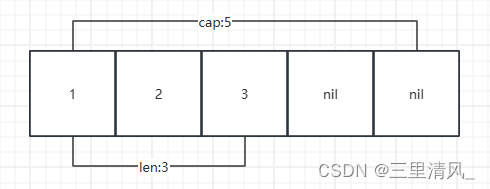
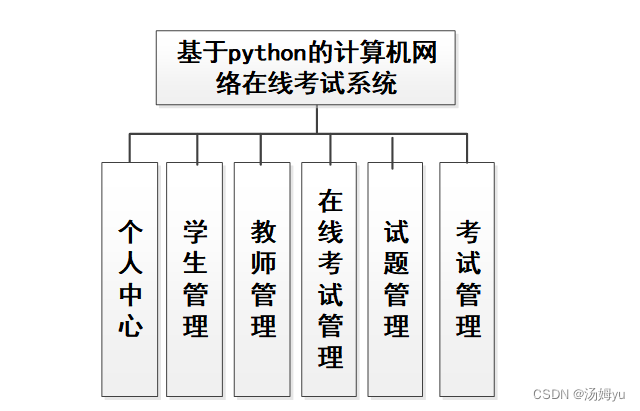
先简单介绍一下原理:

以下为用朴素贝叶斯分类预测用户满意度的python实现:
import pandas as pd
def data_to_df(data_path, test_num=100):
# 读取数据,并分割训练集和测试集
df_data = pd.read_csv(data_path, names=['buying', 'maint', 'doors', 'persons', 'lug-boot', 'safety', 'label'])
df_test = df_data.sample(n=test_num)
df_train = df_data.drop(df_test.index)
return df_train, df_test
class Bayesian_Classifier():
"""贝叶斯分类器"""
def __init__(self, df):
# prior_probability_dict:先验概率字典,记录各类别的先验概率,格式:{'unacc':概率值, 'acc': 概率值, 'good': 概率值, 'vgood': 概率值}
self.prior_probability_series = df['label'].value_counts(normalize=True)
# likelihood_probability_dict:似然概率字典,记录各类别下各特征取值的条件概率。
# 格式:{类别1: {'特征1': {'值1': 概率值, ...'值n': 概率值}, '特征2':{}...},类别2:{'特征1': {'值1': 概率值, ...'值n': 概率值}, '特征2':{}...},...}
self.likelihood_probability_dict = {
label: {column: df.loc[df['label'] == label, column].value_counts(normalize=True) for column in df.columns[:-1]}
for label in self.prior_probability_series.index}
def predict(self, feature_series):
"""预测样本的类别"""
posterior_probability_dict = {}
# 计算后验概率
for label, likelihood_probability in self.likelihood_probability_dict.items():
posterior_probability = self.prior_probability_series[label]
for feature, feature_value_probability in likelihood_probability.items():
if feature_series[feature] in feature_value_probability:
posterior_probability *= feature_value_probability[feature_series[feature]]
else:
posterior_probability *= 0
posterior_probability_dict[label] = posterior_probability
# 返回最大后验概率的类别
return max(posterior_probability_dict, key=posterior_probability_dict.get)
if __name__ == '__main__':
test_num = 100
df_train, df_test = data_to_df('car.data', test_num)
# 实例化朴素贝叶斯分类器
model = Bayesian_Classifier(df_train)
# 预测测试集
predicted_satisfaction_list = [[model.predict(row), row.label] for i, row in df_test.iterrows()]
# 计算准确率
correct_num = sum([1 for predicted, actual in predicted_satisfaction_list if predicted == actual])
accuracy = correct_num / test_num
print('accuracy:', accuracy)输入:Car Evaluation - UCI Machine Learning Repository
输出:
accuracy: 0.89