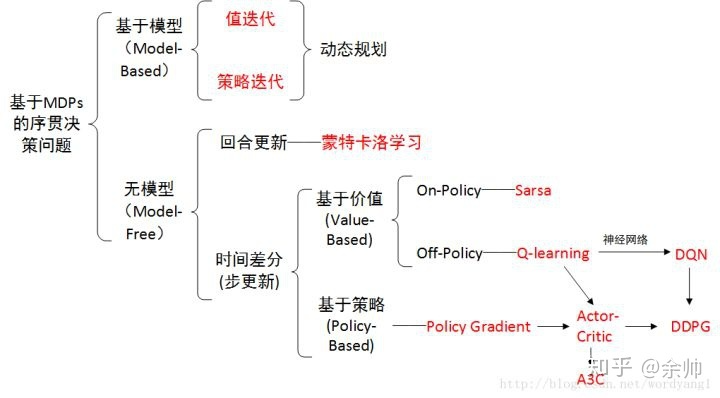
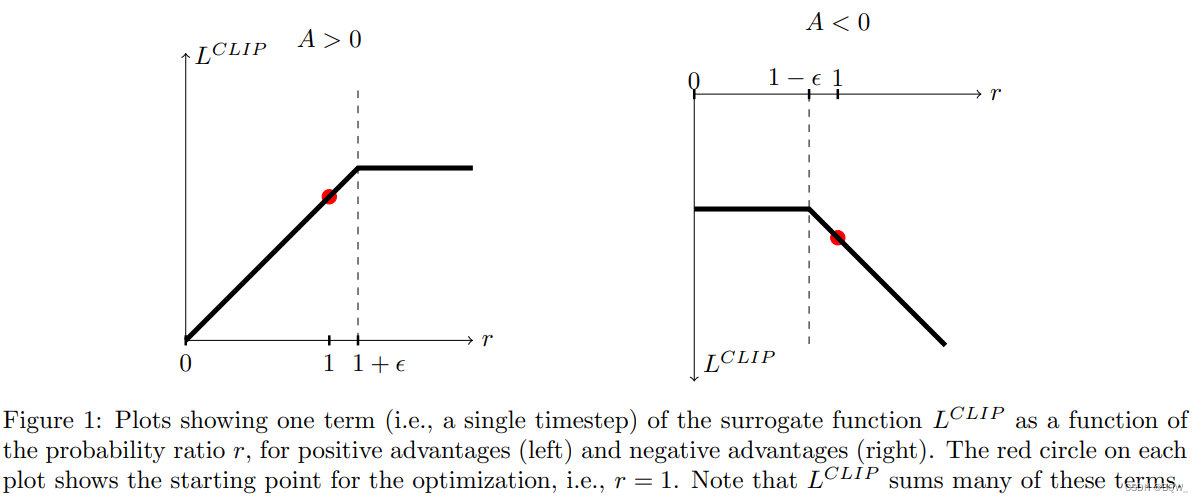
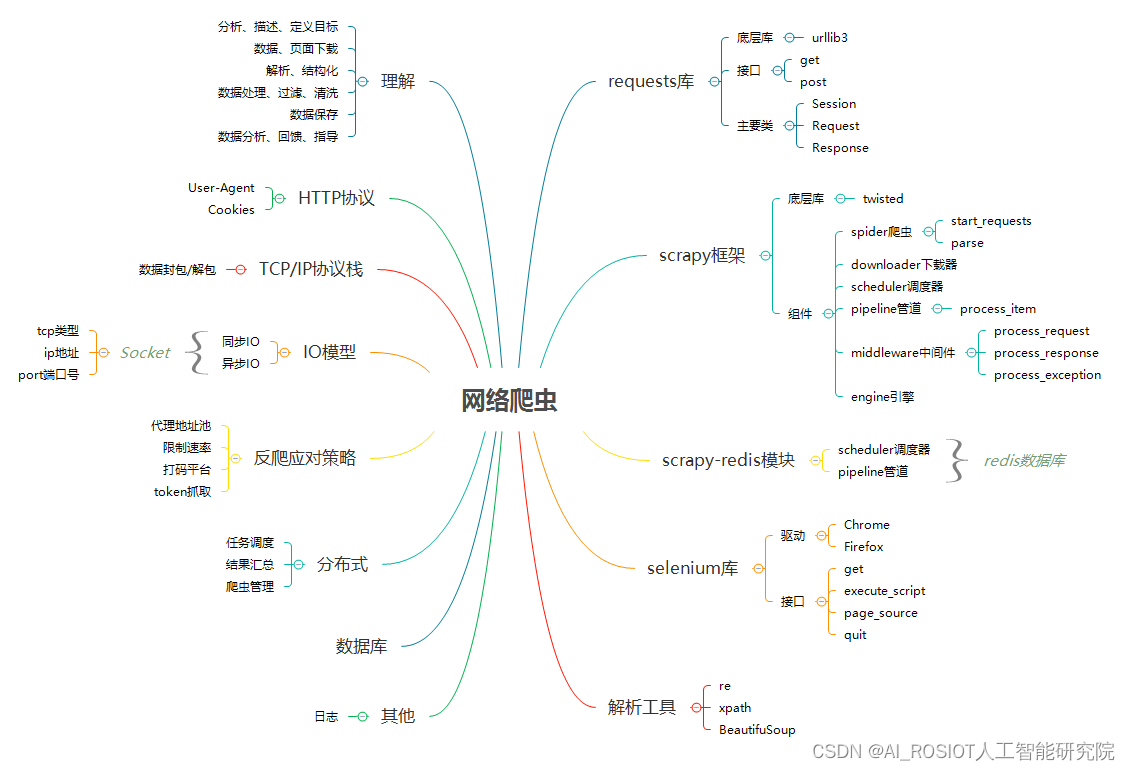
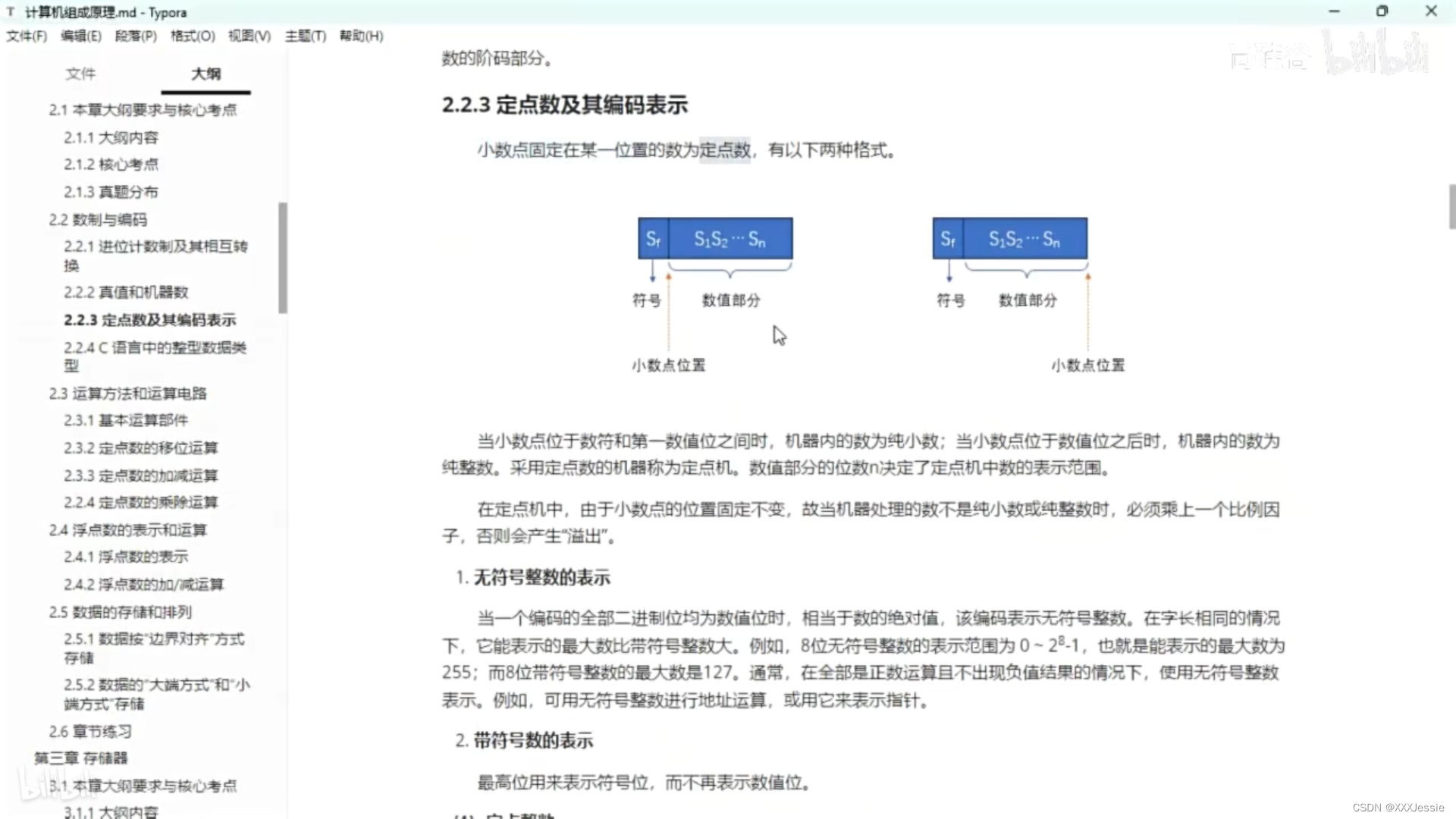
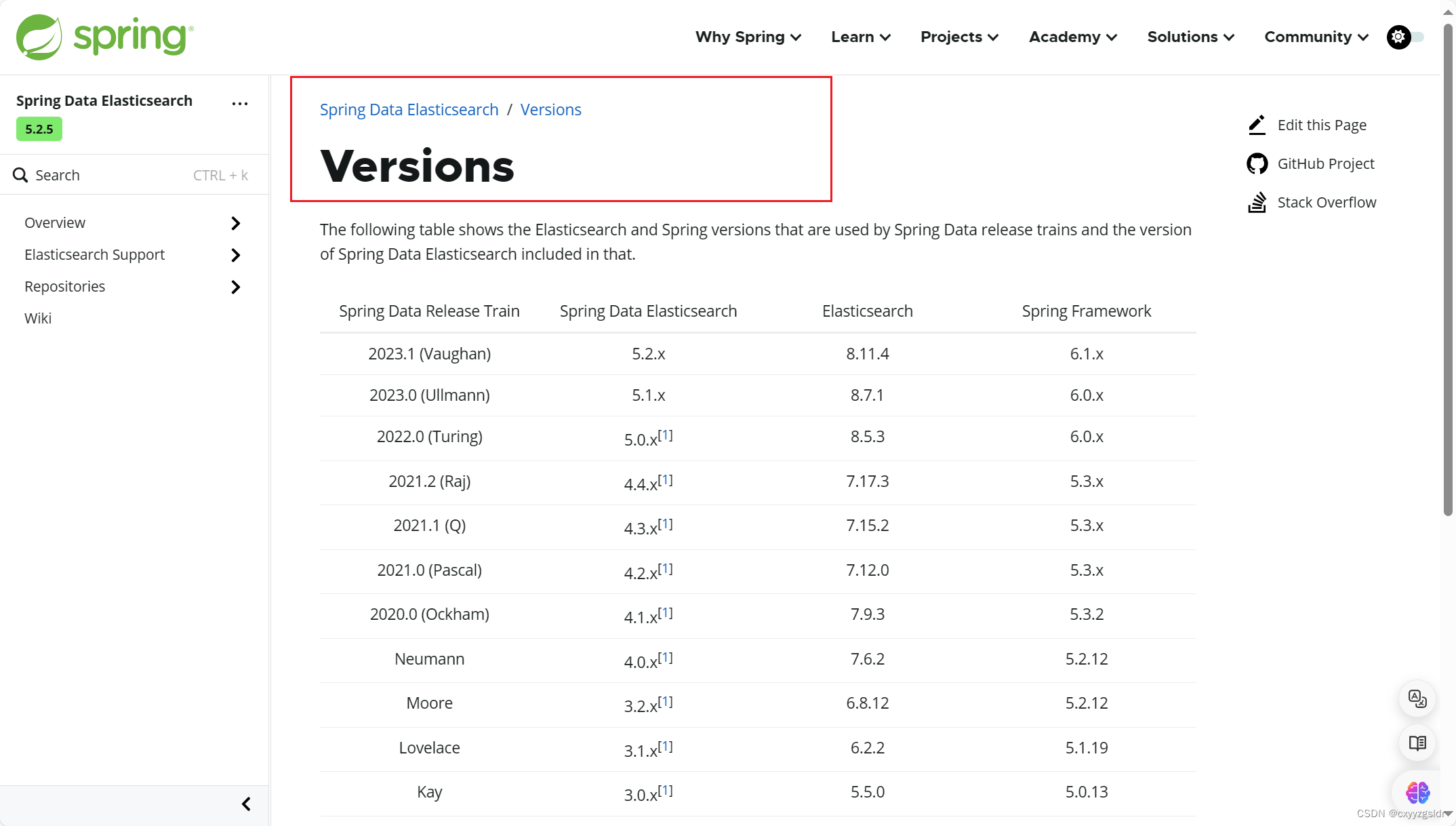
汤普森抽样是一种强大的探索策略,它通过不断地“试错”来学习,并在探索和利用之间取得良好的平衡,以找到最优的动作选择策略。
当谈论Thompson Sampling(汤普森抽样)时,我们谈到了一种在不确定性环境下做出最佳选择的策略。现在让我们更详细地了解它的思想、原理和实现细节:
思想和原理:
汤普森抽样的核心思想是通过不断地“试错”来学习。它假设每个动作(或选项)的潜在回报是随机的,并且在选择动作时,我们不知道它们的确切潜在回报。因此,我们的目标是以最佳的方式探索和利用这些动作,以最大化长期的奖励。
在每次选择动作时,汤普森抽样从每个动作的潜在回报分布中随机抽样一个值,然后选择具有最高抽样值的动作。由于抽样值是随机的,因此它允许我们在探索和利用之间进行良好的平衡。换句话说,它有可能选择已知较好的动作,也有可能尝试新的动作,从而有望找到全局最优的动作选择策略。
