目录
1. 缓冲区
1.1 定义
缓冲区(Buffer)在计算机科学中是一个临时存储区,用于存放数据,特别是在不同部件或程序之间传递数据时使用。缓冲区的作用是平衡两个速度不匹配的进程或设备之间的数据传输,或者为了减少对中央处理单元(CPU)的访问频率,从而提高系统效率。
缓冲区常见于以下几个方面:
1. **输入/输出缓冲区**:在数据从输入设备(如键盘、鼠标、磁盘驱动器)传送到CPU,或者从CPU传送到输出设备(如显示器、打印机)时,缓冲区可以暂存这些数据。
2. **网络缓冲区**:在网络通信中,数据在发送和接收过程中会暂时存储在网络缓冲区中,以应对网络传输速率的不稳定和网络拥堵。
3. **内存缓冲区**:在内存管理中,缓冲区用于暂时存放从内存中读取或写入的数据,以优化内存访问和提高处理速度。
4. **显示缓冲区**:在图形处理中,尤其是在视频游戏中,双缓冲区或三缓冲区技术被用来平滑动画效果,防止画面闪烁。
缓冲区管理不当可能导致各种问题,例如缓冲区溢出,这可能会被恶意软件利用来攻击系统。因此,在设计系统时,正确地实现和配置缓冲区是至关重要的。
1.2 理解缓冲区
也就是说,缓冲区就是一块存放数据的临时区域,那么我在c语言的代码里动态开辟一个buffer数组,当进程启动,buffer被开辟;进程结束,buffer被释放,那么代码里的buffer也是缓冲区咯?
理论上来说是没有错的,我们先来说说为什么要有缓冲区?
1.2.1 为什么要有缓冲区
如果你要喝非常细的水壶里的水,你是选择直接用水壶就那样一点点喝,还是将他倒进大口的杯子一饮而尽。毋庸置疑,后者是最佳的选项。
我们来谈两点,
一、用户要向文件写入,需要调用所用语言的接口,而这个接口必然封装着系统调用,通过系统调用写入。这个过程发生了什么?用户态->内核态,首先这一过程是需要付出代价的,倘若用户每次输入一字符,总共输入一万字符,会有多么大的损耗。如果这时有一个用户层缓冲区的存在,每次积攒一千字符,满了之后再写入内存,从用户态到内核态的转换只需要十次,这是一千倍的节省。
二、这里需要考虑效率的问题。我们知道,输入输出设备的效率同cpu相比,犹如乌龟与火箭赛跑,那这个时候,cpu就需要一直等待输入输出设备工作的完成,这里会导致OS效率大大下降,缓冲区的存在完美解决了这一问题。
1.2.2 缓冲区的工作原理
我们一般讲的缓冲区是用户层级的,也就是说,OS层级我们默认写入即完成,同样OS的操作对我们而言是一个黑盒,我们不需要关心他是怎么做的。下文提到的缓冲区除非点出是OS,否则就是用户层级的。
缓冲区事实上就是以空间换时间的操作,在c语言中,缓冲区在struct_file(上文有讲)结构体中定义,其实就是在堆上开辟了一个足够大的空间。
缓冲区什么时候写入,什么时候刷新?
