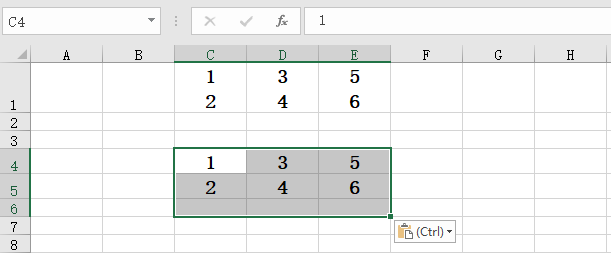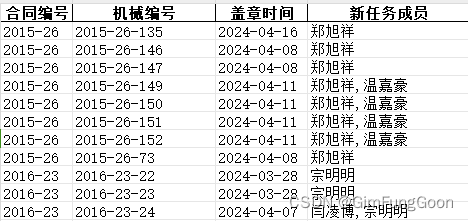
让“新任务成员”列的每行每个人名分列,都有单独的行,和对应的合同编号、机械编号、盖章时间,各自形成一列
import pandas as pd
# 假设你的数据是存储在一个名为df的DataFrame中
# 如果不是,你可以使用下面的代码从CSV或其他格式的文件中读取数据
# df = pd.read_csv('your_file.csv')
# 示例数据
data = {
'合同编号': ['2015-26', '2015-26', '2015-26', '2015-26', '2015-26', '2015-26', '2016-23', '2016-23', '2016-23'],
'机械编号': ['2015-26-135', '2015-26-146', '2015-26-147', '2015-26-149', '2015-26-150', '2015-26-151', '2016-23-22', '2016-23-23', '2016-23-24'],
'盖章时间': ['2024-04-16', '2024-04-08', '2024-04-08', '2024-04-11', '2024-04-11', '2024-04-11', '2024-03-28', '2024-03-28', '2024-04-07'],
'新任务成员': ['郑旭祥', '郑旭祥', '郑旭祥', '郑旭祥,温嘉豪', '郑旭祥,温嘉豪', '郑旭祥,温嘉豪', '宗明明', '宗明明', '闫凌博,宗明明']
}
df = pd.DataFrame(data)
# 定义一个函数来拆分人名
def split_members(members):
return members.split(',')
# 应用函数到“新任务成员”列,并使用explode来拆分
df['新任务成员'] = df['新任务成员'].apply(split_members)
df_expanded = df.explode('新任务成员')
# 重置索引
df_expanded = df_expanded.reset_index(drop=True)
# 显示结果
print(df_expanded)
# 如果需要,可以将结果保存到CSV文件
# df_expanded.to_csv('expanded_data.csv', index=False)结果:

在这个例子中,我们首先定义了一个函数split_members,它接受一个字符串参数(即“新任务成员”列中的一个条目),并返回一个由逗号分隔的字符串列表。然后,我们使用apply函数将这个函数应用到“新任务成员”列的每个元素上。接着,我们使用explode函数来拆分这个列,生成包含每个人名的单独行。最后,我们使用reset_index函数来重置索引,以便新生成的DataFrame具有连续的索引。
请注意,如果你的数据是从CSV或其他格式的文件中读取的,你需要使用pd.read_csv或其他相应的函数来读取数据,而不是像示例中那样直接创建DataFrame。此外,如果你的“新任务成员”列中的字符串是用其他字符(如空格或分号)分隔的,你需要相应地调整split_members函数中的分隔符。