简介
对于RAG来说,将文本有效的分块(chucking)是很重要的一件事,open-parse是一个用来分块pdf的开源工具,它主要基于视觉驱动(Visually-Driven)的方式来将文档分块,也就是说它不仅仅是按照段落或者字数来对文档分块,而是在分块时将布局上属于同一个上下文的文本切分成一块。
使用入门
安装命令如下
pip install openparse
#如果要使用识别表格的算法
pip install "openparse[ml]"
#安装openparse[ml]后,使用如下命令来下载模型,大概会占用1.5G的空间
openparse-download
为了验证pdf解析效果,可下载openparse提供的示例pdf文件
wget https://sergey-filimonov.nyc3.digitaloceanspaces.com/open-parse/sample-docs/naic-numerical-list-of-companies-page-94.pdf -O sample-docs/companies-list.pdf
wget https://sergey-filimonov.nyc3.digitaloceanspaces.com/open-parse/sample-docs/mobile-home-manual.pdf -O sample-docs/mobile-home-manual.pdf
其基本使用很简单,使用DocumentParser类就可以了。
import openparse
from openparse import DocumentParser
pdf_path = "./sample-docs/mobile-home-manual.pdf"
parser = DocumentParser()
parsed_content = parser.parse(pdf_path)
for node in parsed_content.nodes:
display(node)
print("*"*20)
pdf = openparse.Pdf(pdf_path)
pdf.display_with_bboxes(
parsed_nodes.nodes,
)
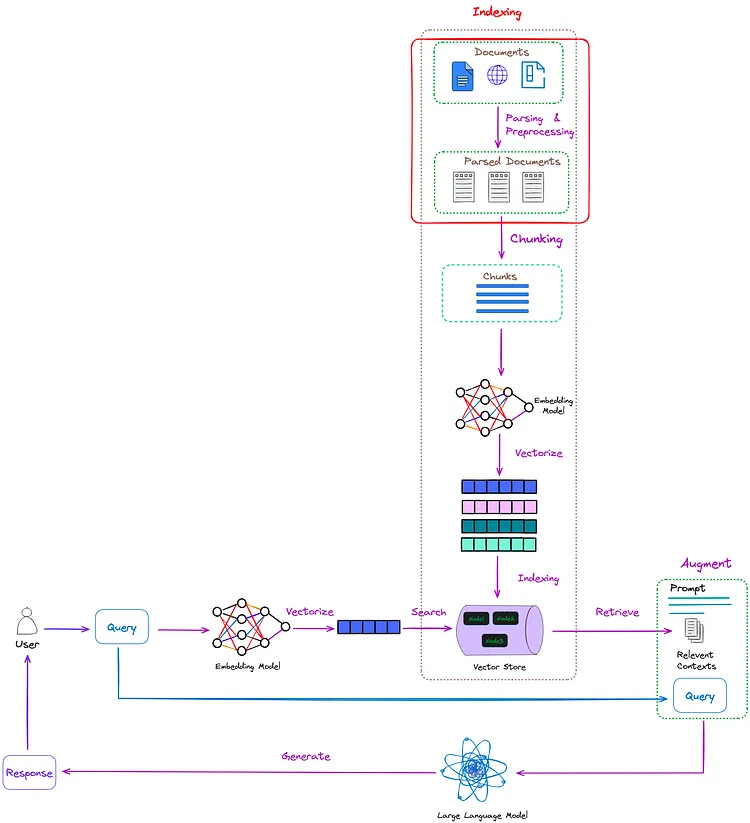
使用display以markdown形式显示解析的内容

display_with_bboxes将提取的内容在原始pdf中画框显示,这个对于debug和显示解析效果来说挺实用的。

open_parse支持设置table_args来进行表格提取,其主要有如下三个参数。
- parsing_algorithm, 用来解析表格的库,目前支持值为:pymupdf、unitable、table-transformers
- min_table_confidence,默认值为0.75,一个表格被提取的置信度分数。
- table_output_format,表格输出格式,unitable支持html、pymupdf和table-transformers支持html和markdown
pdf_path = "sample-docs/companies-list.pdf"
parser = DocumentParser(
table_args={
"parsing_algorithm": "unitable",
"min_table_confidence": 0.8}
)
parsed_content = parser.parse(pdf_path)
# 可通过node.variable来判断是否提取到表格,存在表格的话,里面会有"table" key存在
table_nodes = [node for node in parsed_nodes.nodes if "table" in node.variant]
# 也可以将提取的表格在原PDF中展示出来
doc = openparse.Pdf(file=pdf_path)
doc.display_with_bboxes(table_nodes)
将解析结果序列化
# 将结果变成字典
parsed_content.dict()
# 将结果变成json字符串
parsed_content.json()
# 将结果变成json编码字符串
parsed_content.model_dump_json()
支持自定义处理流程,参见文档
实现原理
默认使用pypdf 和 pdfminer.six来解析pdf文档,将内容划分成node,再根据一些启发式规则如将标题与接下来的内容合并、将项目列表内容合并等来对pdf内容进行分块。
另外也支持使用语义处理,其原理是将pdf解析后的node使用embedding编码,然后计算每个node之间的语义相似度,将语义相似度大于阈值且合并后不超出上下文宽度的相邻node给合并。
from openparse import processing, DocumentParser
semantic_pipeline = processing.SemanticIngestionPipeline(
openai_api_key=OPEN_AI_KEY,
model="text-embedding-3-large",
min_tokens=64,
max_tokens=1024,
)
parser = DocumentParser(
processing_pipeline=semantic_pipeline,
)
parsed_content = parser.parse(basic_doc_path)
- 表格的提取主要借助第三方包如pymupdf、unitable、table-transformers来识别pdf中的表格。
总结
测试了开源项目open-parse解析pdf文档的效果,并确认了其实现原理。实测下来感觉它对于大部分场景的分块会有帮助,但是在使用过程中也存在对于从markdown文件转成的pdf文件内容识别不是很准确(项目中也说明了存在有些pdf解析不是很准确的情况)。而对于表格提取的支持主要受限于其依赖的第三方工具或模型的表格提取能力了。此外通过embedding语义相似度来合并段落的思路也可以借鉴。
参考资料
- open-parse github
- open-parse 文档
- open-parse hacker news 讨论