大语言模型(LLM)在面对许多应用时需要能够处理长序列输入,检索增强是处理长上下文语言建模的一种非常有效的方法。然而,现有的检索方法通常与分块的上下文一起工作,这容易导致语义表示质量低下和有用信息检索不完整。今年2月发表的《BGE Landmark Embedding: A Chunking-Free Embedding Method For Retrieval Augmented Long-Context Large Language Models》这篇论文,阐述了一种利用长上下文解决信息不完整检索的方法,通过引入Chunking-Free的检索方法,能够更好地保证上下文的连贯性,并通过在训练时引入位置感知函数来更好感知连续信息段中最后一个句子,保证嵌入依然具备与Sentence Embedding相近的细节,大幅提升了长上下文检索增强的性能。
BGE Landmark Embedding这篇论文要解决的技术问题,更具体的说,在RAG技术中,分块是个麻烦的问题,通常通过经验或启发式方法来解决。但是无论如何,分块打破上下文的连贯性,对嵌入不利,另一方面,连续的信息可能划分到不同的块中,显著的块可以很容易地被检索到,其他有用但不那么显著的块可能被忽视,等等问题。那分块有问题,但是文本太长时又不能不分块,采用滑动窗口就成为一个自然的选择。

BGE Landmark embedding有三个创新点:Chunking-Free的架构,位置感知的目标函数,多阶段训练算法。这三者环环相扣,下面依次分析。
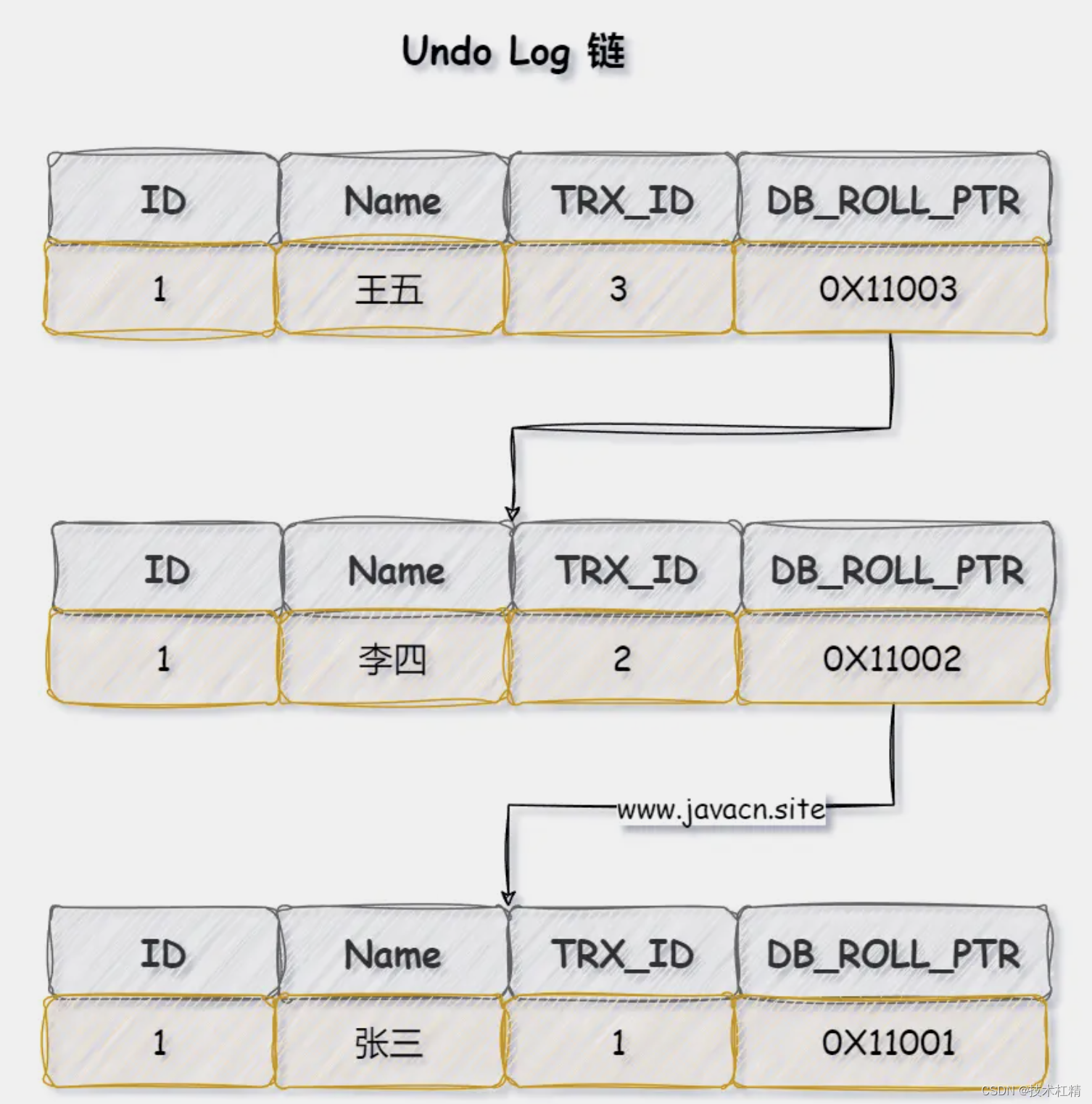
Chunking-Free架构
首先看论文中的图2,针对一个滑窗,生成滑窗的LE(landmark embedding)和查询的嵌入(query embedding),通过两者的内积计算相似度,决定查询的检索输出。

图中LEi和Query embedding的计算,见下面的公式:
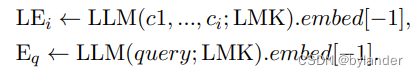
LEi的计算:c1到ci是滑动窗口中连续的句子,在句子后面增加一个特殊的token(LMK),从论文的描述看,应该是每个句子后面加一个LMK,然后通过LLM模型,embed[−1] 表示从大型语言模型(LLM)输出的嵌入向量中选择最后一个元素。
