INFO-LSTM-SelfAttention是一种用于回归预测的神经网络模型,结合了长短期记忆(LSTM)神经网络、自注意力机制和向量加权平均算法。下面详细介绍这个模型在回归预测任务中的工作流程:
1. 数据预处理
输入数据:时序数据序列,如股票价格、气象数据等。
数据归一化:对输入数据进行归一化处理,以加速模型训练并提高模型的稳定性。
2. 构建模型结构
LSTM层:接受输入数据序列,并学习序列中的长期依赖关系。
自注意力层:在LSTM层之后引入自注意力机制,以捕捉序列中不同部分的重要性。
向量加权平均层:根据自注意力层的输出和向量加权平均算法,动态地调整每个特征的权重。
全连接层:将向量加权平均层的输出传递到全连接层,进行回归预测。
3. 训练模型
利用训练数据对模型进行训练,通过反向传播算法优化模型参数。
使用验证集监控模型的性能,并根据验证集的表现进行调整,以防止过拟合。
4. 模型预测
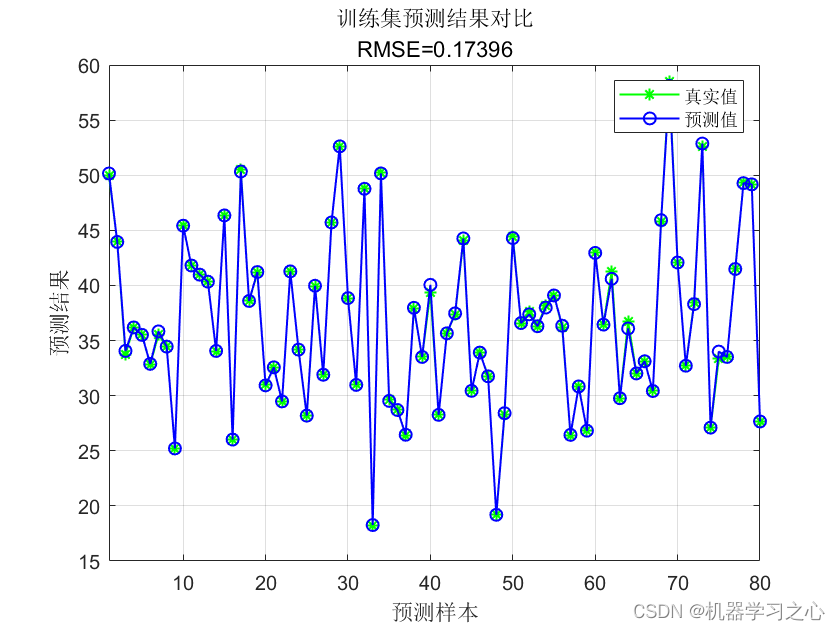
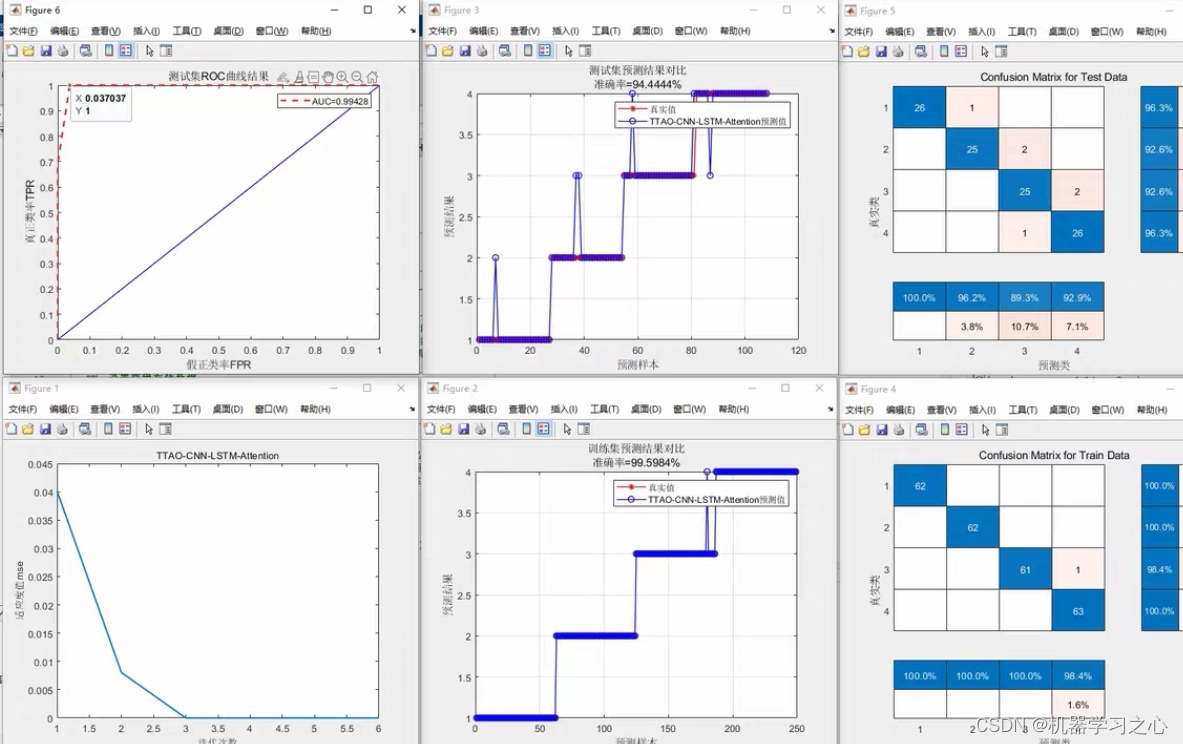
使用训练好的模型对测试数据进行预测,得到回归结果。
5. 向量加权平均算法优化
在训练过程中,利用向量加权平均算法动态地调整模型的超参数,如L2正则化参数和初始学习率,以优化模型性能。
根据模型在不同超参数组合下的历史表现,计算每个超参数组合的权重,并更新超参数的选择。
优势
有效利用时序信息:通过LSTM层,模型能够捕捉时序数据中的长期依赖关系。
关注重要信息:引入自注意力机制和向量加权平均算法,使模型能够动态地关注序列中的重要部分,提高了预测的准确性。
自适应调整超参数:利用向量加权平均算法优化超参数选择,使模型更好地适应不同数据集和问题的特点。
应用
INFO-LSTM-SelfAttention模型适用于各种回归预测任务,如股票价格预测、气象数据预测、交通流量预测等。它在处理时序数据时具有优秀的性能,并且能够灵活地适应不同的应用场景。
程序部分源代码:
%% 清空环境变量
clc;
clear;
close all;
warning off;
tic
%% 导入数据
load testdata.mat
percent = 0.7;
num_samples = size(X, 2);
num_train = round(num_samples*percent);
L = size(X,1);
P_train = X(1:L,1:num_train);
T_train = Y(1:num_train);
M = size(P_train,2);
P_test = X(1:L,num_train+1:end);
T_test = Y(num_train+1:end);
N = size(P_test,2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
%将数据平铺成1维数据只是一种处理方式
%也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
%但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, L, 1, 1, M));
p_test = double(reshape(p_test , L, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test )';
%% 数据格式转换
for i = 1 : M
Lp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : N
Lp_test{i, 1} = p_test( :, :, 1, i);
end
%% INFO优化
SearchAgents = 25; % 种群数量 25
Max_iterations = 5; % 迭代次数 30
lowerbound = [1e-5 1e-5]; %三个参数的下限
upperbound = [1e-1 1e-1]; %三个参数的上限
dim = 2; %数量,即要优化的LSTM超参数个数
fobj = @(x)fun(x,Lp_train,t_train,Lp_test,t_test,L);
[Best_score,Best_pos,Convergence_curve] = INFO (SearchAgents,Max_iterations,lowerbound,upperbound,dim,fobj);




**
完整源代码:INFO-LSTM-SelfAttention(https://mbd.pub/o/bread/ZpWVlJhq)
**