我们上文中讲过,进程的pcb中有文件的管理控制块file_struct,file_struct中封装着该进程打开文件的文件指针数组。每一个文件指针都封装着文件的文件描述符,文件的方法集与缓冲区。
见图解:
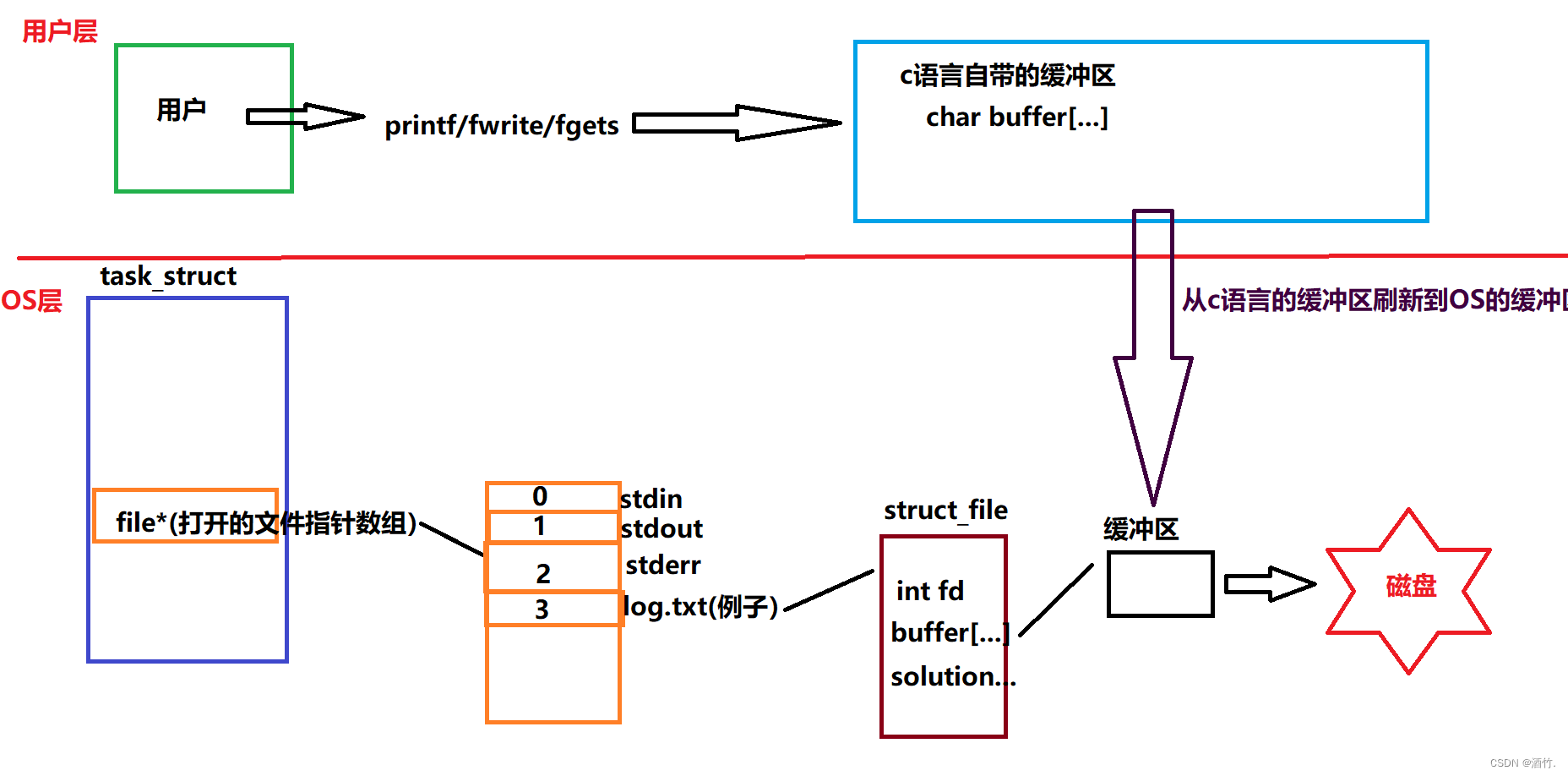
c语言缓冲区的写入与刷新受用户控制,我们来看看其刷新规则!
1. 行刷新--> 显示器 即输入\n缓冲区就刷新
2. 全刷新--> 普通文件 即写满再刷新
3. 调用接口强制刷新/进程结束自动刷新
2. 文件系统
2.1 什么是文件系统?
