一、本期课程内容概述
本节课的主讲老师是【曹茂松、刘卓鑫】。教学内容主要包括以下三个部分:
1.大模型评测的背景
2.大模型评测工具OpenCompass的介绍
3.OpenCompass实战
二、学习收获
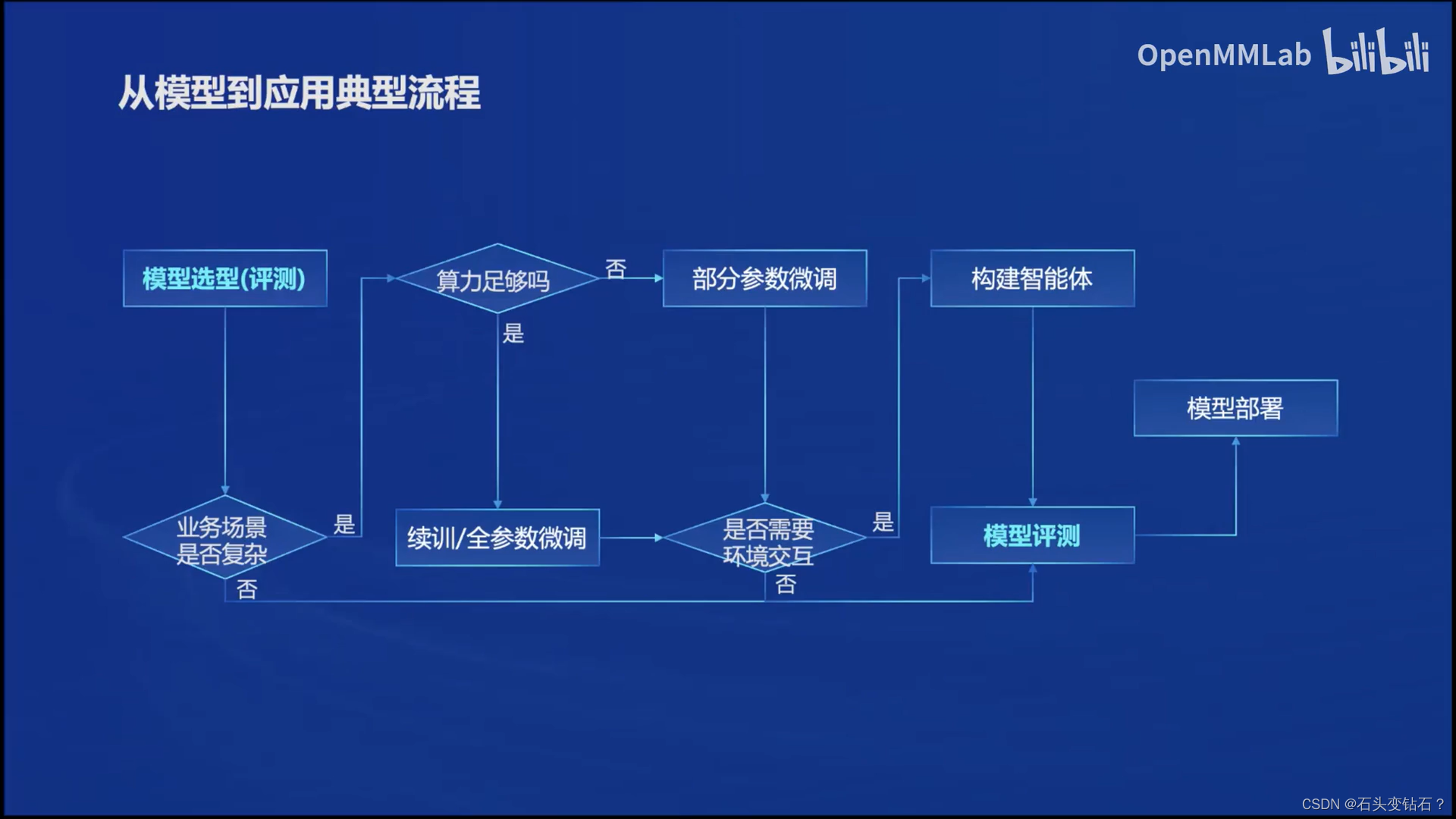
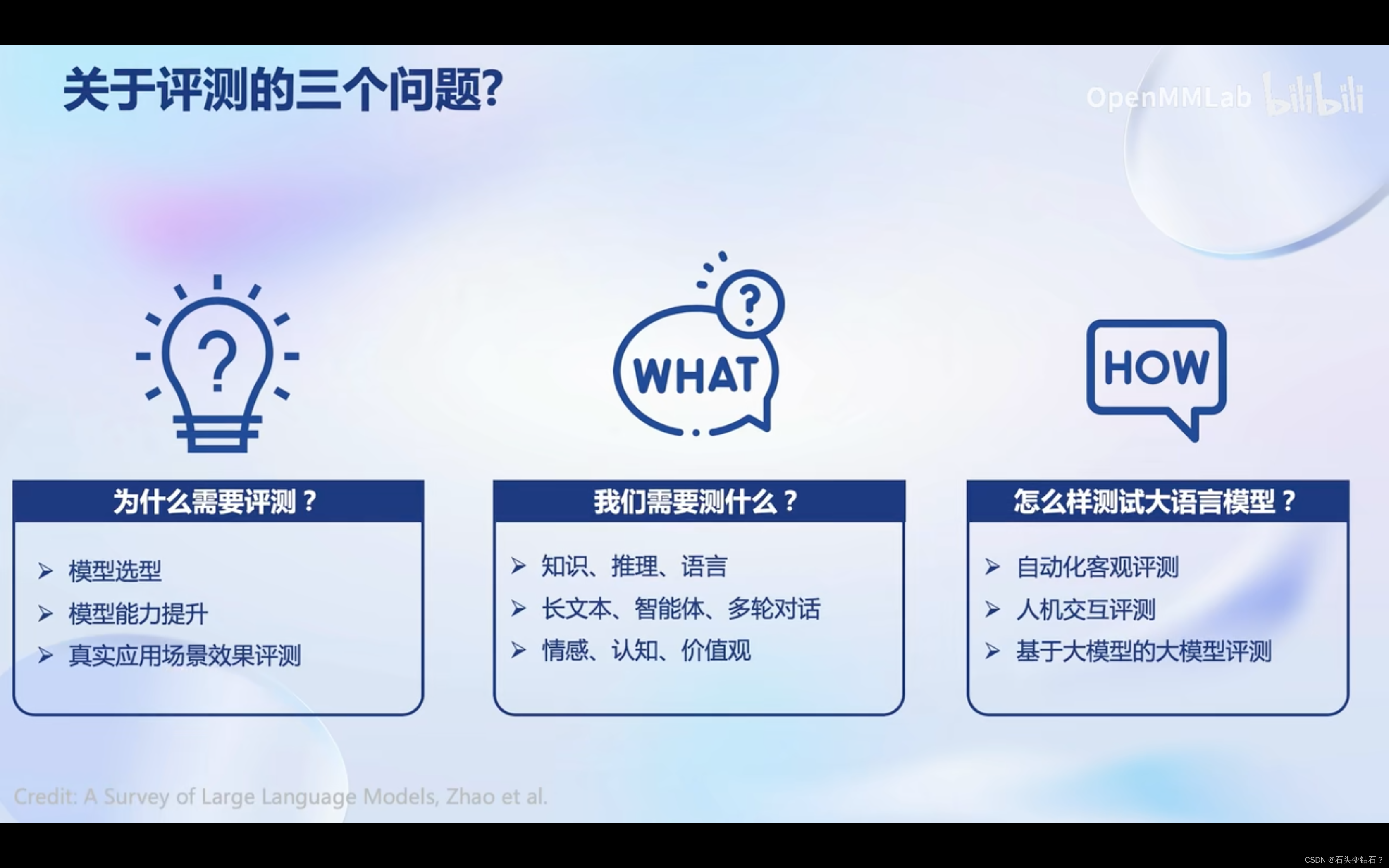
为什么要研究大模型的评测?
