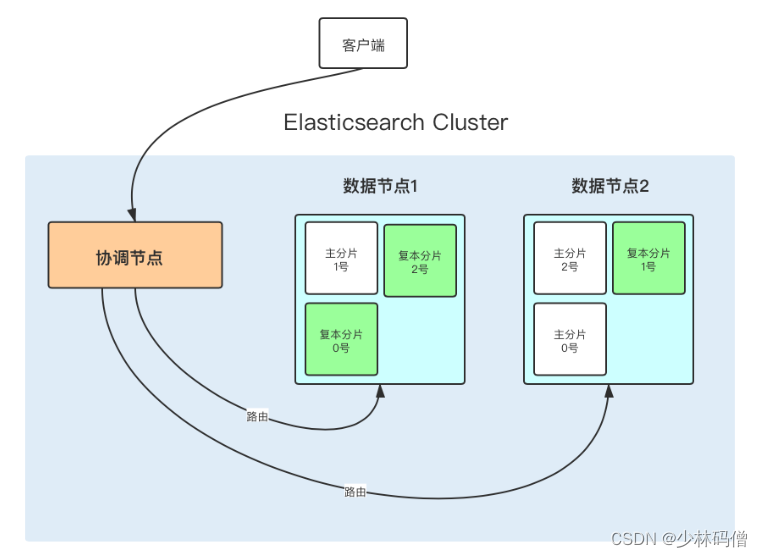
先介绍一个参数
“cluster.routing.allocation.disk.watermark.flood_stage”:“95%”
这是Elasticsearch的默认参数值
官方文档(7\8版本该参数功能相同)
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/modules-cluster.html

简单的说:该参数控制磁盘写入的阈值,当超过该阈值索引会变成只读状态。
例如,磁盘100G,该参数“95%”,那么当磁盘使用量超过95G时,elasticsearch上的索引将只读,从而保证不要出现磁盘写满的情况。
这个参数看似平平无奇,实则配合上es bulk写入会有惊人的效果。
实验
一、向test_2024索引中插入一条数据(golang)
es, err := elasticsearch.NewClient(cfg)
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
// 准备要插入的数据
data := map[string]interface{}{
"name": "b",
}
// 将数据编码为 JSON
buf, err := json.Marshal(data)
if err != nil {
log.Fatalf("Error encoding data: %s", err)
}
// 准备索引请求
indexName := "test_2024"
docID := "1" // 文档的唯一标识符
r := strings.NewReader(string(buf))
// 发送索引请求
res, err := es.Index(indexName, r, es.Index.WithDocumentID(docID))
if err != nil {
log.Fatalf("Error indexing document: %s", err)
}
defer res.Body.Close()
// 检查响应状态
if res.IsError() {
log.Fatalf("Error: %s", res.Status())
}
// 打印响应信息
fmt.Println("Document indexed successfully.")
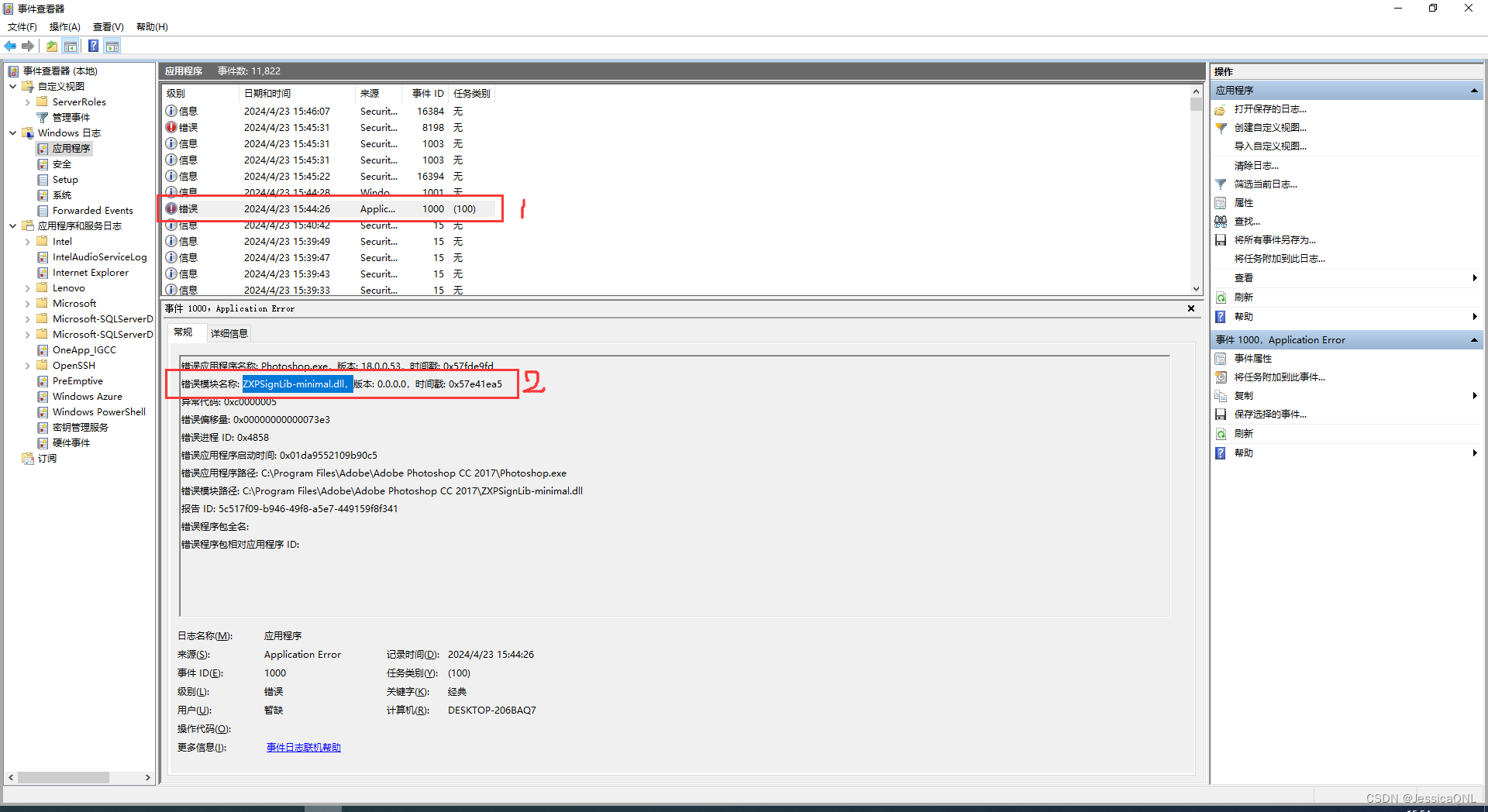
插入成功,并可正常查到

