[技术总结]: Pytorch加速和省内存
- 开发
- 31
-
mmengine 相关文档
MMEngine理解
pytorch ddp dataset使用共享内存
关键在于将data_list序列化
mmengine实现
或者使用lmdb数据库也可以
加速数据读取
使用perfectch, pin_memmory, 或者增加worker数
或者使用lmdb数据库
一些大规模数据集加载
大型数据集加载
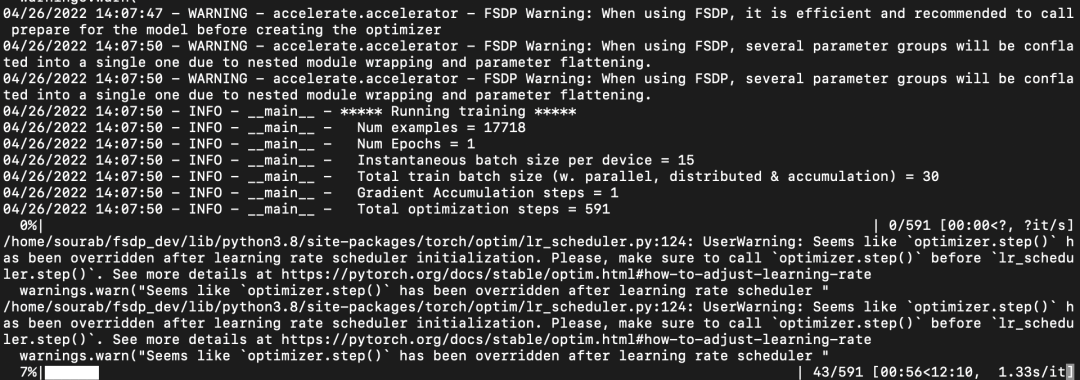
模型多卡训练, 模型并行
模型并行
原文地址:https://blog.csdn.net/S_Kross/article/details/138307198
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1785073592929751040.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!