- 首先,研究评测对于我们全面了解大型语言模型的优势和限制至关重要。尽管许多研究表明大型语言模型在多个通用任务上已经达到或超越了人类水平,但仍然存在质疑,即这些模型的能力是否只是对训练数据的记忆而非真正的理解。例如,即使只提供LeetCode题目编号而不提供具体信息,大型语言模型也能够正确输出答案,这暗示着训练数据可能存在污染现象。
- 其次,研究评测有助于指导和改进人类与大型语言模型之间的协同交互。考虑到大型语言模型的最终服务对象是人类,为了更好地设计人机交互的新范式,我们有必要全面评估模型的各项能力。
- 最后,研究评测可以帮助我们更好地规划大型语言模型未来的发展,并预防未知和潜在的风险。随着大型语言模型的不断演进,其能力也在不断增强。通过合理科学的评测机制,我们能够从进化的角度评估模型的能力,并提前预测潜在的风险,这是至关重要的研究内容。
大模型评测中的挑战
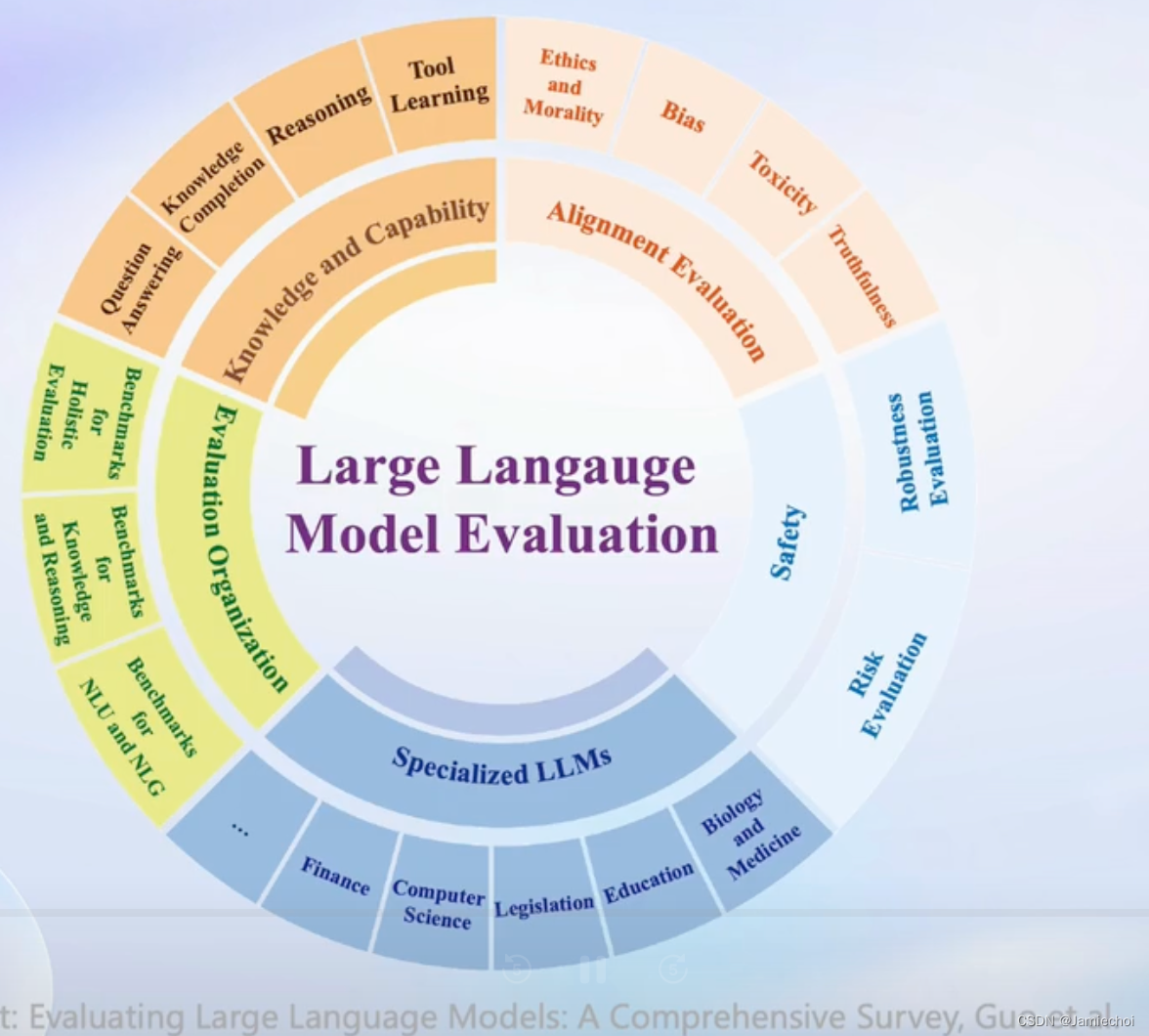
- 全面性:由于大语言模型应用场景的多样化和模型能力的迅速演进,如何设计和构造一个可扩展的能力维度体系是一个挑战。