二、模拟磁盘使用量超过阈值
通过调整参数"cluster.routing.allocation.disk.watermark.flood_stage":“0.00000001”
实现数据量超过了阈值的情况。
然后继续向test_2024中插入一条数据(golang)
es, err := elasticsearch.NewClient(cfg)
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
// 准备要插入的数据
data := map[string]interface{}{
"name": "c",
}
// 将数据编码为 JSON
buf, err := json.Marshal(data)
if err != nil {
log.Fatalf("Error encoding data: %s", err)
}
// 准备索引请求
indexName := "test_2024"
docID := "2" // 文档的唯一标识符
r := strings.NewReader(string(buf))
// 发送索引请求
res, err := es.Index(indexName, r, es.Index.WithDocumentID(docID))
if err != nil {
log.Fatalf("Error indexing document: %s", err)
}
defer res.Body.Close()
// 检查响应状态
if res.IsError() {
log.Fatalf("Error: %s", res.Status())
}
// 打印响应信息
fmt.Println("Document indexed successfully.")
结果也符合预期,插入报错

虽然报错不清晰,但是好歹通过代码返回也能知道这条数据是没有插入成功的。
这里可以通过curl的方式插入一条数据测试,报错内容更加清晰

(磁盘使用量超过洪水水位线,索引已只读)
三、此时如果我们使用代码bulk的方式插入数据(golang)
documents := []map[string]interface{}{
{"name": "c"},
{"name": "d"},
}
// 准备批量请求体
var buf bytes.Buffer
for _, doc := range documents {
meta := map[string]interface{}{
"index": map[string]interface{}{
"_index": "test_2024", // 你的索引名称
},
}
if err := json.NewEncoder(&buf).Encode(meta); err != nil {
log.Fatalf("Error encoding meta data: %s", err)
}
if err := json.NewEncoder(&buf).Encode(doc); err != nil {
log.Fatalf("Error encoding document: %s", err)
}
}
// 发送批量请求
req, err := http.NewRequest("POST", "http://xxx.xxx.xxx.xxx:9200/_bulk", &buf)
if err != nil {
log.Fatalf("Error creating bulk request: %s", err)
}
req.Header.Set("Content-Type", "application/json")
client := http.DefaultClient
res, err := client.Do(req)
if err != nil {
log.Fatalf("Error making bulk request: %s", err)
}
slurp, err := io.ReadAll(res.Body)
if err != nil {
log.Println(string(slurp))
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
log.Fatalf("Error response: %s", res.Status)
} else {
log.Printf("Successfully indexed %d documents", len(documents))
}
结果惊人,居然提示插入成功

