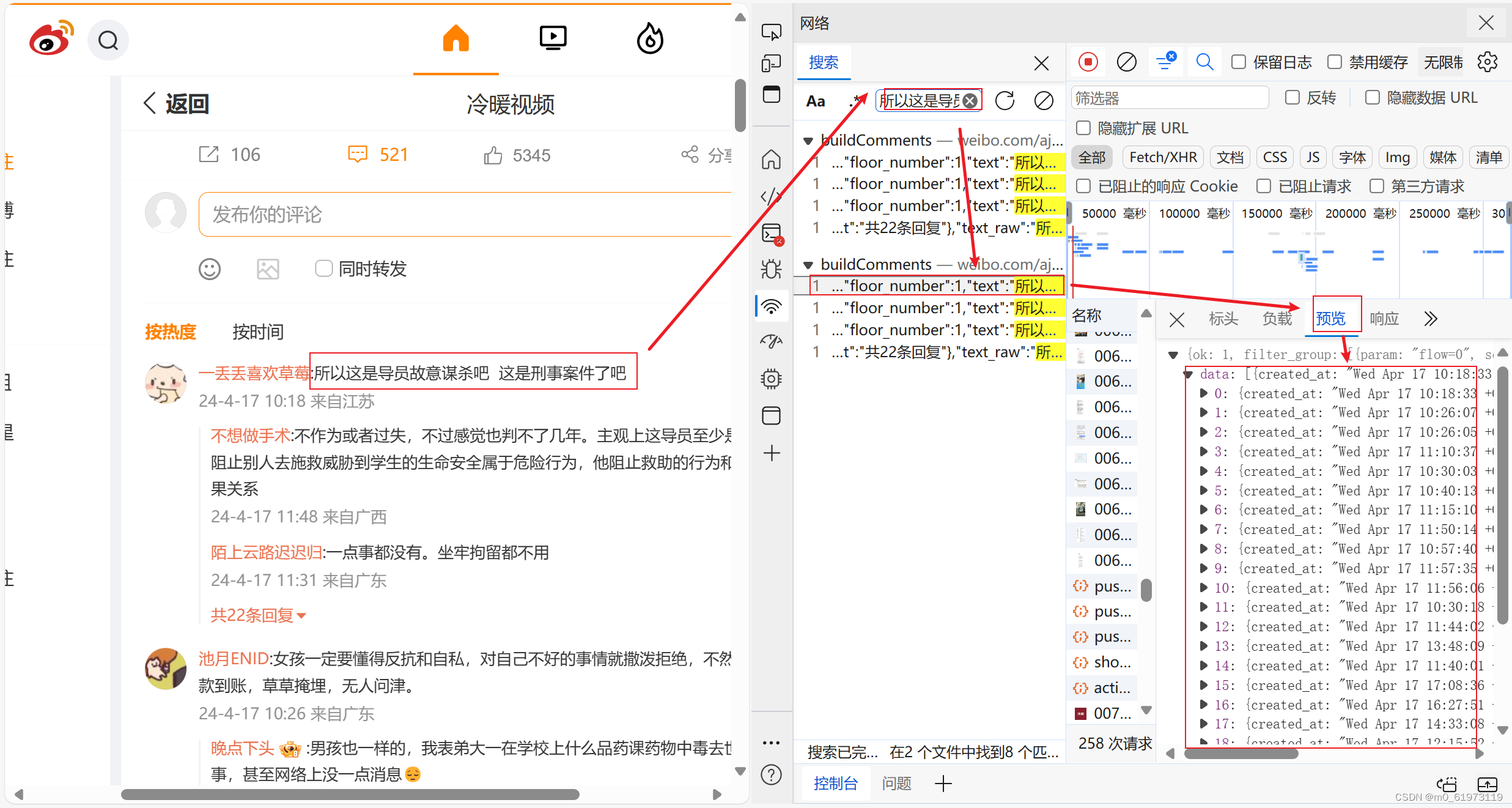
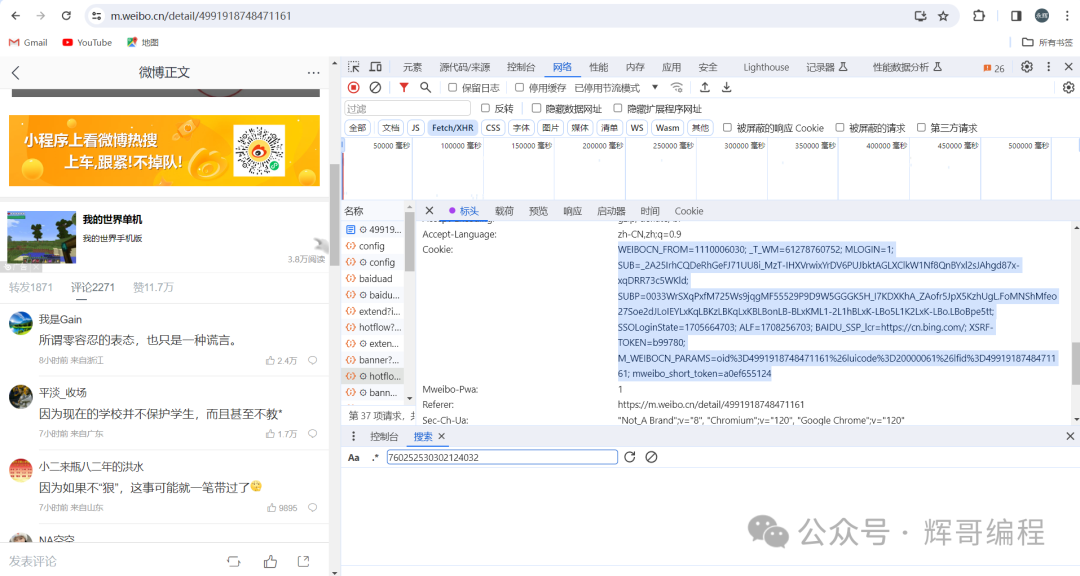
一、景点部分评价爬取
【携程攻略】携程旅游攻略,自助游,自驾游,出游,自由行攻略指南 (ctrip.com)
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
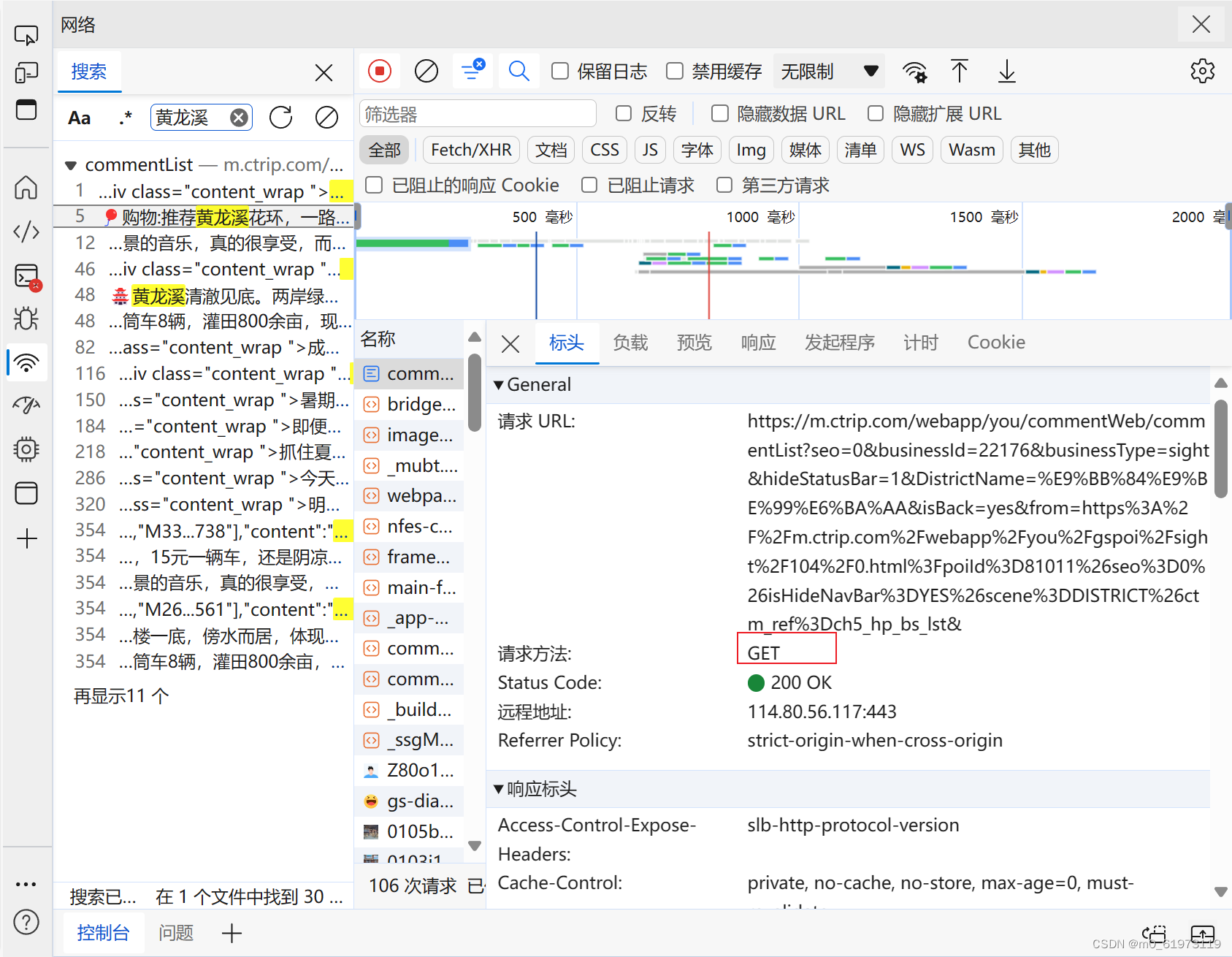
url = 'https://m.ctrip.com/webapp/you/commentWeb/commentList?seo=0&businessId=22176&businessType=sight&hideStatusBar=1&DistrictName=%E9%BB%84%E9%BE%99%E6%BA%AA&isBack=yes&from=https%3A%2F%2Fm.ctrip