Eq(query embedding)的计算:则是在query后面增加LMK,然后通过LLM模型,选择输出的最后一个元素。
针对滑动窗口,LEi的计算公式需要修改,就是下面这个公式,l表示窗口长度。
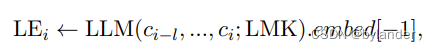
位置感知的目标函数
上述的Landmark Embedding,使用LLM作为嵌入模型,那这个嵌入模型如何训练?熟悉RAG的话就知道,通过对比学习训练查询和文本的嵌入模型。只不过,训练的损失函数需要修改一下。通常的损失函数如下:
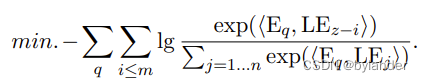
这个损失函数的问题在于,每个相关句子的Landmark被赋予同等重要性的正标签。导致的结果就是,可能让最显著的句子(例如,与查询重叠关键词最多的那个句子)获得最高的相似性。论文解决方法是强调最终边界,引入位置权重wi:wi ← exp(−α ∗ i),其中α是温度参数,来区分句子的重要性。基于位置权重,修改对比学习的损失函数——具有位置感知的目标函数,如下面的公式:
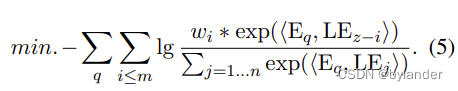
从公式可以看出,wi随着i越大变得越小。损失函数的结果是,上下文中距离查询较近的句子有更高的权重,距离较远的句子则有较低的权重。这种权重分配有助于模型更加关注与查询直接相关的信息,并且能够更好地捕捉到信息的最终边界。换句话说,越靠近查询的句子,其嵌入表示被认为与查询的相关性越高,因此在损失函数中应该得到更多的重视。通过这种方式,能够更准确地检索和表示长上下文中与查询最相关的信息。
多阶段学习
典型的嵌入模型的训练数据由成对文本组成,例如问题和答案。但是,上面对比学习的目标函数修改了,典型的训练方式就不适合训练目标了。论文作者认为Landmark Embedding的功能可以分解为两个基本能力:1)基本的语义区分能力,2)上下文化表示能力,即每个句子相对于其上下文的表示。基于这个分析,设计了多阶段学习算法,使得这两个能力可以在适当的训练数据上逐步建立。
首先,Landmark Embedding被初始化为一个通用的句子级嵌入模型。之后,作为一个上下文化表示模型得到增强,可以为其包含的句子生成有区分性的嵌入。渐进式训练分为三个步骤。
