5. RocketMQ消息保障
下面我们详细说下如何保障消息不丢失以及消息幂等性问题
5.1 生产端保障
生产端保障需要从一下几个方面来保障
- 使用可靠的消息发送方式
- 注意生产端重试
- 生产禁止自动创建topic
5.1.1 消息发送保障
5.1.1.1 同步发送
发送者向MQ执行发送消息API时,同步等待,直到消息服务器返回发送结果,会在收到接收方发回响应之后才发下一个数据包的通讯方式,这种方式只有在消息完全发送完成之后才返回结果,此方式存在需要同步等待发送结果的时间代价。
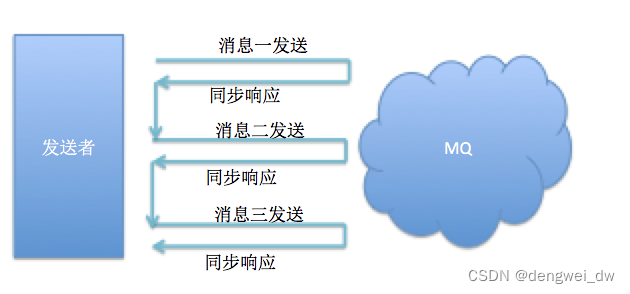
简单来说,同步发送就是指 producer 发送消息后,会在接收到 broker 响应后才继续发下一条消息的通信方式。
使用场景
由于这种同步发送的方式确保了消息的可靠性,同时也能及时得到消息发送的结果,故而适合一些发送比较重要的消息场景,比如说重要的通知邮件、营销短信等等,在实际应用中,这种同步发送的方式还是用得比较多的。
注意事项
这种方式具有内部重试机制,即在主动声明本次消息发送失败之前,内部实现将重试一定次数,默认为2次(DefaultMQProducer#getRetryTimesWhenSendFailed),发送的结果存在同一个消息可能被多次发送给broker,这里需要应用的开发者自己在消费端处理幂等性问题。
5.1.1.2 异步发送
异步发送是指发送方发出数据后,不等接收方发回响应,接着发送下个数据包的通讯方式。 MQ 的异步发送,需要用户实现异步发送回调接口(
SendCallback)

异步发送是指 producer 发出一条消息后,不需要等待 broker 响应,就接着发送下一条消息的通信方式,需要注意的是,不等待 broker 响应,并不意味着 broker 不响应,而是通过回调接口来接收 broker 的响应,所以要记住一点,异步发送同样可以对消息的响应结果进行处理。
使用场景
由于异步发送不需要等待 broker 的响应,故在一些比较注重 RT(响应时间)的场景就会比较适用,比如,在一些视频上传的场景,我们知道视频上传之后需要进行转码,如果使用同步发送的方式来通知启动转码服务,那么就需要等待转码完成才能发回转码结果的响应,由于转码时间往往较长,很容易造成响应超时,此时,如果使用的是异步发送通知转码服务,那么就可以等转码完成后,再通过回调接口来接收转码结果的响应了。
5.1.2 消息发送总结
5.1.2.1 发送方式对比
| 发送方式 | 发送 TPS | 发送结果反馈 | 可靠性 | 适用场景 |
|---|---|---|---|---|
| 同步发送 | 一般 | 有 | 不丢失 | 重要的通知场景 |
| 异步发送 | 快 | 有 | 不丢失 | 比较注重 RT(响应时间)的场景 |
| 单向发送 | 最快 | 无 | 可能丢失 | 可靠性要求并不高的场景 |
5.1.2.2 使用场景对比
在实际使用场景中,利用何种发送方式,可以总结如下:
- 当发送的消息不重要时,采用
one-way方式,以提高吞吐量;- 当发送的消息很重要是,且对响应时间不敏感的时候采用
sync方式;- 当发送的消息很重要,且对响应时间非常敏感的时候采用
async方式;
5.1.3 发送状态
发送消息时,将获得包含SendStatus的SendResult,首先,我们假设Message的isWaitStoreMsgOK = true(默认为true),如果没有抛出异常,我们将始终获得SEND_OK,以下是每个状态的说明列表:
5.1.3.1 FLUSH_DISK_TIMEOUT
如果设置了 FlushDiskType=SYNC_FLUSH (默认是 ASYNC_FLUSH),并且 Broker 没有在 syncFlushTimeout (默认是 5 秒)设置的时间内完成刷盘,就会收到此状态码。
5.1.3.2 FLUSH_SLAVE_TIMEOUT
如果设置为 SYNC_MASTER,并且 slave Broker 没有在 syncFlushTimeout 设定时间内完成同步,就会收到此状态码。
5.1.3.3 SLAVE_NOT_AVAILABLE
如果设置为 SYNC_MASTER,并没有配置 slave Broker,就会收到此状态码。
5.1.3.4 SEND_OK
这个状态可以简单理解为,没有发生上面列出的三个问题状态就是SEND_OK,需要注意的是,SEND_OK 并不意味着可靠,如果想严格确保没有消息丢失,需要开启 SYNC_MASTER or SYNC_FLUSH。
5.1.3.5 注意事项
如果收到了 FLUSH_DISK_TIMEOUT, FLUSH_SLAVE_TIMEOUT,意味着消息会丢失,有2个选择,一是无所谓,适用于消息不关紧要的场景,二是重发,但可能产生消息重复,这就需要consumer进行去重控制,如果收到了 SLAVE_NOT_AVAILABLE 就要赶紧通知管理员了。
5.1.4 MQ发送端重试保障
如果由于网络抖动等原因,Producer程序向Broker发送消息时没有成功,即发送端没有收到Broker的ACK,导致最终Consumer无法消费消息,此时RocketMQ会自动进行重试。
DefaultMQProducer可以设置消息发送失败的最大重试次数,并可以结合发送的超时时间来进行重试的处理,具体API如下:
//设置消息发送失败时的最大重试次数
public void setRetryTimesWhenSendFailed(int retryTimesWhenSendFailed) {
this.retryTimesWhenSendFailed = retryTimesWhenSendFailed;
}
//同步发送消息,并指定超时时间