.com%2Fwebapp%2Fyou%2Fgspoi%2Fsight%2F104%2F0.html%3FpoiId%3D81011%26seo%3D0%26isHideNavBar%3DYES%26scene%3DDISTRICT%26ctm_ref%3Dch5_hp_bs_lst&'#目标访问网站url
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0"}
req = requests.get(url=url,headers = header)#获取该网页内容
req.encoding = 'utf-8'#防止中文乱码,还可以改成gbk
html = req.text
bes = BeautifulSoup(html,"lxml")
div_contents = bes.find_all('div', class_='content_wrap')#找到里面的所有div标签
if div_contents:
count = 1
for div_content in div_contents:
all_info = div_content.text
print(f'{count}: {all_info}')
count += 1
else:
print('未找到指定的<div class="content_wrap">标签')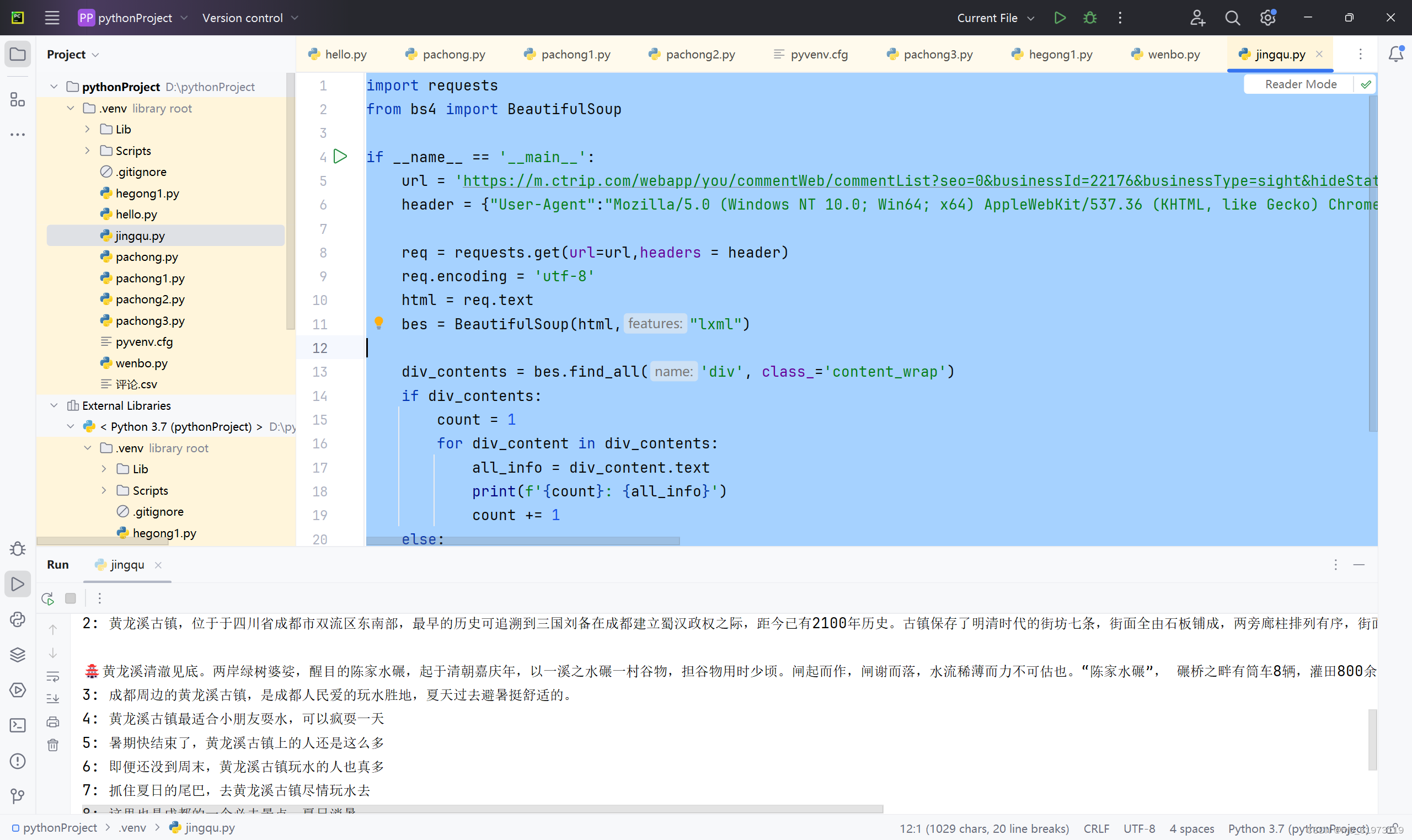
二、景点所有评价爬取
通过搜索,发现请求方法不在是get,而是post,且预览并得不到我们需要的评论,反而是响应界面才可以,则针对这种情况,我们需要重新更改代码。


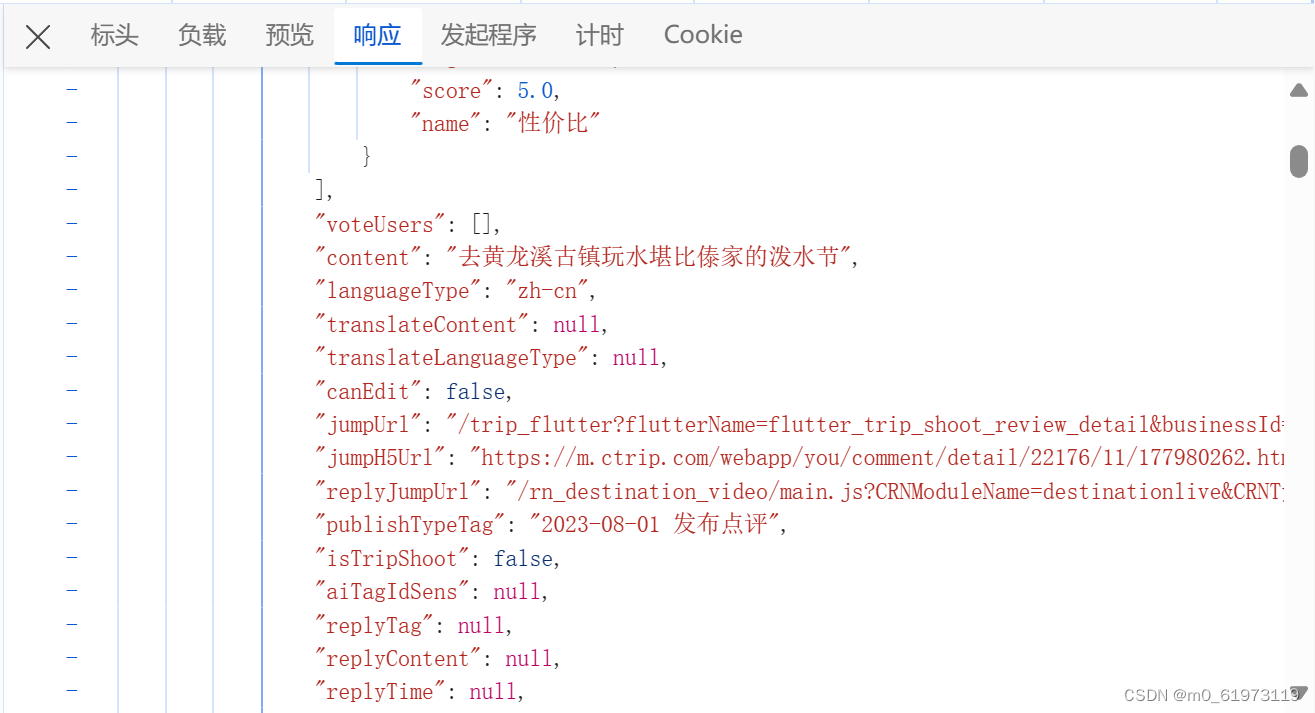
更改代码如下
import requests
import json
import pandas as pd
from tqdm import tqdm
userNames = []