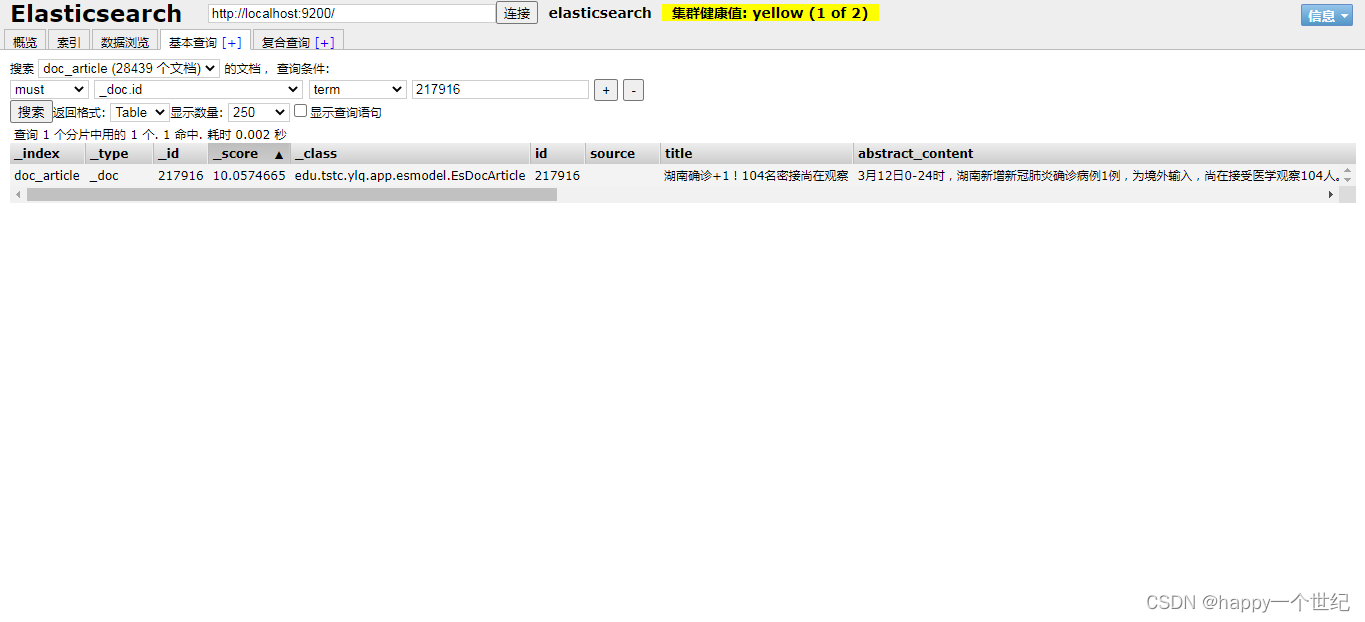
看下数据

还是只有一条,说明实际并没有插入成功
四、打断点对bulk进行调试

看到正常报错,该报错与用curl(单条或bulk)插入数据报错相同

结论
当业务需要定时向ES中插入10000条数据,那么肯定采用bulk的方式。
但是如果此时ES磁盘达到阈值,那么数据就无法正常写入,但是代码又不会报错(如实验三,bulk的sdk只会判断整个请求是否正常发送与返回,并没有针对bulk里面的每条数据是否插入成功来判断)。
最终就造成了代码提示写入成功,但实际掉数据的情况。
彩蛋
如果通过代码层去解析bulk中每条数据,判断是否写入成功会大大影响写入效率,也就失去了bulk的意义。
最好还是对ES所在服务器的磁盘进行监测,同时监测值至少低于 cluster.routing.allocation.disk.watermark.flood_stage值10个百分点。