文件系统是一种用于管理计算机存储设备上的数据的方法。它定义了文件和文件夹的组织方式,以及如何访问、存储和管理这些文件。文件系统还负责处理文件的命名、权限控制、数据存储和恢复等功能。常见的文件系统包括FAT、NTFS、ext4等。不同的操作系统支持不同的文件系统,例如Windows通常使用NTFS,而Linux通常使用ext4。
2.2 为什么要有文件系统?
我们知道被打开的文件是由进程管理的,而进程是由OS的内存管理系统管理的。那么没有被打开的文件呢?
没错,没有被打开的文件存储在磁盘里,由文件系统进行管理。
2.3 认识文件的管理结构
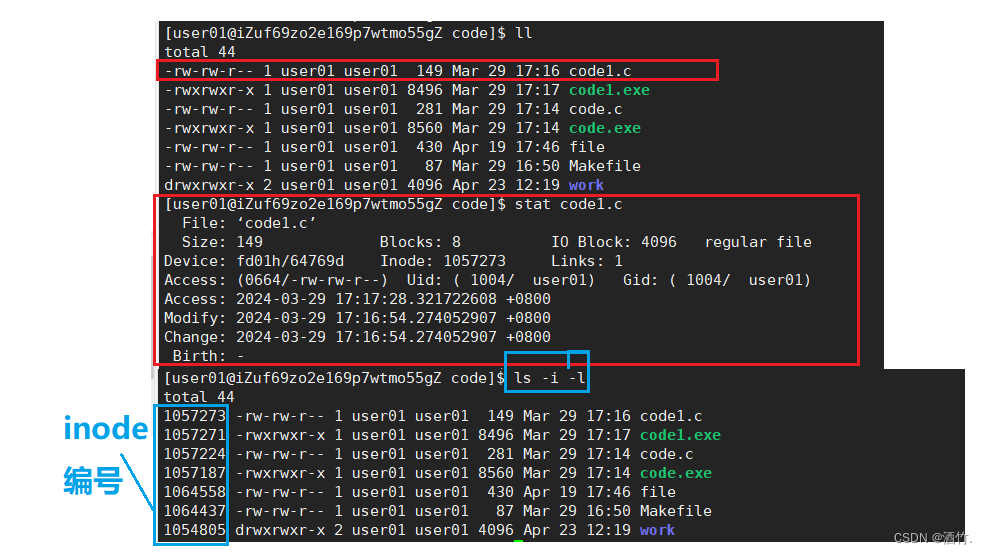
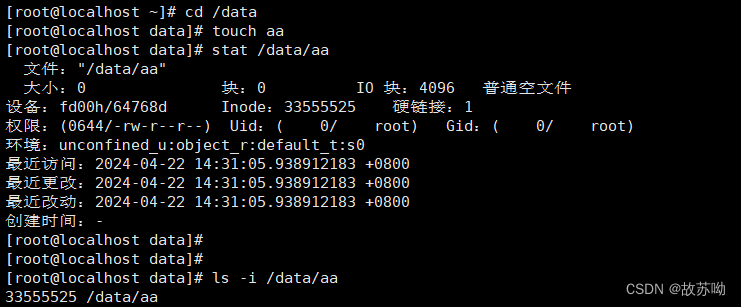
2.3.1 重新认识ls
我们以前只知道,ls命令可以查看文件的各种参数,但我们并不知道,ls的本质就是在文件系统中读取该文件的信息。 图中-i选项又是在做什么呢?图中的inode编号又是什么呢?我们来看看。
2.3.2 磁盘的结构
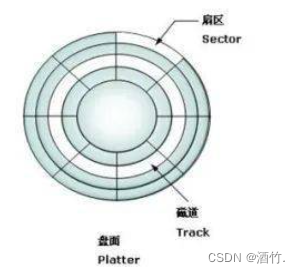
记得小时候的磁带吗,将里面的带子拉出来,它就变成了一条线,磁盘的结构也是类似。我们将它抽象为一个线性结构。因此对磁盘的管理,就变成了对数组的增删查改。
由于一块磁盘太大,因此通常会对磁盘进行分区,再对分区进行分组,类似省市区管理的方法,主逐级管理。对磁盘的管理就变成了对分区的管理,对分区的管理就变成了对分组的管理,经典的分治法思想。
2.3.3 认识文件在磁盘中的存储
在磁盘中,文件的内容和其属性是分开存储的。因为文件的内容大小是不确定的,而文件属性的大小是确定的。由于文件名是变长的,因此文件名不属于文件属性。
当前世界的主体是人,人类所创建的任何事物都是以人类的角度,而人类认识任何一样新事物,都是认识他的属性而并非内容,这也是面向对象的由来与本质。class类中定义的成员变量,不都是类的属性吗?
