Py_spark实战
介绍

 基础准备
基础准备 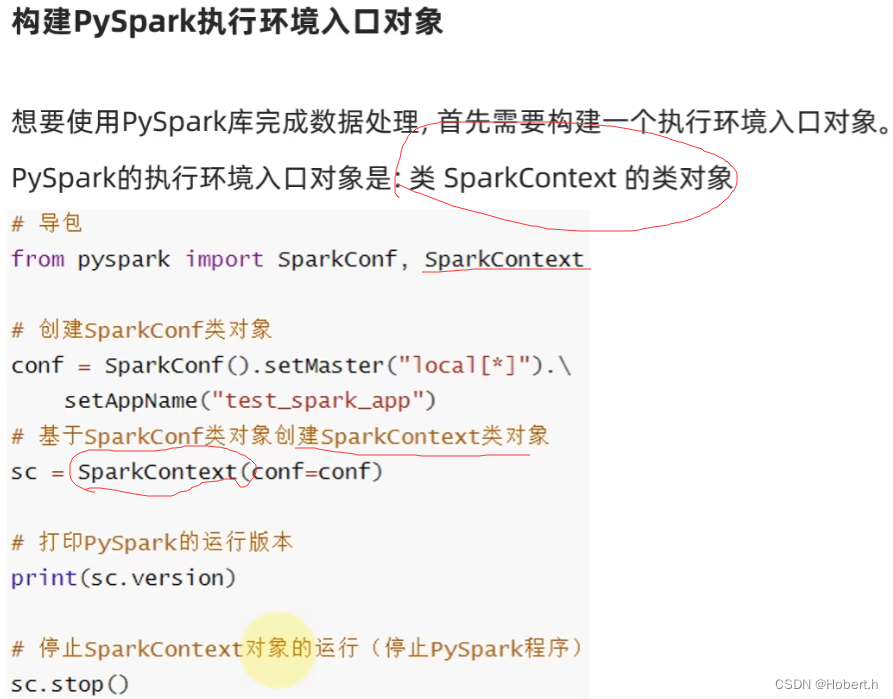

链式调用的原则是不管调用什么方法,返回值得到的都是同一个对象
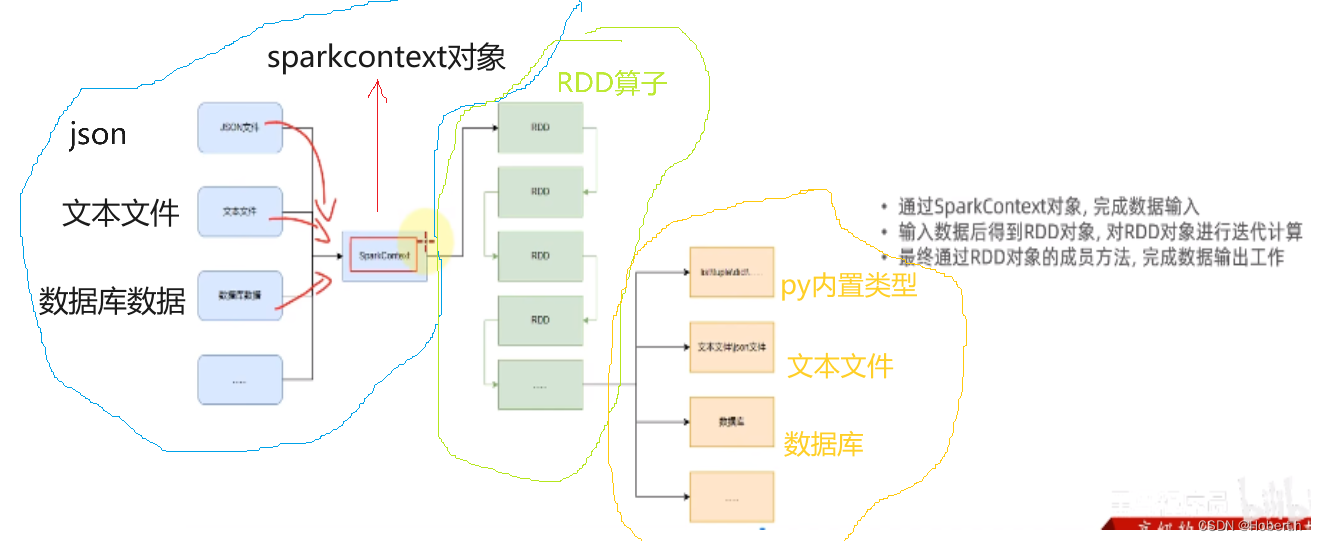

数据输入 (得到RDD对象)
RDD是一种数据集,里面包含了非常多的元素,是Pyspark数据计算的载体,就跟python 里的数据容器差不多
数据输入到spark中一定是RDD形式的
(1)利用parallelize方法