public SendResult send(Message msg,
long timeout) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {
return this.defaultMQProducerImpl.send(msg, timeout);5.1.4.1 重试解惑
超时重试针对网上说的超时异常会重试的说法都是错误的
是因为下面测试代码的超时时间设置为5毫秒 ,按照正常肯定会报超时异常,但设置1次重试和3000次的重试,虽然最终都会报下面异常,但输出错误时间报显然不应该是一个级别,但测试发现无论设置的多少次的重试次数,报异常的时间都差不多。
测试代码
public class RetryProducer {
public static void main(String[] args) throws UnsupportedEncodingException, InterruptedException, RemotingException, MQClientException, MQBrokerException {
//创建一个消息生产者,并设置一个消息生产者组
DefaultMQProducer producer = new DefaultMQProducer("rocket_test_consumer_group");
//指定 NameServer 地址
producer.setNamesrvAddr("127.0.0.1:9876");
//设置重试次数(默认2次)
producer.setRetryTimesWhenSendFailed(300000);
//初始化 Producer,整个应用生命周期内只需要初始化一次
producer.start();
Message msg = new Message(
/* 消息主题名 */
"topicTest",
/* 消息标签 */
"TagA",
/* 消息内容 */
("Hello Java demo RocketMQ ").getBytes(RemotingHelper.DEFAULT_CHARSET));
//发送消息并返回结果,设置超时时间 5ms 所以每次都会发送失败
SendResult sendResult = producer.send(msg, 5);
System.out.printf("%s%n", sendResult);
// 一旦生产者实例不再被使用则将其关闭,包括清理资源,关闭网络连接等
producer.shutdown();
}
}
揭晓答案针对这个疑惑,需要查看源码,发现同步发送的时候,超时是不重试的
/**
* 说明 抽取部分代码
*/
private SendResult sendDefaultImpl(Message msg, final CommunicationMode communicationMode, final SendCallback sendCallback, final long timeout) {
//1、获取当前时间
long beginTimestampFirst = System.currentTimeMillis();
long beginTimestampPrev ;
//2、去服务器看下有没有主题消息
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
if (topicPublishInfo != null && topicPublishInfo.ok()) {
boolean callTimeout = false;
//3、通过这里可以很明显看出 如果不是同步发送消息 那么消息重试只有1次
int timesTotal = communicationMode == CommunicationMode.SYNC ? 1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() : 1;
//4、根据设置的重试次数,循环再去获取服务器主题消息
for (times = 0; times < timesTotal; times++) {
MessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName);
beginTimestampPrev = System.currentTimeMillis();
long costTime = beginTimestampPrev - beginTimestampFirst;
//5、前后时间对比 如果前后时间差 大于 设置的等待时间 那么直接跳出for循环了 这就说明连接超时是不进行多次连接重试的
if (timeout < costTime) {
callTimeout = true;
break;
}
//6、如果超时直接报错
if (callTimeout) {
throw new RemotingTooMuchRequestException("sendDefaultImpl call timeout");
}
}
}异步重试
可以通过以下代码设置异步从重试次数,默认两次
producer.setRetryTimesWhenSendAsyncFailed(2);异步重试是通过递归的方式来进行重试的
MQClientAPIImpl#sendMessageAsync
private void sendMessageAsync(... ) throws InterruptedException, RemotingException {
final long beginStartTime = System.currentTimeMillis();
.....