因此,认识文件也必然要先认识文件的属性,由此,文件的属性集struct_inode就诞生了,下图是inode结构体的结构,我们说文件的属性大小是固定的,而文件的属性集大小就是128字节。
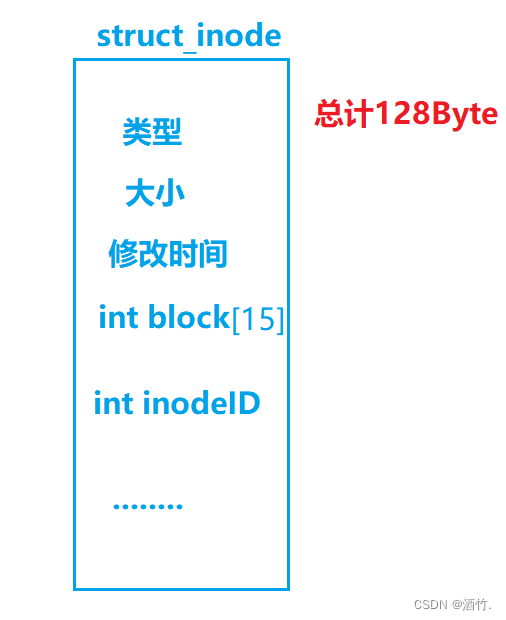
inode是标识文件的工具,inode编号是分区内有效的唯一标识。 inode内的block数组存放着该文件使用的数据块,没错数组内只有15个下标,我们来看看15个数据的数组能存些什么。
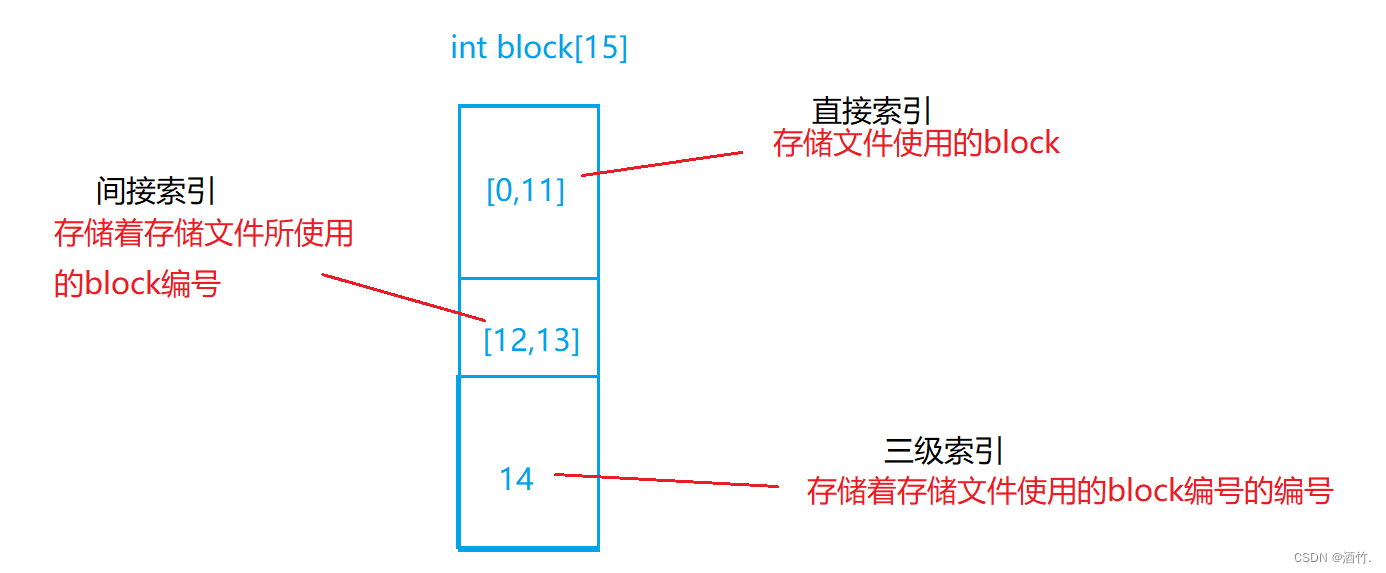
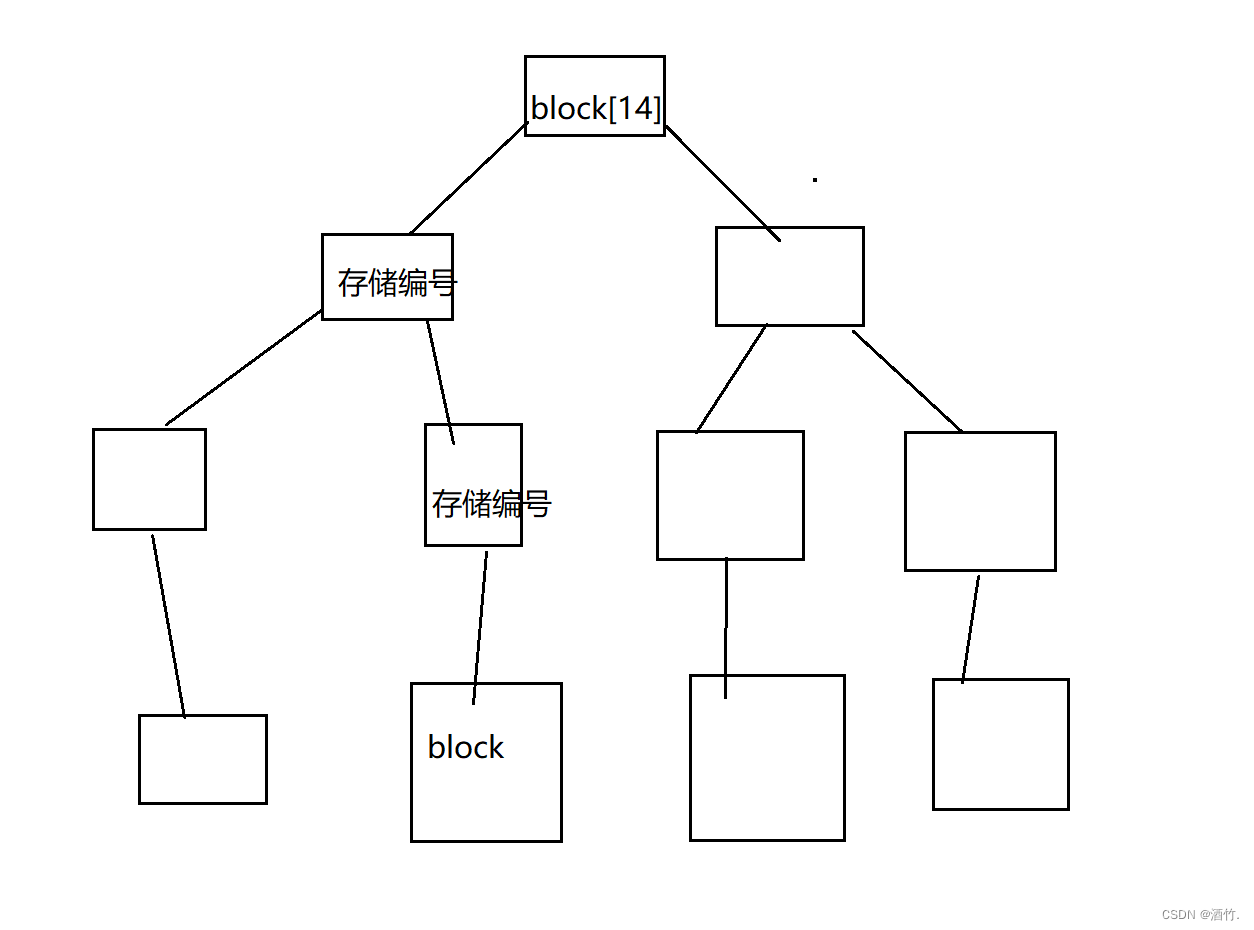
2.3.4 理解文件系统
上面我们说,磁盘的管理是逐级管理的,我们以分组来进行讲解。一个分组内会分为两个大的区域,一个用来存储inode,一个用来存储data。见下图。

