openGauss - 向量化执行引擎 - distinct分组聚合的实现
openGauss向量化执行引擎中分组聚合有两种实现方式:排序和hash。本文介绍排序实现机制下的distinct分组聚合如何实现。分组聚合也分为两种使用方式:普通group by和grouping sets等分组集,其中普通group by就是每次查询生成一个分组的聚合;而grouping sets、cube或者rollup分组集就是每次查询生成不同级别或者多个维度的聚合,详见:
下面我们看下openGauss向量化执行引擎中对这些分组聚合如何实现distinct。
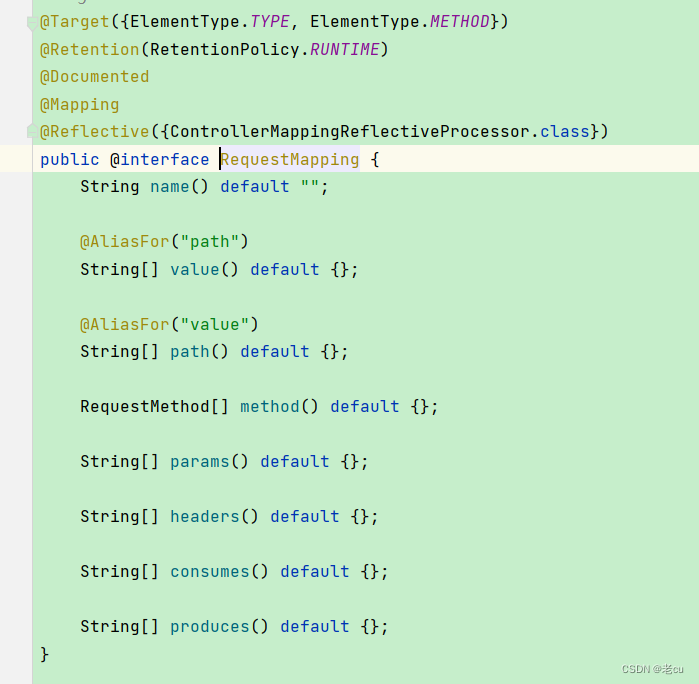
1、分组聚合中怎么区分distinct?
通过m_hashDistinct来标记是否有distinct聚合,可以看到多个聚合中,只要有一个是distinct聚合就标记为true。标记m_hashDistinct的条件为per_agg_state->numDistinctCols > 0,即聚合的distinct列数大于0。
openGauss支持以下聚合语法:以count为例:
1)count(distinct id1)
2)count(id1 order by id1)
这两种方式都用到了排序,初始化时:distinct和order by都会产生排序列,distinct时排序列和distinct列相同;仅order by时,distinct列为0,仅排序列。

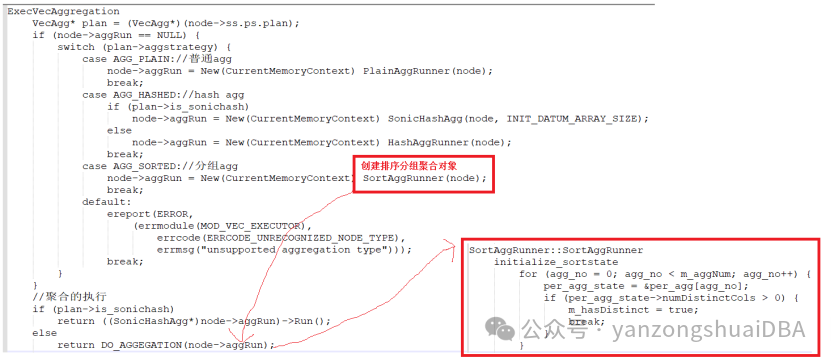
再进一步,若distinct聚合则初始化等值比较操作符函数数组equalfns[],数组大小为distinct列数,该函数用于排序后的distinct比较:

由于多个聚合中,只要有一个聚合就会标记m_hashDistinct为true,比如当聚合是下面的样子:select count(distinct id1),count(id2) from t group by id1,id2时,第2个count即不是distinct也不是order by,那么流程中通过m_hashDistinct进入distinct处理分支后,又是怎么分辩出第二个count是普通聚合呢?