producer.updateFaultItem(brokerName, System.currentTimeMillis() - responseFuture.getBeginTimestamp(), false);
} catch (Exception e) {
producer.updateFaultItem(brokerName, System.currentTimeMillis() - responseFuture.getBeginTimestamp(), true);
//发送重试请求
onExceptionImpl(brokerName, msg, timeoutMillis - cost, request, sendCallback, topicPublishInfo, instance,
retryTimesWhenSendFailed, times, e, context, true, producer);
}
.....
MQClientAPIImpl#onExceptionImpl
private void onExceptionImpl(...){
//获取到当前重试次数
int tmp = curTimes.incrementAndGet();
//是否需要重试,并且重试次数小于timesTotal
if (needRetry && tmp <= timesTotal) {
...
try {
request.setOpaque(RemotingCommand.createNewRequestId());
sendMessageAsync(addr, retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance,
timesTotal, curTimes, context, producer);
} catch (InterruptedException e1) {
onExceptionImpl(retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance, timesTotal, curTimes, e1,
context, false, producer);
...
}
}5.1.4.2 重试总结
通过这段源码很明显可以看出以下几点
- 如果是异步发送默认重试次数是两次,通过递归的方式进行重试
- 对于同步而言,超时异常也是不会再去重试。
- 同步发送重试是在一个for 循环里去重试,所以它是立即重试而不是隔一段时间去重试。
5.1.5 禁止自动创建topic
5.1.5.1 自动创建TOPIC流程
autoCreateTopicEnable设置为true 标识开启自动创建topic
- 消息发送时如果根据topic没有获取到 路由信息,则会根据默认的topic去获取,获取到路由信息后选择一个队列进行发送,发送时报文会带上默认的topic以及默认的队列数量。
- 消息到达broker后,broker检测没有topic的路由信息,则查找默认topic的路由信息,查到表示开启了自动创建topic,则会根据消息内容中的默认的队列数量在本broker上创建topic,然后进行消息存储。
- broker创建topic后并不会马上同步给namesrv,而是每30进行汇报一次,更新namesrv上的topic路由信息,producer会每30s进行拉取一次topic的路由信息,更新完成后就可以正常发送消息,更新之前一直都是按照默认的topic查找路由信息。
5.1.5.2 为什么不能开启自动创建
上述 broker 中流程会有一个问题,就是在producer更新路由信息之前的这段时间,如果消息只发送到了broker-a,则broker-b上不会创建这个topic的路由信息,broker互相之间不通信,当producer更新之后,获取到的broker列表只有broker-a,就永远不会轮询到broker-b的队列(因为没有路由信息),所以我们生产通常关闭自动创建broker,而是采用手动创建的方式。
