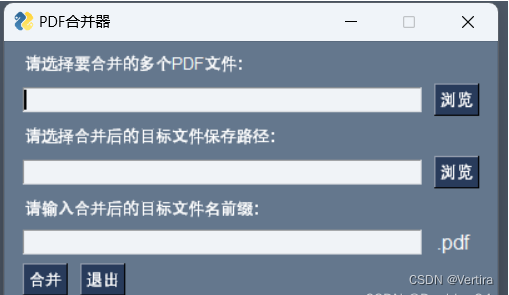
在Python中,可以使用PyPDF2库来合并PDF文件。以下是一个简单的脚本,它将指定文件夹下的所有PDF文件合并成一个PDF文件,并使用文件夹的名字进行命名:
首先,确保你已经安装了PyPDF2库。如果没有安装,可以通过以下命令安装:
pip install PyPDF2
然后,你可以使用以下脚本来合并PDF文件:
import os
from PyPDF2 import PdfMerger
def merge_pdfs_in_folder(folder_path, output_filename):
# 获取文件夹下所有的PDF文件
pdf_files = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if f.endswith('.pdf')]
# 按照文件名排序,确保合并的顺序
pdf_files.sort()
# 初始化PDF合并器
merger = PdfMerger()
# 添加所有的PDF文件到合并器中
for pdf_file in pdf_files:
merger.append(pdf_file)
# 合并PDF并保存到指定的文件中
merger.write(output_filename)
merger.close()
# 打印完成信息
print(f'PDF files have been merged into {output_filename}')
# 设置文件夹路径和输出文件名
folder_path = 'path_to_your_folder' # 替换为你的文件夹路径
output_filename = os.path.join(folder_path, os.path.basename(folder_path) + '.pdf') # 使用文件夹名字命名输出文件
# 调用函数合并PDF文件
merge_pdfs_in_folder(folder_path, output_filename)请确保将folder_path变量替换为你的PDF文件所在的文件夹路径。
这个脚本首先会找到指定文件夹下所有的PDF文件,然后按照文件名的自然顺序对它们进行排序,以确保合并时的顺序是正确的。接着,它使用PdfMerger对象来合并这些文件,并将合并后的PDF保存为指定的输出文件名。
注意:PyPDF2库在处理某些PDF文件时可能会遇到问题,特别是那些使用了高级压缩或加密的PDF。如果遇到问题,你可能需要寻找其他的PDF处理库,如pdfrw或PyMuPDF。