- 评测成本:评测数十万道题使用本地模型需要大量的算力资源,调用API费用也不低。基于人工打分的主观评测成本高昂。
- 数据污染:在使用海量语料进行评测时,不可避免地会带来评测数据的污染。需可靠的检测技术来确保数据质量。
- 鲁棒性:大语言模型对提示词非常敏感,多次采样情况下模型性能不稳定。如何设计出具有高鲁棒性的评测方法是一个挑战。
OpenCompass介绍
上海人工智能实验室科学家团队正式发布了大模型开源开放评测体系 “司南” (OpenCompass2.0),用于为大语言模型、多模态模型等提供一站式评测服务。其主要特点如下:- 开源可复现:提供公平、公开、可复现的大模型评测方案
- 全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
- 丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
- 分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
- 多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
- 灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
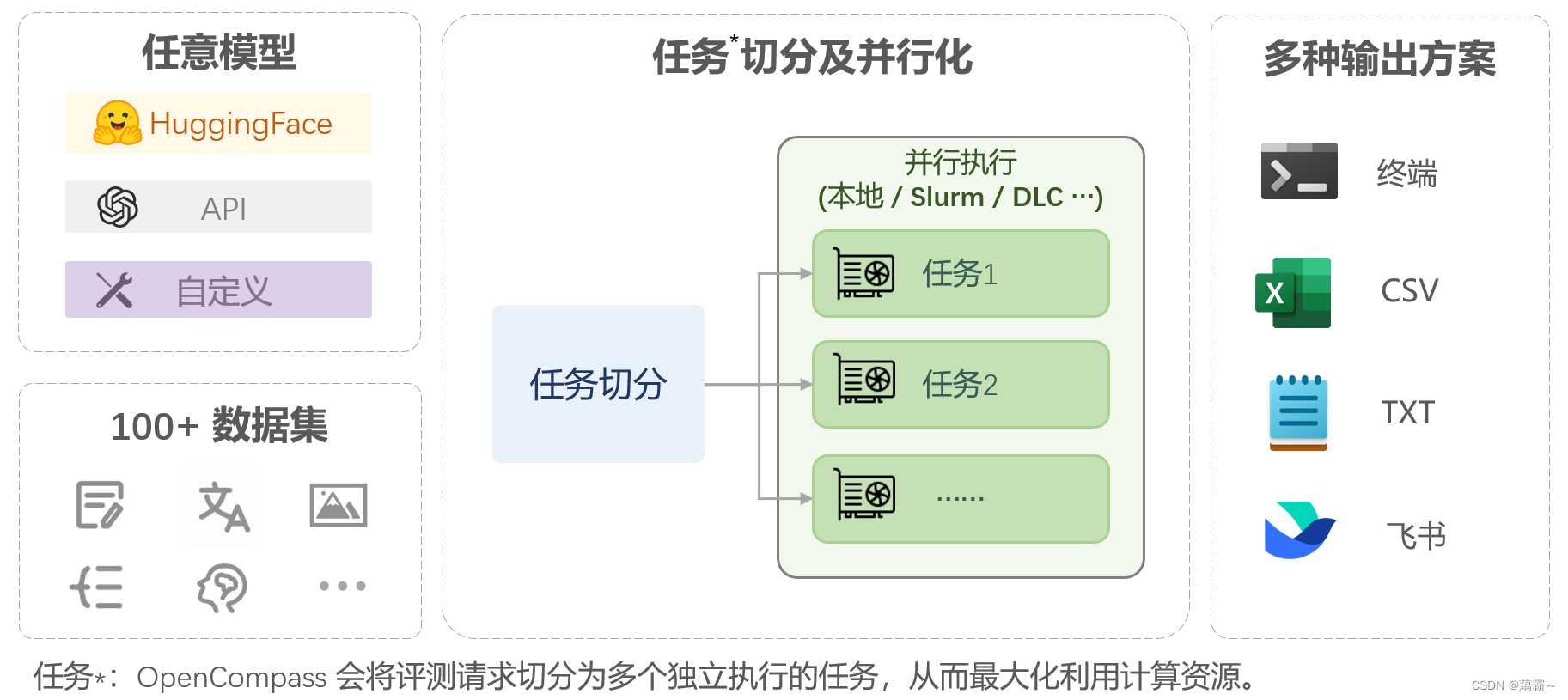
OpenCompass 三大核心模块
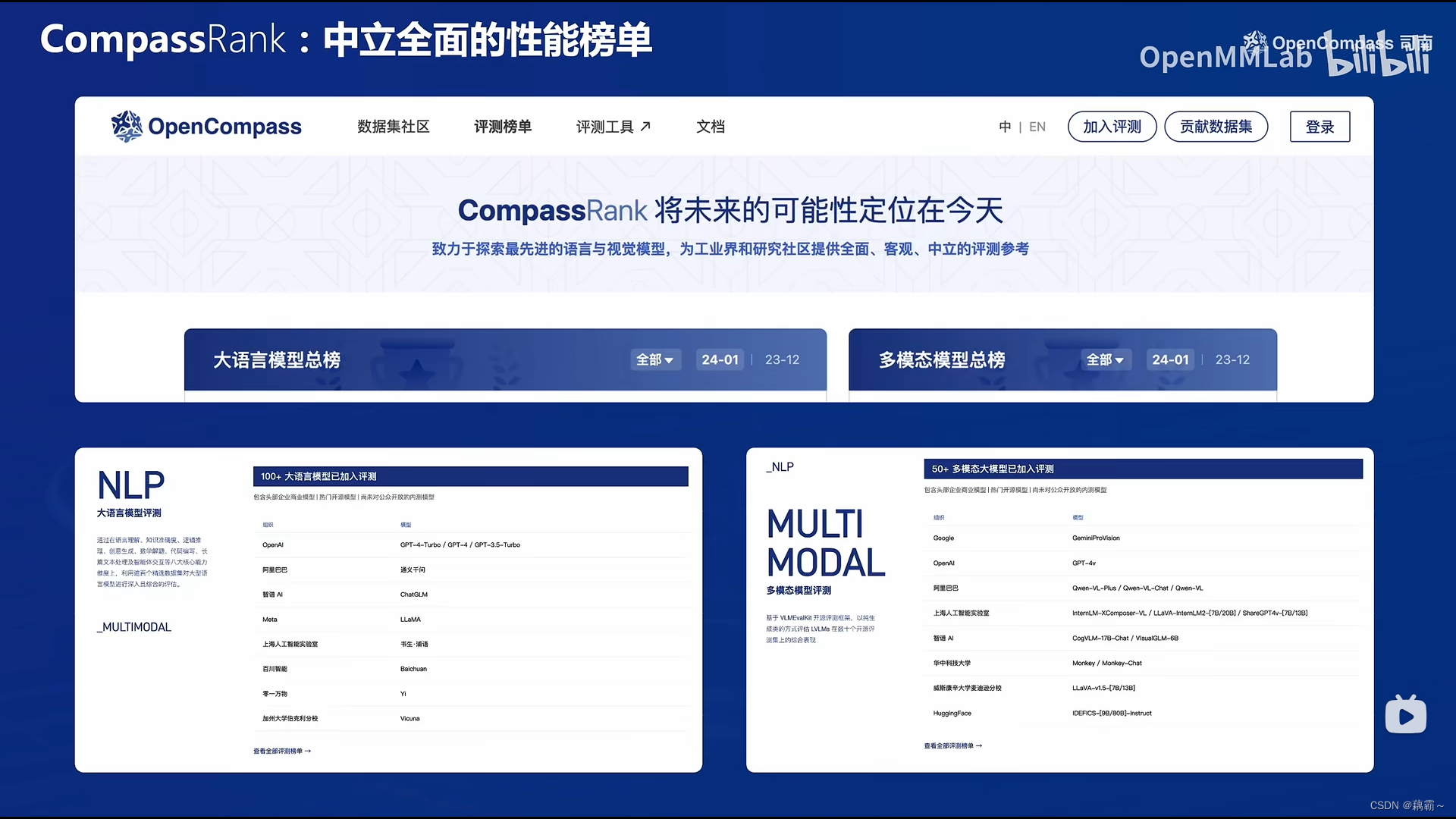
CompassRank 系统进行了重大革新与提升,现已成为一个兼容并蓄的排行榜体系,不仅囊括了开源基准测试项目,还包含了私有基准测试。此番升级极大地拓宽了对行业内各类模型进行全面而深入测评的可能性。
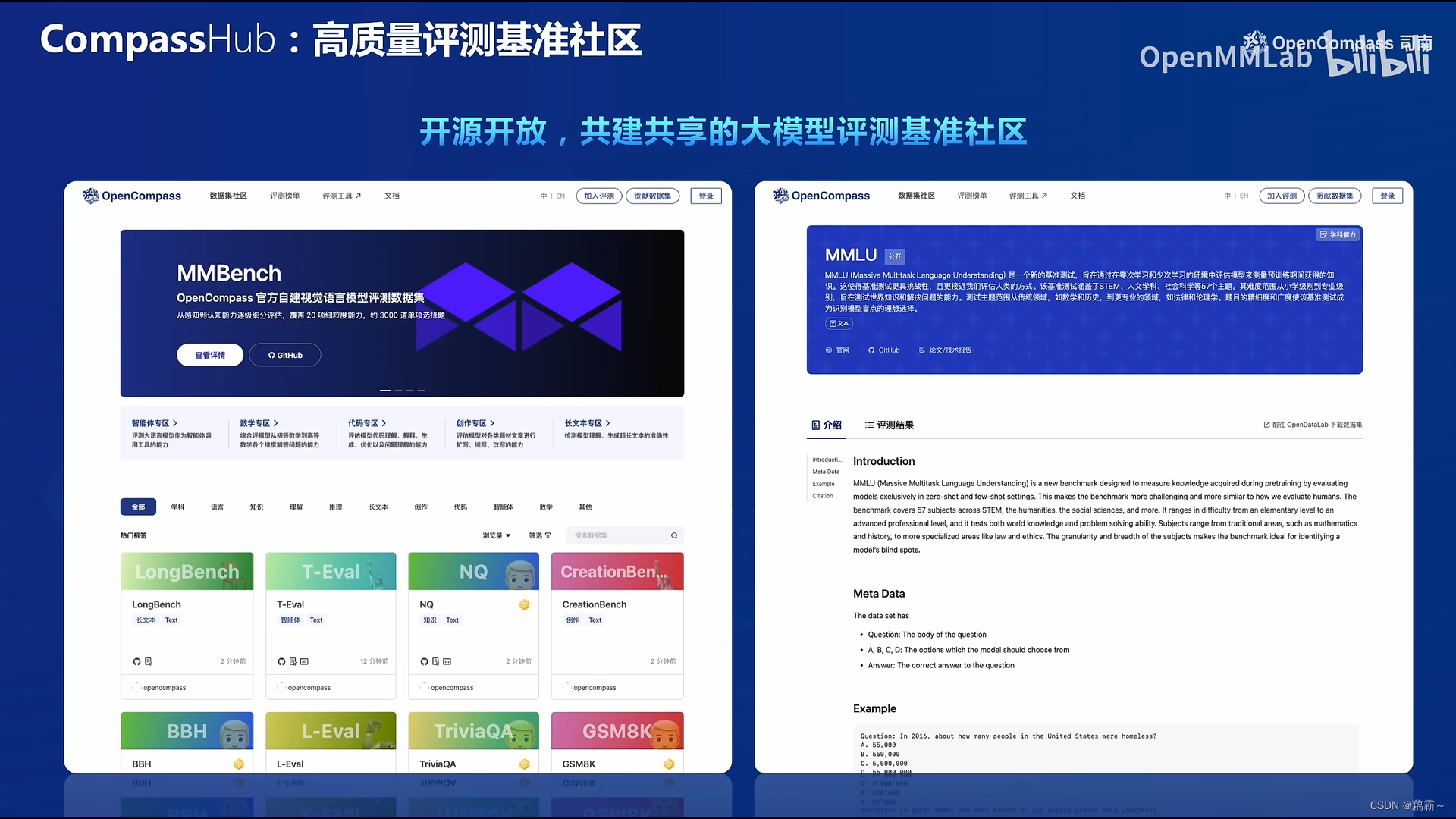
CompassHub 创新性地推出了一个基准测试资源导航平台,其设计初衷旨在简化和加快研究人员及行业从业者在多样化的基准测试库中进行搜索与利用的过程。
CompassKit 是一系列专为大型语言模型和大型视觉-语言模型打造的强大评估工具合集,它所提供的全面评测工具集能够有效地对这些复杂模型的功能性能进行精准测量和科学评估。

