概述
在Flink内部处理数据时,涉及到数据的网络传输、数据的序列化及反序列化,Flink需要知道操作的数据类型,为了能够在分布式计算过程中对数据的类型进行管理和判断,Flink中定义了TypeInformation来对数据类型进行描述,通过TypeInfomation能够在数据处理之前将数据类型推断出来,而不是真正在触发计算后才识别出,这样可以有效避免用户在编写Flink应用的过程出现数据类型问题。
常用的 TypeInformation 有BasicTypeInfo、TupleTypeInfo、CaseClassTypeInfo、PojoTypeInfo
类等,针对这些常用TypeInfomation介绍如下:
- Flink通过实现BasicTypeInfo数据类型,能够支持任意Java原生基本(或装箱)类型和String类型,例如:Integer,String,Double等,除了BasicTypeInfo外,类似的还BasicArrayTypeInfo,支持Java中数组和集合类型;
- 通过定义TupleTypeInfo来支持Tuple类型的数据;
- 通过CaseClassTypeInfo支持Scala Case Class ;
- PojoTypeInfo可以识别任意的POJOs类,包括Java和Scala类,POJOs可以完成复杂数据架构的定义,但是在Flink中使用POJOs数据类型需要满足以下要求:
- POJOs类必须是Public修饰且独立定义,不能是内部类;
- POJOs 类中必须含有默认空构造器;
- POJOs类中所有的Fields必须是Public或者具有Public修饰的getter和Setter方法;
注意
在使用Java API开发Flink应用时,通常情况下Flink都能正常进行数据类型推断进而选择合适的serializers以及comparators,但是在定义函数时如果使用到了泛型(lambda),JVM就会出现类型擦除的问题,Flink就获取不到对应的类型信息,这就需要借助类型提示(Type Hints)来告诉系统函数中传入的参数类型信息和输出类型,进而对数据类型进行推断处理。
实践
非lambda写法
非lambda写法,Flink是能正常识别的
public class WcTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// source:hello flink
DataStreamSource<String> ds = env.socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> tuple2Ds = ds.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : s.split(" ")) {
collector.collect(Tuple2.of(word, 1));
}
}
});
KeyedStream<Tuple2<String, Integer>, String> keyedStream = tuple2Ds.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
});
keyedStream.sum(1).print();
env.execute();
}
}
2024-04-25 11:26:16,255 [flink-akka.actor.default-dispatcher-8] [org.apache.flink.runtime.executiongraph.ExecutionGraph] [INFO] - Keyed Aggregation -> Sink: Print to Std. Out (6/8) (5fc86f952e35ab7079f08070c6694019_e70bbd798b564e0a50e10e343f1ac56b_5_0) switched from INITIALIZING to RUNNING.
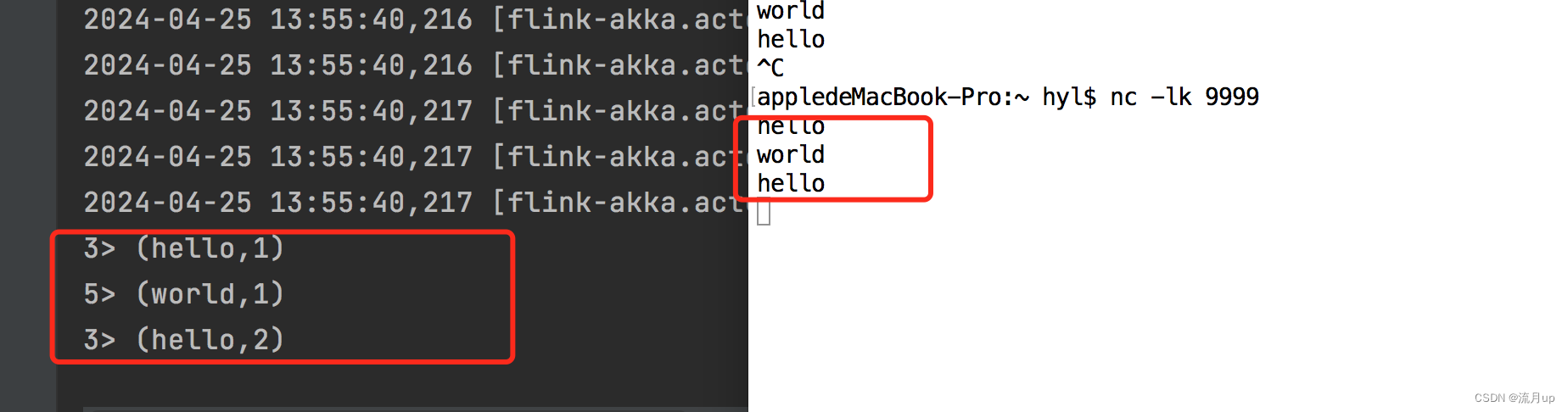
3> (hello,1)
3> (hello,2)
3> (hello,3)
5> (world,1)
3> (hello,4)

lambda写法
public class WcTestL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// source:hello flink
DataStreamSource<String> ds = env.socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> tuple2Ds =
ds.flatMap((s, collector) -> {
for (String word : s.split(" ")) {
collector.collect(Tuple2.of(word, 1));
}
});
KeyedStream<Tuple2<String, Integer>, String> keyedStream = tuple2Ds.keyBy(stringIntegerTuple2 -> stringIntegerTuple2.f0);
keyedStream.sum(1).print();
env.execute();
}
问题如下,如注意章节所说

lambda改进
package com.fun.luxshare.test;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 单词统计
* 数据类型
*/
public class WcTestL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// source:hello flink
DataStreamSource<String> ds = env.socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String, Long>> tuple2Ds =
ds.flatMap((String s, Collector<Tuple2<String, Long>> collector) -> {
for (String world : s.split(" ")) {
collector.collect(Tuple2.of(world, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
KeyedStream<Tuple2<String, Long>, String> keyedStream = tuple2Ds.keyBy(stringTuple2 -> stringTuple2.f0);
keyedStream.sum(1).print();
env.execute();
}
}
结束
Flink数据类型