两个bitmap是对应区域的位图展示,存储着对应数量的比特位,表示对应的位置是否被使用。比如在对应区域的位置如果被使用,bit位就会0->1,如果被删除,就会1->0。
我们说,inode编号在分区内是唯一的,那么具体是怎么做到的呢?
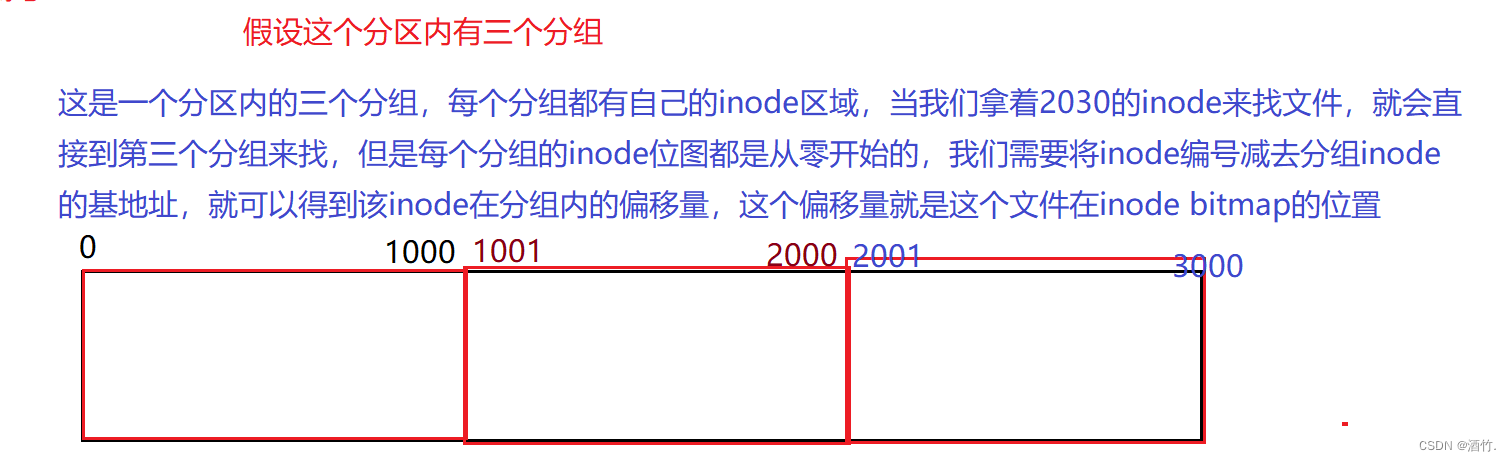
也就是说,inode编号=分组inode编号的基地址+inode编号在分组的偏移量(也是该文件在inode bitmap的位置) 。
当我们了解了分组内的文件是如何管理的,这时候就需要用相对宏观的视角来看待文件的管理。
跳出分组,会有一个名为GDT的数据结构管理整个分组的属性信息。
GDT外会有一个Super Block的数据结构管理所有分组,也就是整个分区的数据信息。而super Block也就是分区的文件系统。因此,文件系统的概念与分区是同级的。