- 远程监督。首先,利用MS MARCO中的成对训练数据,基于此模型可以初始化为一个基本的句子嵌入器。在这里,Landmark Embedding采取特殊形式,只有一个单独的LMK附加在答案上下文的末尾:LEa ← LLM(answer; LMK).embed[−1]。第一阶段训练遵循密集检索的基本训练形式。
- 弱监督。在第二步中,对成对训练数据进行了简单修改,模型被训练以在长上下文中生成有区分性的句子嵌入。具体来说,随机打乱不同查询的答案,并将它们合并为一个伪长文档。第i个答案的嵌入可以生成为:LEai ← LLM(aj≠i, ..., ai; LMK).embed[−1]. 第二阶段仍然依赖于批次内负样本,其中来自其他答案的Landmark嵌入LEaj≠i被用作负样本。
- 微调。利用合成数据进行最终阶段的微调。在这一步中,利用维基百科(Foundation)的真实长文档。对于每个长文档,随机采样一系列文本跨度,通过提示LLM生成伪查询。合成数据由于调用LLM API而产生额外成本,此外,它可能与真实世界数据分布不同。因此,只有少量合成数据被生成用于最终训练阶段。然而,得益于前两个阶段建立的基本能力,Landmark Embedding在适度微调后可以实现卓越性能。
实验结果
根据论文中的实验结果部分,Landmark Embedding方法在多个方面展现出显著的优势。以下是对这些优势的详细分析:
1. 显著的性能提升:
- Landmark Embedding在各种长上下文任务中都能显著提高性能。具体来说,与基本的LLaMA-2-7B模型(没有使用检索增强)相比,在每个评估任务中都取得了一致的性能提升,平均性能提高了+8.8个百分点。
- 对于ChatGPT-3.5模型,尽管其本身已经具有较长的上下文窗口(16K),Landmark Embedding仍然能够进一步提升其性能,平均性能提高了+2.9个百分点。
2. 超越现有检索方法:
- Landmark Embedding不仅在基线模型上表现出色,而且与现有的基于分块上下文的检索方法相比,也显示出显著的优势。这意味着Landmark Embedding在处理长上下文信息时,能够更有效地检索和利用相关信息。
3. 高效的运行效率:
- 值得注意的是,Landmark Embedding在使用更少的输入Token(2,190个)的情况下,仍然能够实现比ChatGPT(使用15,500个Token)更高的性能。这表明Landmark Embedding方法在运行效率上有显著优势,能够在较低的计算成本下达到更好的性能。