from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
#通过parallelize方法将python对象加载到Spark内,成为RDD对象
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize({1,2,3,4,5})
rdd3 = sc.parallelize("Akebi")
rdd4 = sc.parallelize({"key1":"value1","key2":"value2"})
rdd5 = sc.parallelize((1,2,3,4,5))
#通过collect方法查看RDD里面有什么内容
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
sc.stop()(2)直接读取文本文件
还可以通过直接查看文件,将文件的内容加载到spark中成为RDD

from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
rdd = sc.textFile("D:/Akebi.txt")#利用textfile方法,读取文件数据到spark中,成为RDD对象
print(rdd.collect())
sc.stop()数据计算
map

(T)->U:(T)表示 接收一个传入参数,U代表返回值,即函数可以接收一个参数的传入。并可以产生一个返回值,T和U都是范型
(T)->T:表示传入什么类型,返回就必须是什么类型
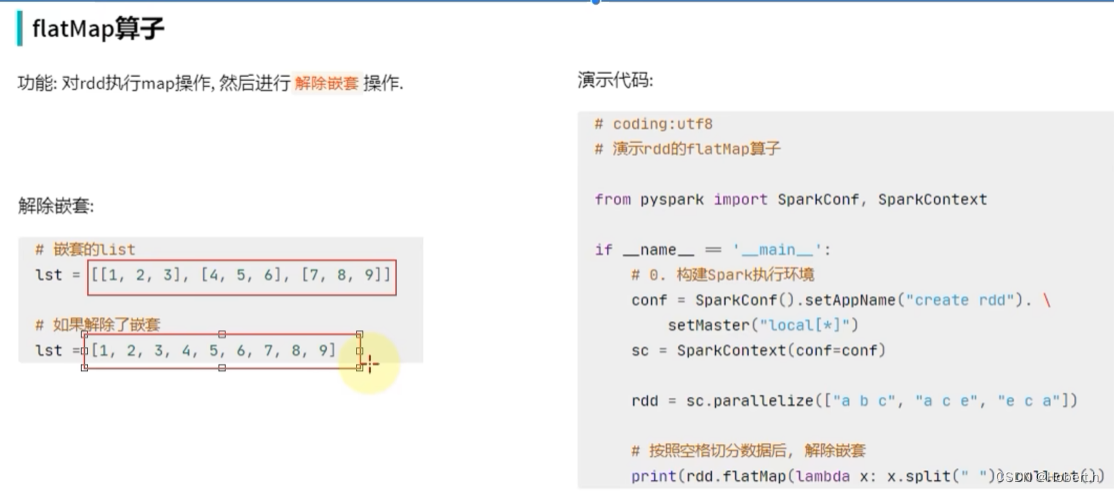
flatMap