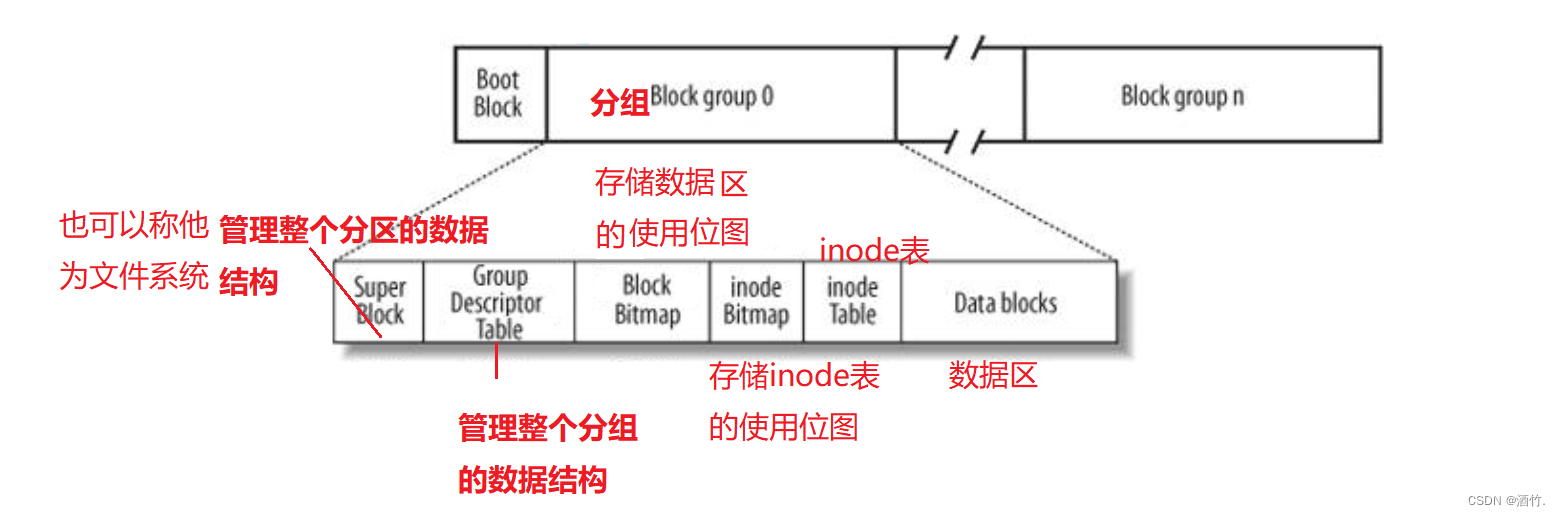
因此对文件系统的管理,就变成了对super block数据结构的管理。而整个磁盘会有多个分区,将这些分区的super block串联到一起,这时对文件系统的管理就变成了对super block链表的增删查改。
由于super block管理整个分区,因此一旦super block出现了问题,那么整个分区可能就崩溃了,因此在分区内,会存在有不止一个super block,一次进行数据备份,提高文件系统的容错率。
2.3.5 将文件系统与实际结合
对文件的增删查改操作
对文件的所有操作都需要查找,因此当我们查找一个文件,需要凭借该文件的inode编号在分区内寻找,找到对应文件的inode bitmap,如果对应位置为1,那么文件就存在,为0文件就不存在。
这时进行文件创建时,遍历inode bitmap,将最小的为0bit位进行置1,然后去inode table中增添该文件信息,将block bitmap对应位置置1,再将数据填充到blocks内。
进行删除文件,只需要将inode bitmap与block bitmap对应的位置置0,不需要去数据区删除。
但问题来了,用户使用的时候,可是根据文件名来访问的。这时就要依赖路径的存在了。
在前面我们只讲了文件系统的原理,可没讲要怎么用啊。
其实,要在磁盘的分区内存储文件,首先要向分区内写入操作系统(即格式化操作),写入了文件系统的分区需要同目录进行挂载,然后通过该目录访问分区。
因此对分区的访问,是通过分区所挂载的路径访问。也就是说,可用路径前缀里,必然包含着与分区挂载的目录。
用户找文件的时候,是需要通过文件路径找到文件的inode编号的。(文件路径前缀必然有与分区挂载的目录)下面的c盘与D盘,本质就是与分区挂载的目录。

那么文件的路径怎么得来呢?