4. 多文档QA任务中的卓越表现:
- 在多文档问答(multi-doc QA)任务中,Landmark Embedding一致性地超越了ChatGPT,这可能是因为在多文档场景中,有用信息更加分散,而Landmark Embedding能够更准确地识别和检索这些分散的信息。
5. 单文档QA任务中的竞争力:
- 在单文档问答(single-doc QA)任务中,Landmark Embedding在性能上与ChatGPT相当或有所提升。这表明Landmark Embedding在集中的长上下文中也能够有效地工作。
6. 检索准确性的提高:
- 论文还进行了检索准确性的实验,结果表明Landmark Embedding在合成数据集上的检索准确性远高于依赖分块上下文的基线检索器。这进一步证明了Landmark Embedding在精确检索相关信息方面的能力。
7. 对长上下文的适应性:
- Landmark Embedding的设计允许它处理任意长度的上下文,通过使用滑动窗口和特殊的LMK标记,它能够为长上下文中的每个细粒度单元生成高质量的嵌入表示。
总结来说,Landmark Embedding方法在长上下文语言建模的检索增强任务中表现出了显著的优势,这些优势包括了性能提升、运行效率、检索准确性以及对长上下文的适应性。这些结果表明Landmark Embedding是一个强大的工具,能够在多种长上下文任务中提供更准确和高效的信息检索。

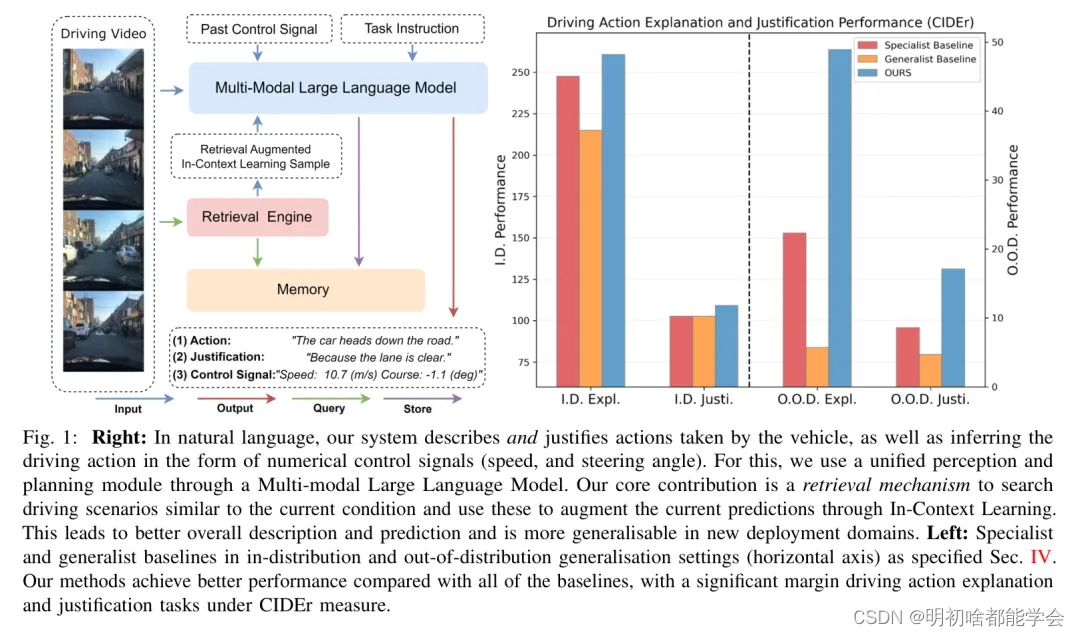



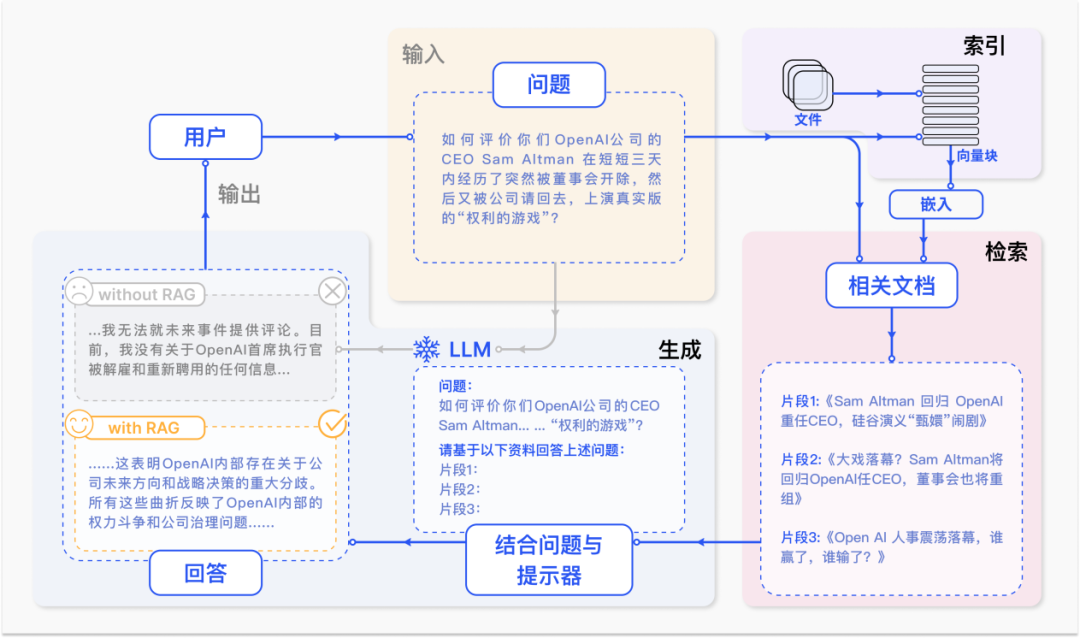
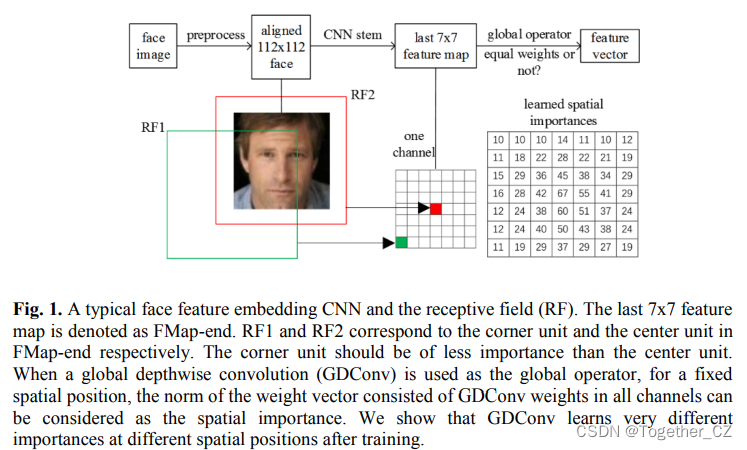




















![正点原子[第二期]ARM(I.MX6U)裸机篇学习笔记-1.2](https://img-blog.csdnimg.cn/direct/6d601889689945d0a6e5dd647ef545f1.png)
![[Swift]单元测试](https://img-blog.csdnimg.cn/direct/e0d83f4a319942c79b1d072a76f00307.png)