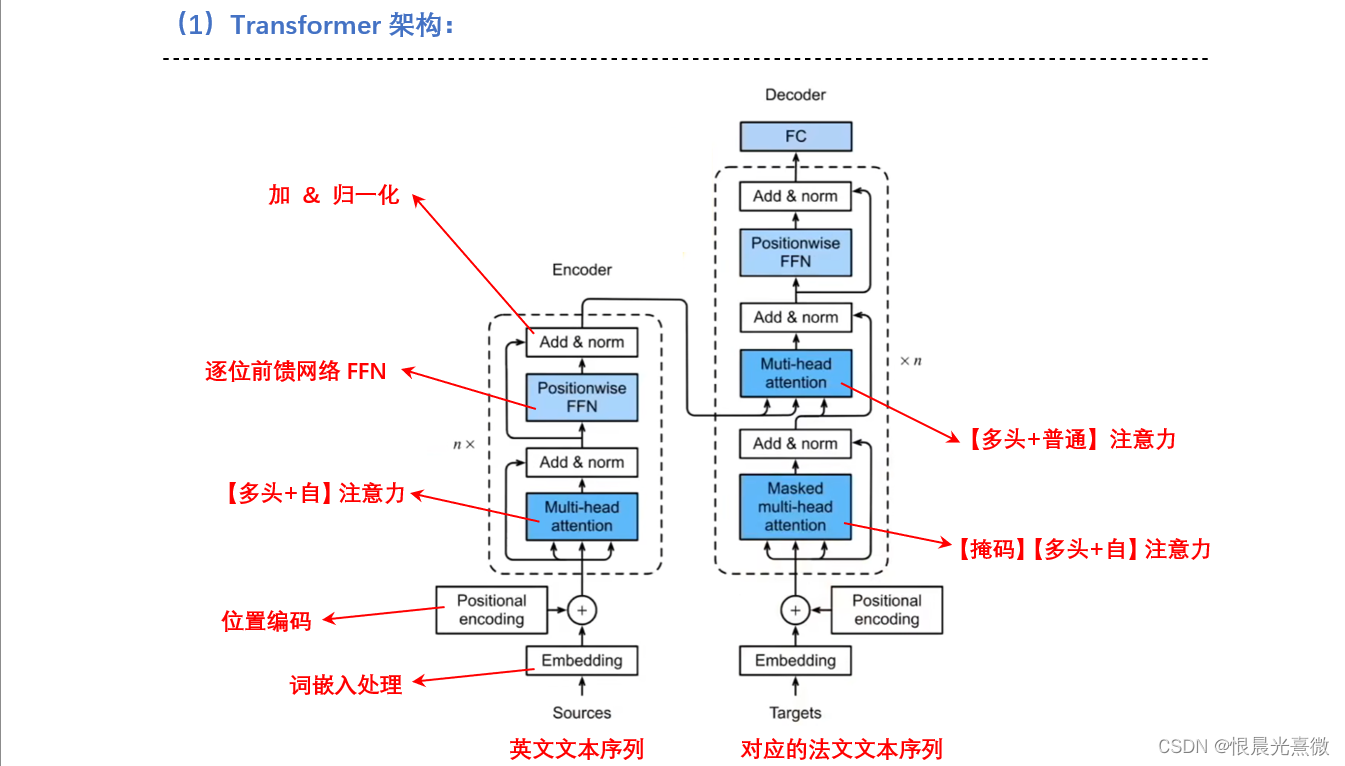
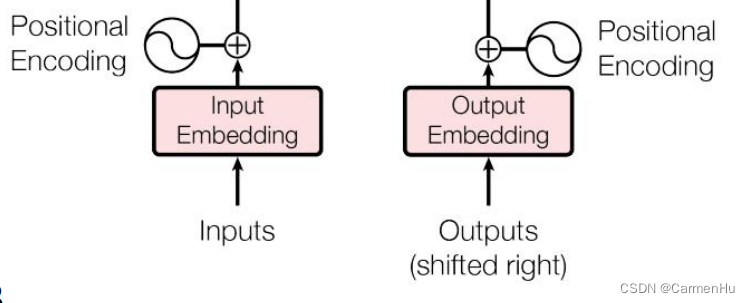
RWKV、 Mamba 和 S4
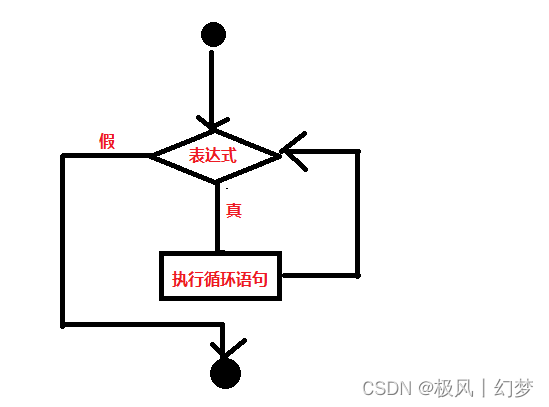
一是以 RWKV、 Mamba 和 S4 为代表,它们完全用 recurrent(循环)结构去替代 attention。这种思路是用一个固定的内存记住前面的信息,但目前看来虽然可以记住一定长度,但要达到更长的长度是有难度的。
RWKV 是国产开源的首个非 Transformer 架构的大语言模型,目前已经迭代至第六代 RWKV-6。RWKV 的作者彭博在 2022 年 5 月开始训练 RWKV-2,当时只有 1 亿(100M)参数规模,后续在 2023 年 3 月又训练出了 RWKV-4 140亿(14B)的参数版本。
RWKV 用 linear attention(线性注意力机制) 去近似 full attention,试图结合 RNN 和 Transformer 的优点,同时规避两者的缺点,来缓解 Transformer 所带来的内存瓶颈和二次方扩展问题,实现更有效的线性扩展,同时提供并行训练和可扩展性,类似于 Transformer。
Mega
还有一个流派是把 full attention 这种密集结构变得稀疏,例如 Meta 的 Mega,在之后的计算中不再需要算所有 attention 矩阵中的每一个元素,模型效率也随之变高。
RetNet
RetNet 的推理成本与长度无关。对于 7B 模型和 8k 序列长度,RetNet 的解码速度是带键值缓存的 Transformers 的 8.4 倍,内存节省 70%。
Yan
Yan 跟线性的 Attention 和 RNN 没有任何关系,Yan 架构的大模型去除了 Transformer 中高成本的注意力机制,代之以计算量更小、难度更低的线性计算。
评测
当下非 Transformer 研究面临的阻碍之一是评估方式——单纯看Perplexity(困惑度),非 transformer 其实跟 Transformer 的模型相比没有差距,但很多实际能力 (如in-context copy and retrieval)依然差距很大。

![[数据<span style='color:red;'>结构</span>]——<span style='color:red;'>非</span>递归排序总结——<span style='color:red;'>笔试</span>爱考](https://img-blog.csdnimg.cn/direct/83b58a5735b641758c30f35d29897ea0.gif)