这里可以通过peraggstate->eqaulfns来判断,因为仅在distinct时才会分配该函数,否则为NULL,以此可作为是否进入distinct处理流程:
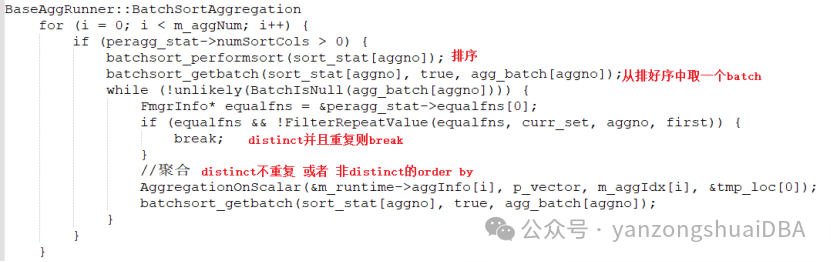
peragg_stat->numSortCols > 0 && &peragg_stat->equalfns[0]!=NULL作为distinct聚合的判断条件。
1)当然需要注意order by的场景与distinct聚合的区别,比如count(id1 order by id1):首先进行排序,然后从排序结果中取出一批值;因为仅order by所以equalfns为NULL,所以直接进入聚合步骤AggregationOnScalar。然后,从排序结果中取下一批值进行同样处理,直到排序的结果处理完毕。
2)若多个count中,非distinct和非order by的聚合,因为他们的peragg_stat->numSortCols为0,则不用进入该排序并聚合流程。它的聚合走另外分支:
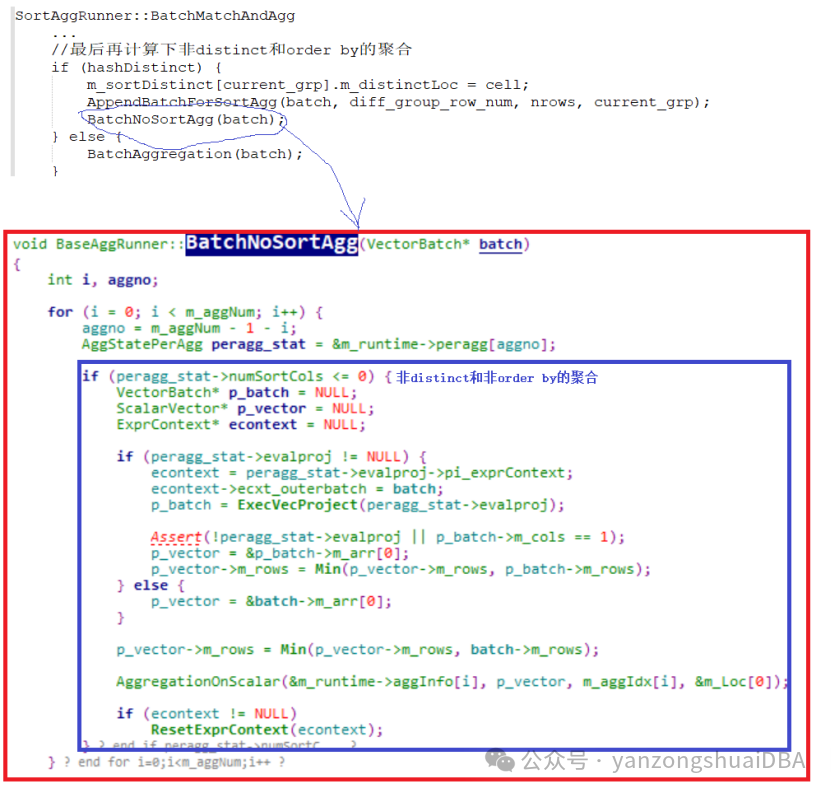
2、原理
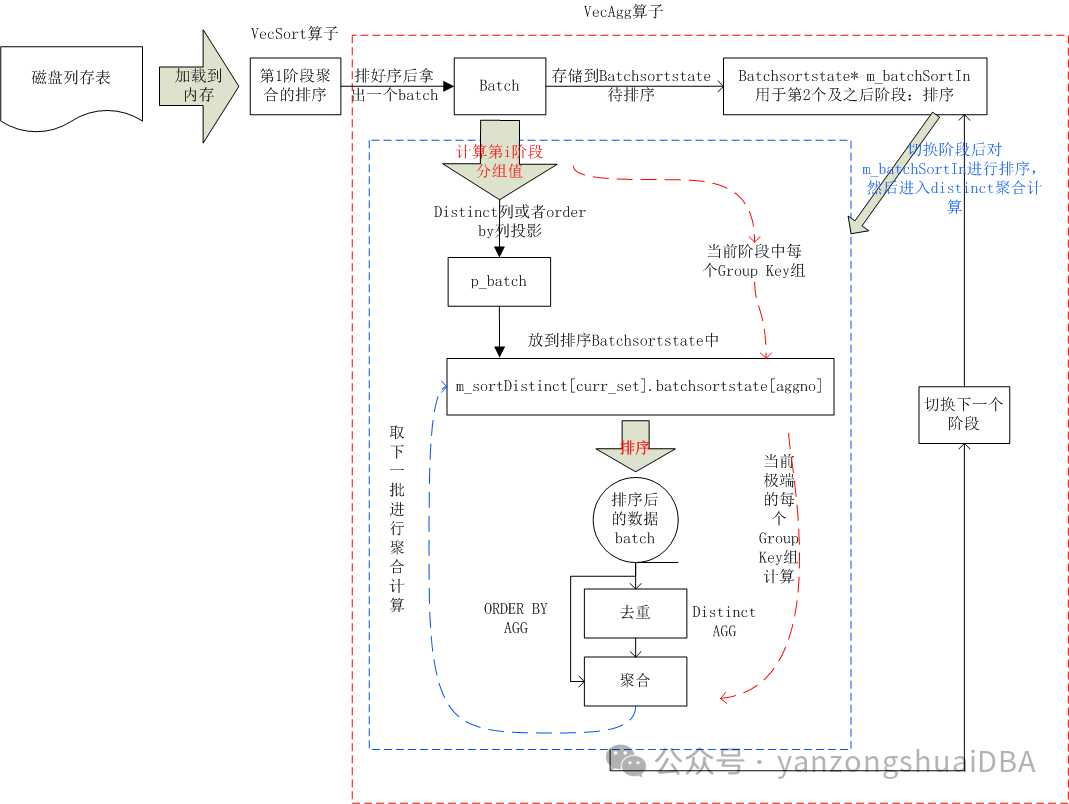
1)通过CStoreScan算子从磁盘上加载一批数据到内存,并通过VecSort向量化算子进行排序
2)从排好序的数据中(要么都在内存,要么溢出到磁盘)拿一批数据batch进行聚合操作
3)先将batch存储到m_batchSortIn中用于后续阶段的聚合:因为后续阶段也需要在有序的基础上进行分组聚合,所以m_batchSortIn用于后续阶段的排序
4)计算当前阶段的分组值
5)针对上面的分组值对distinct或order by列进行投影,并将他放到m_sortDistinct[]。Batchsortstate中,进行排序
6)从上面排好序的batchsortstate中取出一个batch,若时distinct则进行去重后再进行聚合,若为order by则直接进行聚合
7)然后对当前阶段的下组Group Key进行5)、6)操作。组号为curr_set
8)当前阶段计算完后,切换阶段进入下一个阶段聚合计算
9)下一个阶段计算前,需要先对m_batchSortIn排序,然后进行4)、5)、6)7)操作,直到所有阶段的聚合都计算完。
简单来说,distinct聚合计算就是根据distinct列,对其进行排序,然后进行比较从而去重,最后对去重后的值进行聚合计算。