实现细节:
汤普森抽样的实现步骤如下:
初始化:在开始时,为每个动作的潜在回报分布选择一个先验分布。这通常是一个参数化的分布,如贝叶斯分布。
选择动作:对于每次选择动作,对于每个动作,从其潜在回报分布中抽样一个值。然后选择具有最高抽样值的动作作为当前的选择。
观察结果:执行所选择的动作,并观察结果(如奖励)。
更新后验分布:根据观察到的结果,更新每个动作的潜在回报分布。这通常通过贝叶斯更新来实现,即将先验分布与观察到的数据进行组合,得到后验分布。
重复:重复步骤2到4,直到达到预定的终止条件(如固定次数或达到时间限制)。
通过这种方式,汤普森抽样能够根据观察到的结果不断地更新动作的潜在回报分布,并根据这些分布做出最佳选择,以实现长期的奖励最大化。
这是一个简单的 Ray 汤普森抽样示例代码,我们使用了一个简单的正态分布作为每个动作的潜在回报分布,然后使用汤普森抽样来选择动作。
import numpy as np
import ray
ray.init()
@ray.remote
class Bandit:
def __init__(self, true_mean):
self.true_mean = true_mean
self.posterior_alpha = 1 # 初始先验分布的参数alpha
self.posterior_beta = 1 # 初始先验分布的参数beta
def pull_arm(self):
# 从后验分布中抽样一个值作为潜在回报
sample_mean = np.random.beta(self.posterior_alpha, self.posterior_beta)
return sample_mean
def update_posterior(self, reward):
# 更新后验分布的参数
self.posterior_alpha += reward
self.posterior_beta += (1 - reward)
# 创建多臂赌博机实例
num_bandits = 5
bandits = [Bandit.remote(np.random.normal()) for _ in range(num_bandits)]
# 汤普森抽样
def thompson_sampling(bandits):
rewards = ray.get([bandit.pull_arm.remote() for bandit in bandits])
best_bandit = np.argmax(rewards)
return best_bandit
# 进行多轮选择
num_rounds = 1000
chosen_bandits = []
for _ in range(num_rounds):
best_bandit = thompson_sampling(bandits)
reward = np.random.binomial(1, bandits[best_bandit].true_mean) # 使用真实回报生成奖励
bandits[best_bandit].update_posterior.remote(reward)
chosen_bandits.append(best_bandit)
print("Chosen bandits:", chosen_bandits)
在这个示例中,我们首先定义了一个 Bandit 类,它代表了每个动作(或选项)。然后,我们创建了多个 Bandit 实例作为多臂机的每个动作。在每轮选择中,我们使用汤普森抽样方法从所有动作中选择一个,并获得奖励。然后,我们根据观察到的奖励更新每个动作的后验分布,以便在下一轮选择中做出更好的决策。