5.1.6 发端端规避
注意了,这里我们发现,有可能在实际的生产过程中,我们的 RocketMQ 有几台服务器构成的集群
其中有可能是一个主题 TopicA 中的 4 个队列分散在 Broker1、Broker2、Broker3 服务器上。
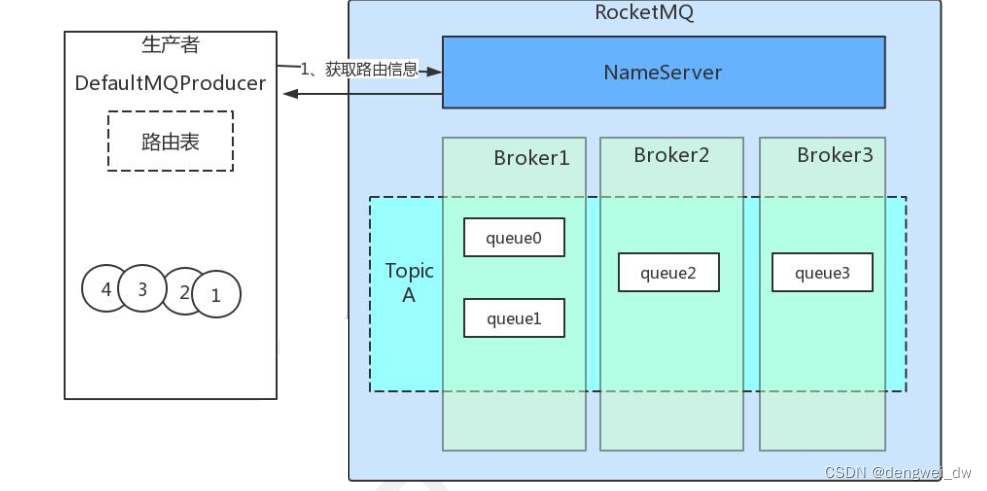
如果这个时候 Broker2 挂了,我们知道,但是生产者不知道(因为生产者客户端每隔 30S 更新一次路由,但是 NamServer 与 Broker 之间的心跳检测间隔是 10S,所以生产者最快也需要 30S 才能感知 Broker2 挂了),所以发送到 queue2 的消息会失败,RocketMQ 发现这次消息发送失败后,就会将 Broker2排除在消息的选择范围,下次再次发送消息时就不会发送到 Broker2,这样做的目的就是为了提高发送消息的成功率。
5.1.6.1 问题梳理
例如在发送之前 sendWhichQueue 该值为 broker-a 的 q1,如果由于此时 broker-a 的突发流量异常大导致消息发送失败,会触发重试,按照轮循机制,下一个选择的队列为 broker-a 的 q2 队列,此次消息发送大概率还是会失败,即尽管会重试 2 次,但都是发送给同一个 Broker 处理,此过程会显得不那么靠谱,即大概率还是会失败,那这样重试的意义将大打折扣。
故 RocketMQ 为了解决该问题,引入了故障规避机制,在消息重试的时候,会尽量规避上一次发送的 Broker,回到上述示例,当消息发往 broker-a q1 队列时返回发送失败,那重试的时候,会先排除 broker-a 中所有队列,即这次会选择 broker-b q1 队列,增大消息发送的成功率。
上述规避思路是默认生效的,即无需干预。
5.1.6.2 规则策略
但 RocketMQ 提供了两种规避策略,该参数由 sendLatencyFaultEnable 控制,用户可干预,表示是否开启延迟规避机制,默认为不开启。(DefaultMQProducer中设置这两个参数)
- sendLatencyFaultEnable 设置为 false:默认值,不开启,延迟规避策略只在重试时生效,例如在一次消息发送过程中如果遇到消息发送失败,规避 broekr-a,但是在下一次消息发送时,即再次调用 DefaultMQProducer 的 send 方法发送消息时,还是会选择 broker-a 的消息进行发送,只要继续发送失败后,重试时再次规避 broker-a。
- sendLatencyFaultEnable 设置为 true:开启延迟规避机制,一旦消息发送失败会将 broker-a “悲观”地认为在接下来的一段时间内该 Broker 不可用,在为未来某一段时间内所有的客户端不会向该 Broker 发送消息,这个延迟时间就是通过 notAvailableDuration、latencyMax 共同计算的,就首先先计算本次消息发送失败所耗的时延,然后对应 latencyMax 中哪个区间,即计算在 latencyMax 的下标,然后返回 notAvailableDuration 同一个下标对应的延迟值。
5.1.6.3 注意事项
如果所有的 Broker 都触发了故障规避,并且 Broker 只是那一瞬间压力大,那岂不是明明存在可用的 Broker,但经过你这样规避,反倒是没有 Broker 可用来,那岂不是更糟糕了?针对这个问题,会退化到队列轮循机制,即不考虑故障规避这个因素,按自然顺序进行选择进行兜底。





































![Linux基础命令[25]-groupadd](https://img-blog.csdnimg.cn/direct/f7a11027ed234eee99c585dde8883ba7.png)
