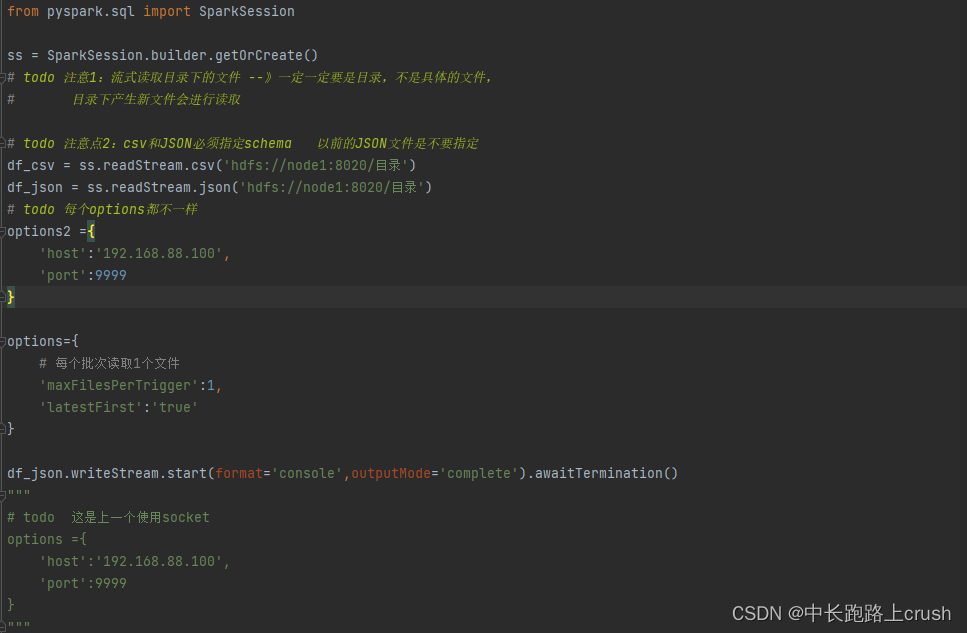
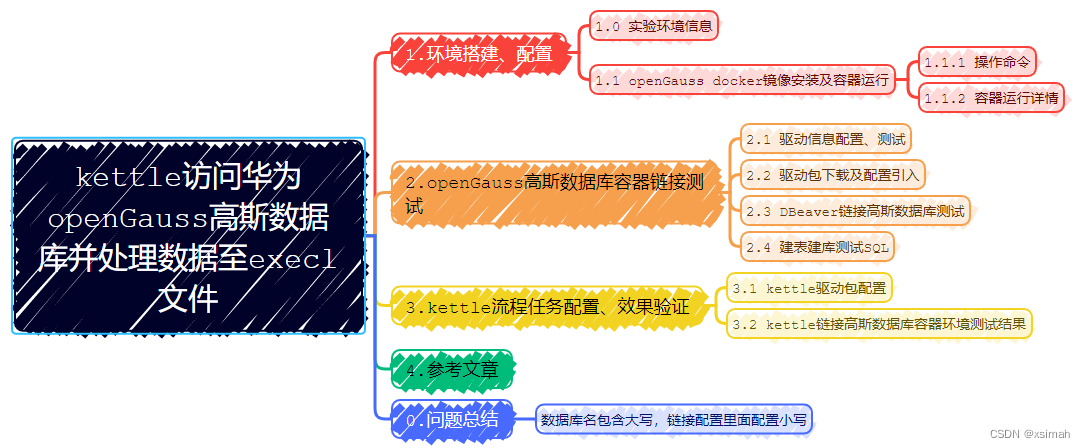
最近有一个需求,spark任务读取本地csv文件,拼接成rk之后再去hbase取值进行后续处理。搞了好久都没能解决,记录一下解决思路如下:
1、写入临时文件
spark可以读取本地文件,但打成jar包之后不会自动读取jar包中的文件,需要写入临时文件再进行读取。于是操作如下:
//定义文件路径,从jar包中读取csv文件到inputStream
val inputStream = this.getClass.getResourceAsStream(s"/source/fileName.csv")
//创建临时文件存储csv文件
val tempFile = Files.createTempFile("temp-source",".csv")
val tempFilePath = tempFile.toAbsolutePath.toString
val outputStream = new FileOutputStream(tempFilePath)
val bufferedOutputStream = new BufferedOutputStream(outputStream)
//将inputStream中的数据写入到临时文件
try {
val buffer = enw Array[Byte](1024)
var bytesRead = -1
while ({
bytesRead = inputStream.read(buffer)
var bytesRead = -1
}) {
bufferedOutputStream.write(buffer,0,bytesRead)
}
} finally {
bufferedOutputStream.close()
outputStream.close()
}
println(s"Temp file created at: ${tempFilePath}")
//读取临时csv文件为DataFrame
val csvDF = spark.read.option("header","true")
.csv("file:///${tempFilePath}")2、临时文件上传至HDFS
按照上面的做法发包到集群上运行之后报错。猜测可能因为在集群上运行,driver端读取不到本地创建的临时文件数据。于是将临时文件上传至HDFS,再从hdfs中读取
//将临时文件上传至HDFS
val hdfsPath = new Path("hdfs-source-csv.csv")
FileSystem.get(spark.sparkContext.hadoopConfiguration).copyFromLocalFile(new Path(tempFilePath), hdfsPath)
println(s"File uploaded to HDFS at: ${hdfsPath.toString}")
//读取hdfs文件
val csvDF = spark.read.option("header","true")
.csv(s"${hdfsPath}")但是这么做还是失败了。推测是没有写入hdfs的权限。
那只好换个思路:
1、将csv文件转换成sql,写入PG临时表,再从PG读取
2、将csv文件转换成Map,再将Map转换成rdd,进行后续操作
3、摆烂,告诉领导我不会,换人做吧