我们之前写过进程打开文件的代码,在open等接口中,都传入了文件的路径,如果没有传入,那么文件的路径就是进程的当前路径加文件名。
而要打开一个文件,必然要打开该文件路径的所有上级目录,根目录的inode是开机就确定的。
目录也是文件,目录的数据区存放的是什么呢?
存放该目录内的文件与其inode的映射关系。因此目录的权限限制了对其内文件的操作权限。
磁盘内对文件一视同仁,对文件类型的区分工作是在内存中做的。
查找一个文件,在内核中是从根目录开始解析,解析出文件的绝对路径。

3. 软硬链接
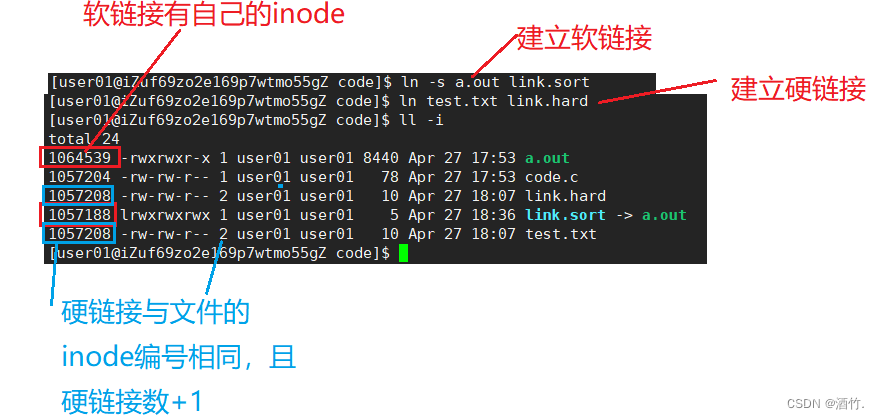
即软链接的本质是新建文件,而硬连接的本质是在目录内增添新文件名与inode编号的映射关系。
此时删除文件,软链接会失效,而硬链接只是硬链接数减一,当硬链接数为1时继续删除文件,此时该文件在分组内的inode bitmap与block bitmap比特位会被清空。
软链接相当于windows下的快捷方式。软链接内存放着目标文件的路径。如果用绝对路径创建软链接,软链接被迁移后仍会继续生效。
硬链接,可以通过硬链接数判断该目录有多少个子级目录(硬链接数-2),每个目录都有.和..,是自己与上级目录的硬链接。
Linux中可以给目录创建软链接,不能创建硬链接(会造成环路问题)。
4. ACM时间
Access 最后访问时间
Modify 文件内容最后修改时间
Change 属性最后修改时间
























![[SpringBoot] JWT令牌——登录校验](https://img-blog.csdnimg.cn/direct/453f99968abb4a8291bf3433fd9cdb5e.png)