OpenCompass评测方法
OpenCompass 采取客观评测与主观评测相结合的方法。针对具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式的问题、模型安全问题等,采用主客观相结合的评测方式。- 客观评测:针对具有标准答案的客观问题,我们可以我们可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。同时,由于大语言模型输出自由度较高,在评测阶段,我们需要对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响,才能对模型的能力有更加完整和客观的评价。 为了更好地激发出模型在题目测试领域的能力,并引导模型按照一定的模板输出答案,OpenCompass 采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。
- 主观评测:语言表达生动精彩,变化丰富,大量的场景和能力无法凭借客观指标进行评测。针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的真实能力,并更符合大模型的实际使用场景。 OpenCompass 采取的主观评测方案是指借助受试者的主观判断对具有对话能力的大语言模型进行能力评测。在具体实践中,我们提前基于模型的能力维度构建主观测试问题集合,并将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。由于主观测试成本高昂,本方案同时也采用使用性能优异的大语言模拟人类进行主观打分。在实际评测中,本文将采用真实人类专家的主观评测与基于模型打分的主观评测相结合的方式开展模型能力评估。 在具体开展主观评测时,OpenComapss 采用单模型回复满意度统计和多模型满意度比较两种方式开展具体的评测工作。
三、个人体会
- 没想到评测还能够推动模型发展
- 也没有想到书生200K上下文竟然只是用在评测里的
- 榜单还是很有用的,方便我们挑选合适的模型
四、本期作业
https://blog.csdn.net/weixin_45609124/article/details/138141416