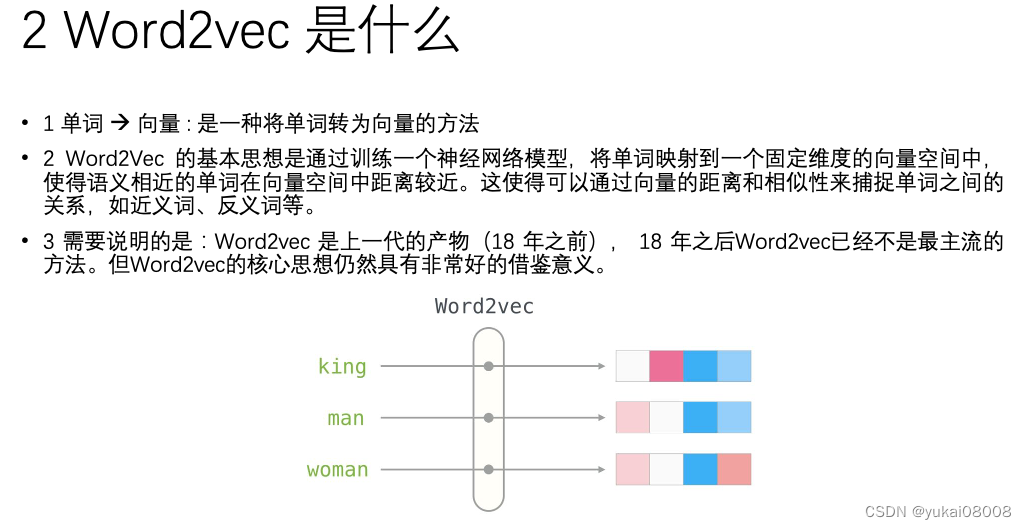
即前一篇文章,基于gensim实现文档词向量化之外。本文主要基于大模型,或调用大模型API实现文档的分割和文档词的向量化,类似于word2vec机制,大家在未来做相关分析、情感分析、文字生成、智能推荐等方面,都需要先将已管理的文档进行分割和向量化,文本分割是为了将大的篇幅变短,变为以核心关键词为主的list,向量化是将关键词组合的文档进行矢量化表征,目的是为了借助计算机实现数学方面的运算处理。目前基于大模型主要有以下三种方式实现向量化。
- HuggingFace 中开源模型下载和本地部署,通过本地化部署调用生成 embedding,可自定义合适的模型,可玩性较高,但对本地的资源要求高,部署环境要求高。
- zhupiai/openAI 在线模型API调用,但需要消耗 api,通过在线模型API来生成 embedding,对于大量的token 来说成本会比较高,本地配置要求比较低,使用非常方便。
- 采用其他平台的 api,如文心一言等。对于无法获取 openAI key 情况下,推荐采纳这种方法。
具体环境和应用示例如下,供大家学习参考。
一、运行环境:
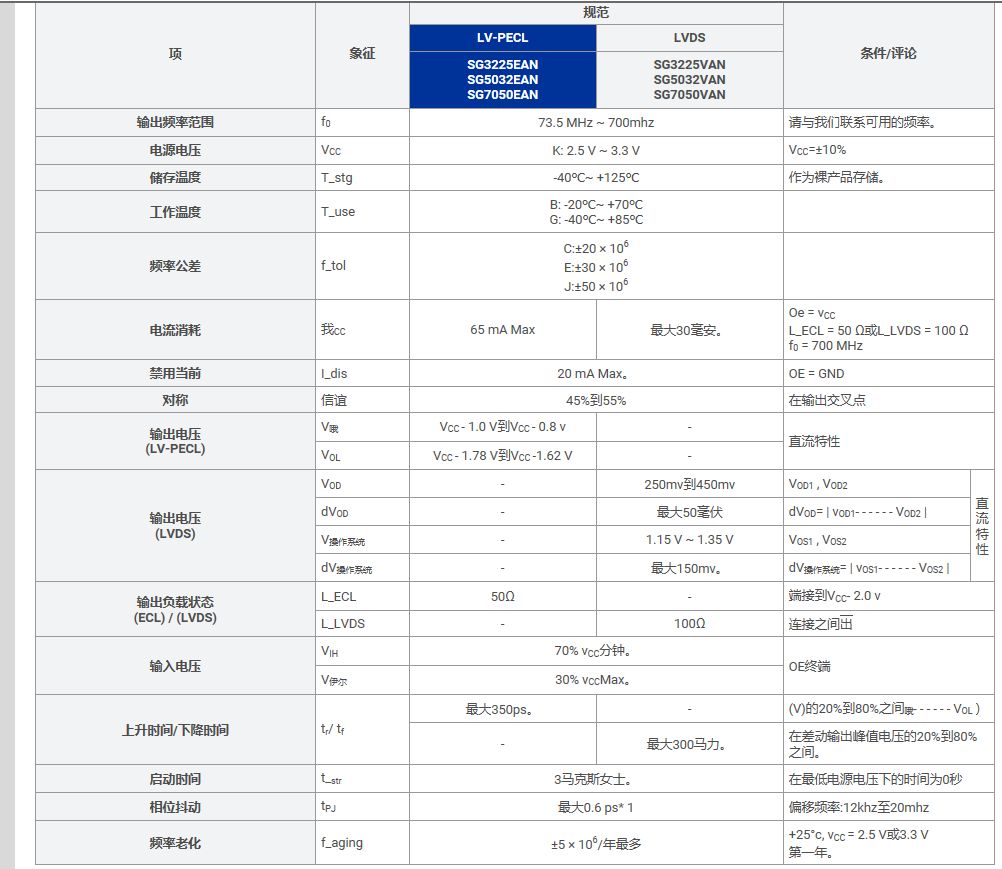
python3.10环境,安装了sklearn、unstructured、PyMuPDFLoader、zhipuai、openai等。
二、应用示例:
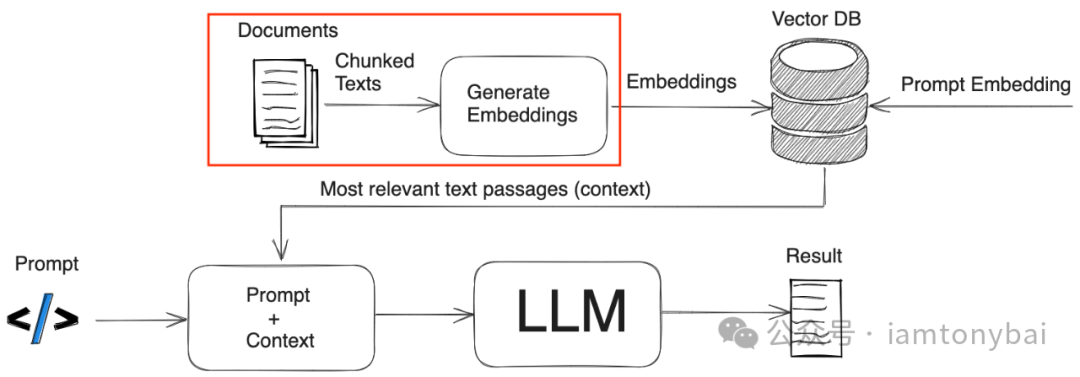
实现多段文本的自动分词,之后基于本地大模型或者调用在线大模型API实现关键词的矢量化。完整代码如下。
1.文档分割




















![[01] Vue2学习准备](https://img-blog.csdnimg.cn/direct/0c8e664c4b6f42daa56b296bb8316baa.png)