commentDetails = []
commentTimes = []
total_pages = 1
for pagen in tqdm(range(0, total_pages), desc='爬取进度', unit='页'):
#payload参数实质上就是网络下的负载
payload = {
"arg": {
"channelType": 7,
"collapseTpte": 1,
"commentTagId": 0,
"pageIndex": pagen,
"pageSize": 10,
"resourceId":22176,
"resourceType":11,
"sourseType": 1,
"sortType": 3,
"starType": 0
},
"head": {
"cid": "09031081213865125571",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": []
}
}
#网络的标头中的url路径,采用POST请求方法,其?后面的内容就是payload
postUrl = "https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList"
html = requests.post(postUrl, data=json.dumps(payload)).text
html_1 = json.loads(html)#html_1实质就是网络下面的响应界面
# 检查响应中是否存在'items'
if 'items' in html_1["result"]:
commentItems = html_1["result"]["items"]
for i in range(0, len(commentItems)):
# 在访问元素之前检查当前项是否不为None
if commentItems[i] is not None and 'userInfo' in commentItems[i] and 'userNick' in commentItems[i][
'userInfo']:
userName = commentItems[i]['userInfo']['userNick']
commentDetail = commentItems[i]['content']
commentTime = commentItems[i]['publishTypeTag']
userNames.append(userName)
commentDetails.append(commentDetail)
commentTimes.append(commentTime)
# 创建 DataFrame
df = pd.DataFrame({
'用户评论内容': commentDetails,
'用户名': userNames,
'用户评论时间': commentTimes
})
