来实现的,当请求到达Nginx后,会通过Lua先到redis中查询缓存,降低Tomcat的压力。如果没有缓存的话Nginx就会将请求放到后面,在每个tomcat中使用Caffeine作为二级缓存。如果在Caffeine中还是没有查询到缓存的话,这时候就会查询Mongdb,并将返回值做缓存。并且呢两个缓存都会设置对应的缓存淘汰策略,避免一些很久的运单一直被缓存浪费内存。
但是呢,在做缓存的时候我们遇到了一些问题,包括缓存数据一致性,缓存穿透,缓存雪崩。我给您介绍一下我们对这些方法的处理方案,您看行吗?(不讲的话,面试官会直接问你。自己引导的话,直接回答答案即可)

问:缓存一致性是怎么做的呢?
redis缓存我们主要就是使用springCache来实现的,通过对应的注解实现在查询时做缓存,在写操作时清除缓存。
Caffeine的话,因为它是基于一个jvm的,所以服务节点在做清除缓存的时候不能只清除当前节点的缓存,这样会导致缓存不一致问题。我们的解决方案就是使用redis的发布与订阅模式来解决,我们让服务去订阅自定义的频道,每次需要清除缓存的时候就会向该频道发送消息,最终保证集群中每个节点缓存的一致性。
问:缓存穿透和缓存雪崩是怎么解决的呢?
缓存穿透主要就是因为大量访问缓存及数据库中不存在的数据导致压垮数据库。解决方案就是使用布隆过滤器(通过redisson来实现的),对存在的数据在布隆过滤器中做标记,过滤不存在数据,防止恶意攻击。
缓存雪崩问题主要就是因为大量的key设置了相同的过期时间在一定时间内同时过期,大量的访问db,最终压垮数据库(也可能是redis宕机,这时候久搭建redis集群)。我们项目中会将物流轨迹信息的缓存的ttl设置为3天,在每次更新物流信息的时候都会重新设置ttl,主要就是清除缓存,读取的时候直接重新设置缓存。这样既可以防止缓存穿透,又可以在运单结束一段时间后,清除对应缓存,减少了内存的消耗。
问:模块是怎么设计的呢?(应届生不要讲,坑多)
项目中用户主要就是在微信小程序端进行登录的,在用户点击授权登录后,前端后从微信接口中获取两个临时的code,分别是用户基础信息code,手机号code。请求携带两个code去访问后端服务,在请求到达网关是会又一个自定义过滤器,主要九四判断是否已经登录,因为后续的服务中包括查询订单,预约收件都需要用户先进行登录。当然我们会配置一个properties文件编写需要排除的路径,我们直接对登录请求放行,请求中主要就是携带 code码,appid密钥,appId。我们通过调用微信接口查询出openId,根据openId到基础微服务中查询该用户,如果没有查询到的话,说明为第一次登录,通过微信接口进行手机号,创建新的用户信息。通过不是新的用户的话,我们还要判断手机号是否修改,如果修改就修改用户信息。
在获取到userId后呢,我们会使用Jwt生成长短token及openId,绑定手机号的状态(不变或更换)返回给前端,以后使用短token进行进行校验,长token进行刷新。后续前端会将token存放到本地,在后续请求的时候,会将token放在请求头中的Authentication中,最终进行token的校验。这里使用的长短token,是一种双token三认证的模型实现,我给您介绍一下该模型的执行流程,您看行吗?
我们认证模型中,会存在长短token,也就是两个token,短token用来进行检验的,长token用来生成新的长短token。规则上长token只能使用一次,所以我们会将长token存储到redis中。主要就是基于SpringSecurity + jwt来实现的。jwt的生成需要的配置参数主要就是 数据体,密钥,对应的加密算法。
在请求进入gateway中会进行过滤器中做校验(通过jwt解析token),先去校验短token的有效性,如果有效就直接放,这个过程就是第一次校验。如果校验失败,就会去校验长token的有效性,这个是第二次校验。在保证了长token的有效性后,会去redis中判断该长token是否被使用过,也就是判断在redis中是否存在。(使用String类型进行存储),在第三次三次校验成功后生成新的长短token,并删除旧token插入新token,完成最终的校验。

问:这个模型有什么优势呢?
这里结合自己的理解去答,当token的缺点就是它的优点。就比如:合理的控制token的ttl,反之非法用户获取到token等等。
问:在实习的时候做个日志吗?(面试官没问,不要主动讲,怕问一些乱七八糟的问题)
项目组中主要使用GrayLog和Skywalking来做日志和链路追踪的。GrayLog主要即就是将微服务中碎片化的日志都整合到一起进行统一的查看。我们可以在GrayLog的仪表盘中进行快速定位检索,通过关键值或异常类的名字快速分析生产环境中反馈的各种问题。Skywalking也是通过仪表盘进行操作的,不部署也比较简单,要自准备探针和ES,通过java agent配置对应的探针,主要就是展示接口的调用速度,以及异常日志等信息,还有一个我觉得比较好用的功能,也就是服务拓扑图,可以展示服务间的调用情况,可以帮助程序员理解业务。