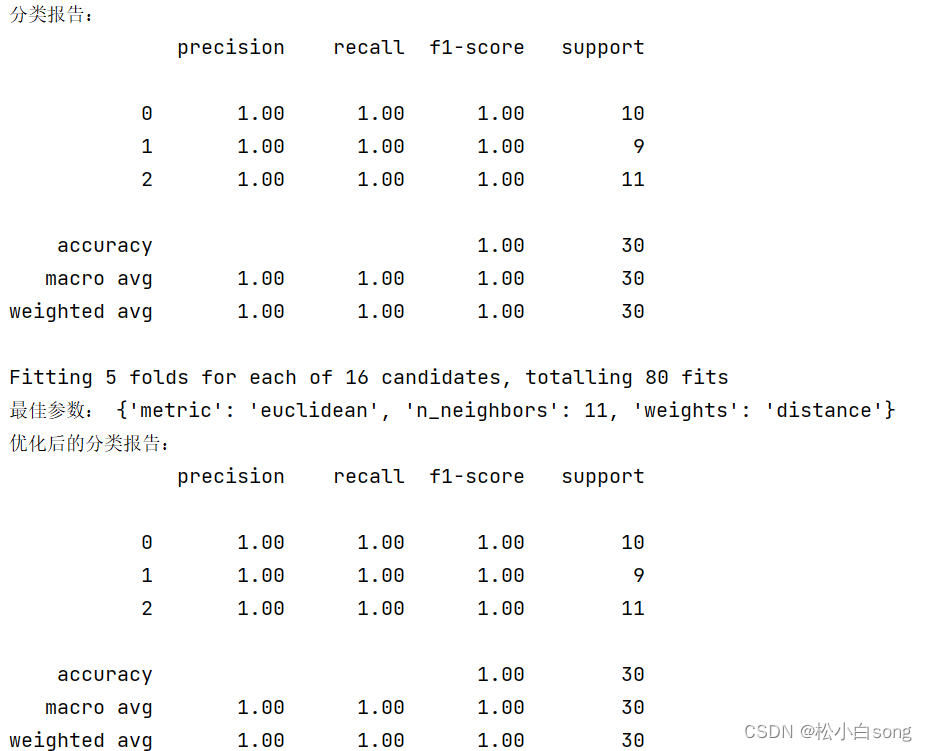
Scikit-learn是一个开源的Python机器学习库,提供了各种用于机器学习和数据挖掘的工具和算法。本教程将介绍Scikit-learn的基础知识,包括数据预处理、特征工程、模型训练和评估等方面的内容。
在使用Scikit-learn之前,首先需要安装Scikit-learn库。可以通过以下命令在Python环境中安装:
pip install scikit-learn
安装完成后,我们可以开始编写机器学习代码了。
数据预处理
在进行机器学习任务之前,通常需要对原始数据进行预处理。Scikit-learn提供了一系列功能用于数据的预处理,包括数据清洗、缺失值处理、特征缩放等。
其中,数据清洗可以通过使用SimpleImputer类来处理。这个类可以用于填充缺失值,可以选择使用平均值、中位数、众数等方法进行填充。
from sklearn.impute import SimpleImputer
# 创建一个SimpleImputer对象,使用平均值填充缺失值
imputer = SimpleImputer(strategy='mean')
# 对数据进行预处理
X = imputer.fit_transform(X)
特征缩放可以通过使用StandardScaler类来处理。这个类可以将数据按照均值为0、方差为1进行缩放。
from sklearn.preprocessing import StandardScaler
# 创建一个StandardScaler对象
scaler = StandardScaler()
# 对数据进行预处理
X = scaler.fit_transform(X)
特征工程
特征工程是机器学习中非常重要的一部分,它可以提取数据中的相关特征、减少特征的维度、选择最佳特征等。Scikit-learn提供了一系列功能用于特征工程,包括特征选择、降维等。
特征选择可以通过使用SelectKBest类来处理。这个类可以根据某个评估函数的得分选择最佳特征。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 创建一个SelectKBest对象,选择得分最高的k个特征
selector = SelectKBest(score_func=chi2, k=5)
# 对数据进行特征选择
X = selector.fit_transform(X, y)
降维可以通过使用PCA类来处理。这个类可以将数据降低到指定的维度。
from sklearn.decomposition import PCA
# 创建一个PCA对象,将数据降低到2维
pca = PCA(n_components=2)
# 对数据进行降维
X = pca.fit_transform(X)
模型训练和评估
在进行机器学习任务之前,需要选择适合问题的机器学习模型,并进行训练和评估。Scikit-learn提供了各种常见的机器学习模型,包括线性回归、逻辑回归、决策树、随机森林等。
以线性回归模型为例,我们可以使用LinearRegression类进行训练和预测。
from sklearn.linear_model import LinearRegression
# 创建一个LinearRegression对象
model = LinearRegression()
# 训练模型
model.fit(X, y)
# 预测结果
y_pred = model.predict(X)
评估模型的性能可以通过使用各种评估指标来进行。例如,可以使用均方误差(Mean Squared Error)来评估回归模型的性能。
from sklearn.metrics import mean_squared_error
# 计算均方误差
mse = mean_squared_error(y, y_pred)
以上只是Scikit-learn的一小部分功能和用法,它还提供了许多其他功能和算法,如分类、聚类、模型选择等。你可以参考官方文档来了解更多细节。
希望本教程对你学习Scikit-learn有所帮助!