# 保存到 Excel 文件
df.to_excel('只爬黄龙溪评论1223url.xlsx', index=False, encoding='utf-8')

三、不同景点所有评价爬取

可以看出,不同景点的resourceId不一样,即更改diamagnetic中的resourceId的数字即可

四、URL编码很乱如何解码

UrlEncode编码/UrlDecode解码 - 站长工具 (chinaz.com)

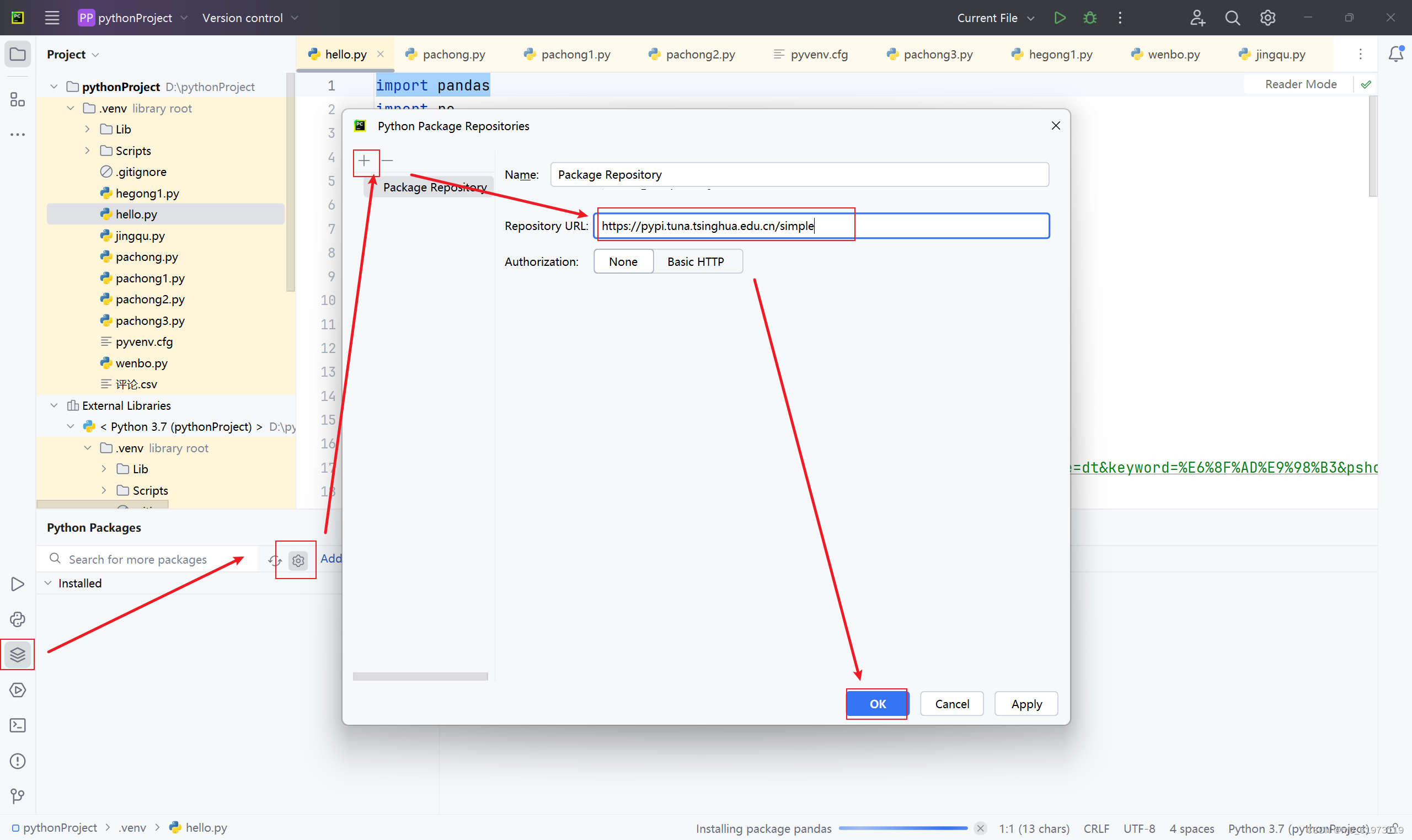
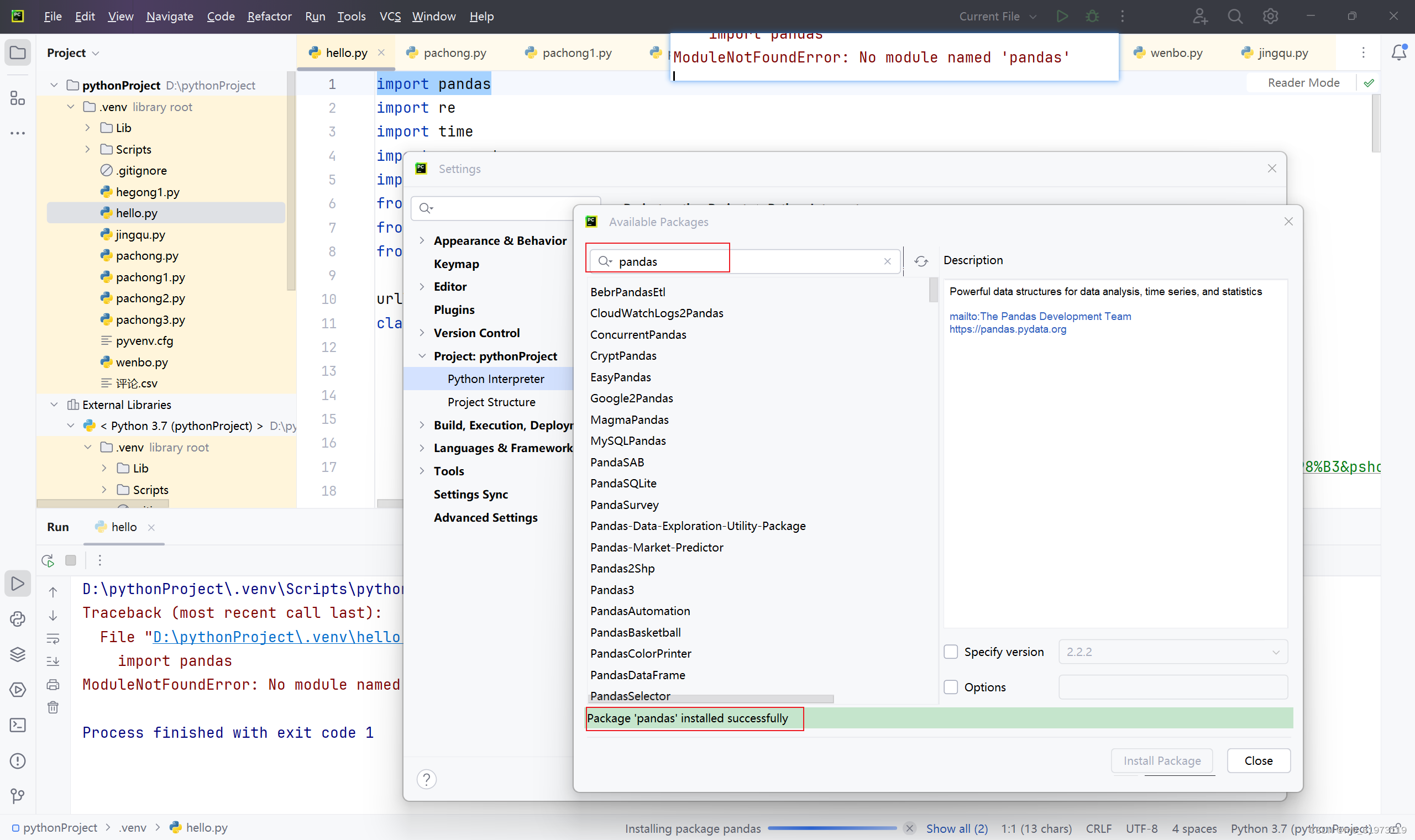
五、No module named 'pandas'问题解决
ModuleNotFoundError: No module named 'pandas'
常用源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/