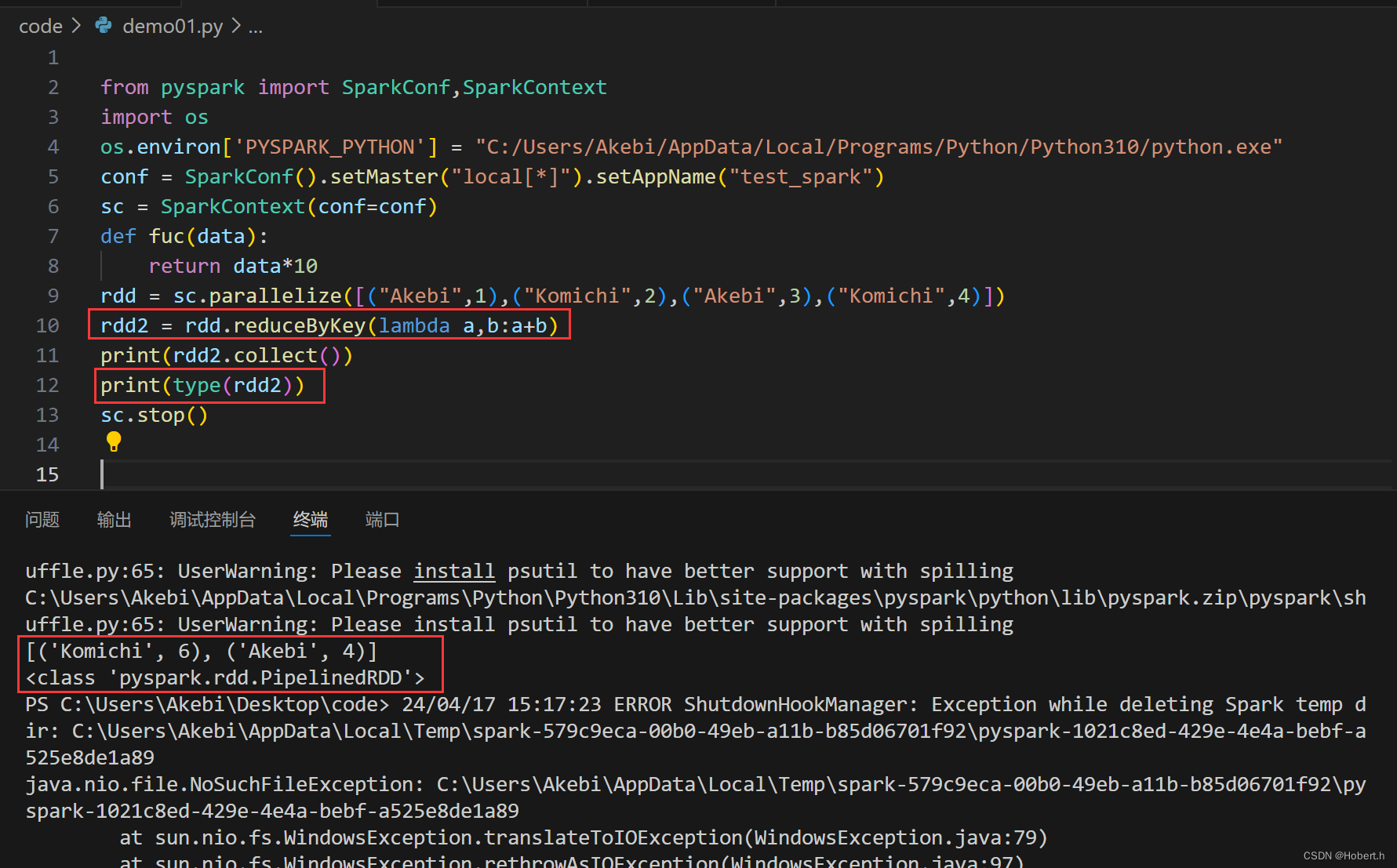
reduceByKey
按照key来进行分组,分组完后进行两两聚合

案例
实现统计单词出现的次数
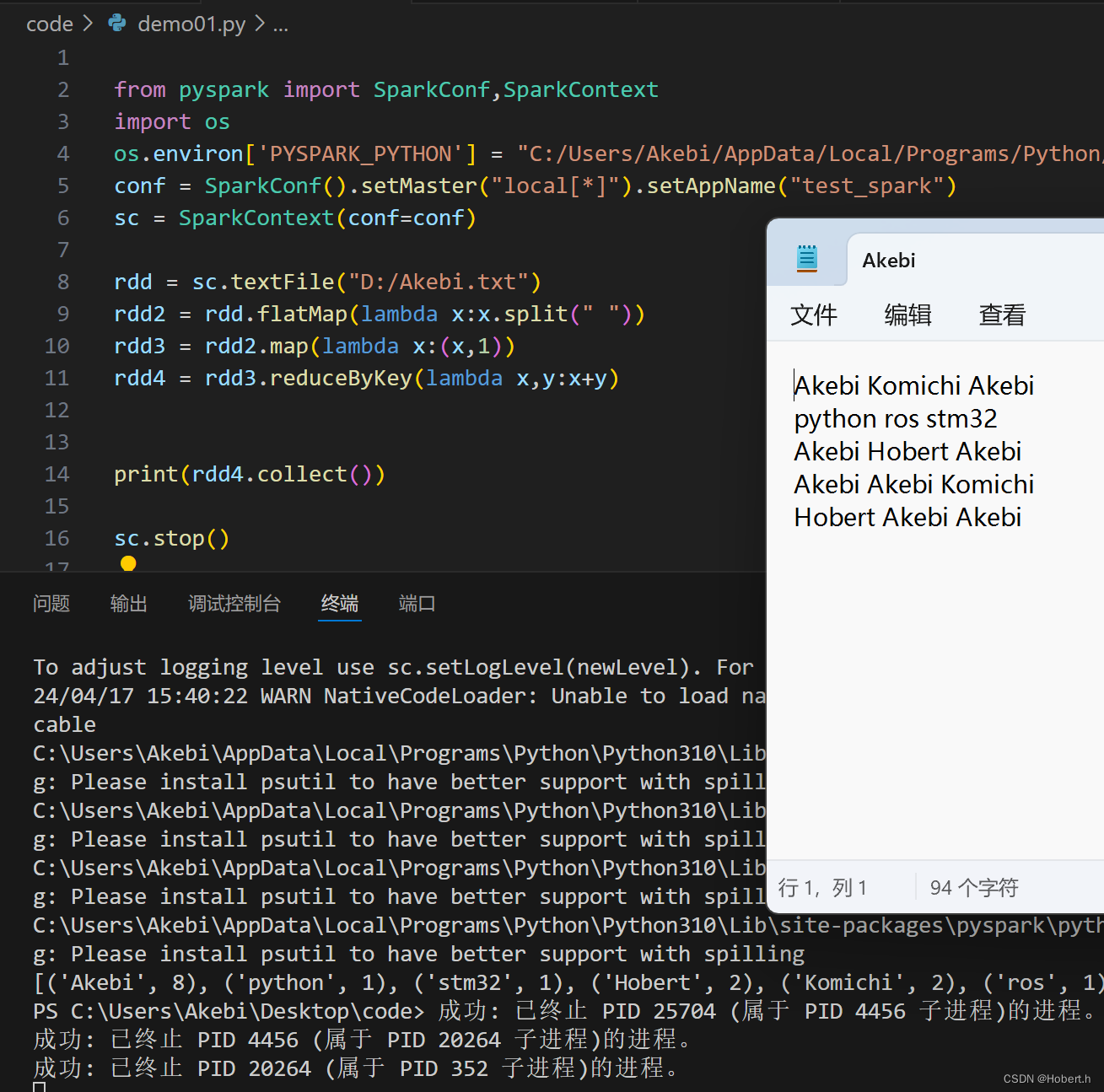
filter
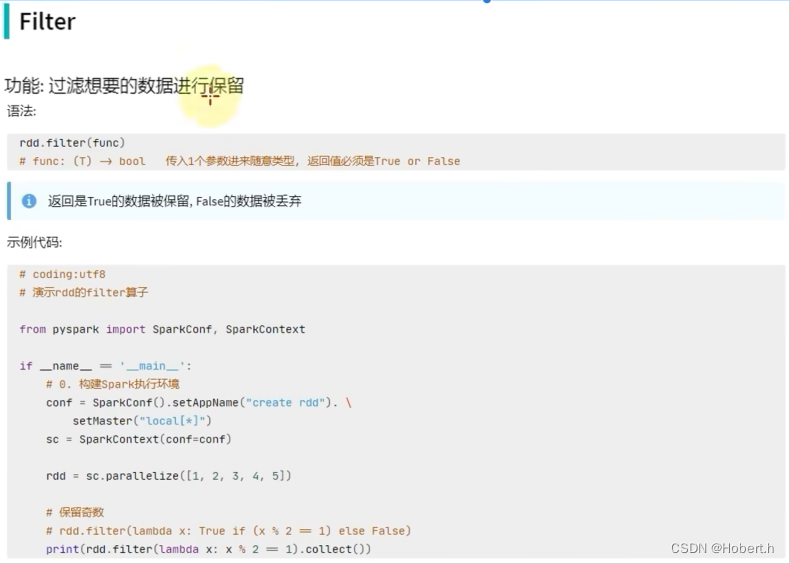
接收一个处理函数,对RDD数据逐个进行处理
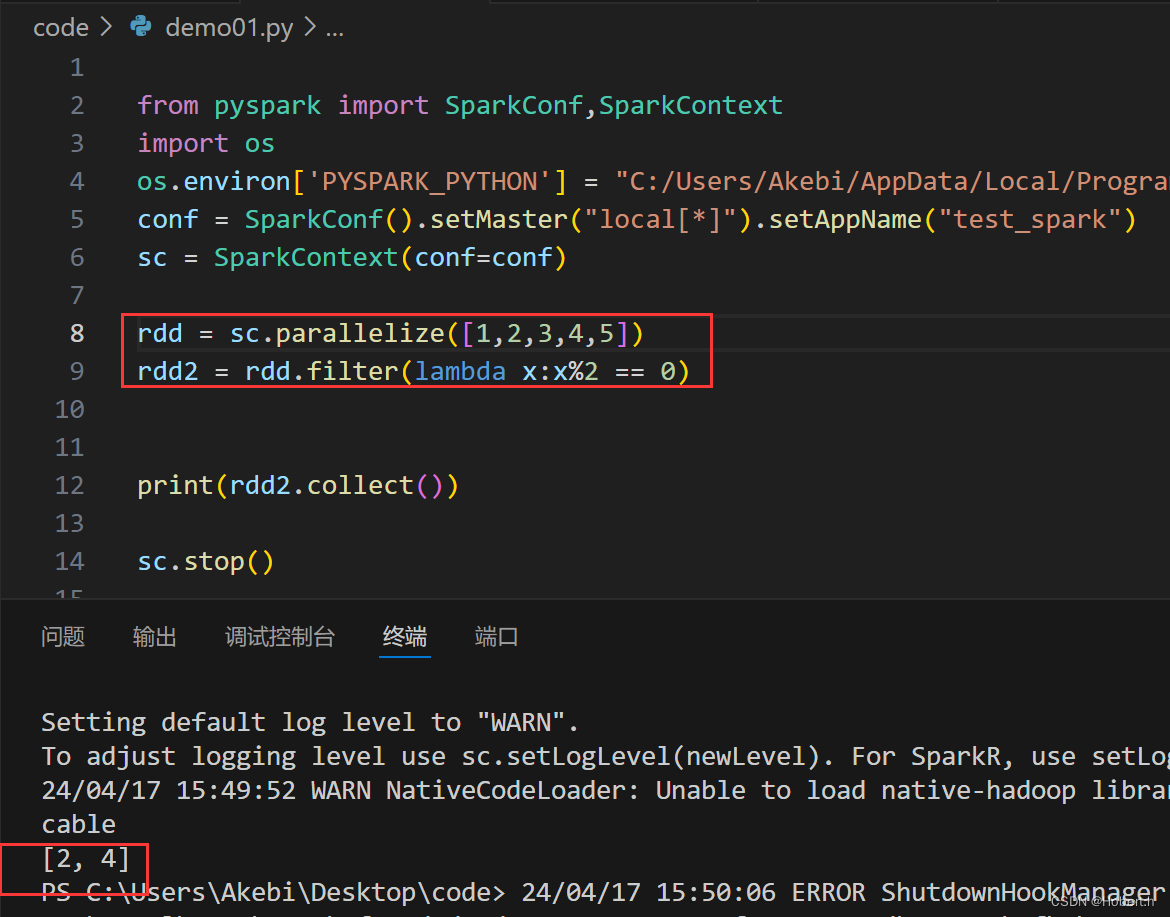 distinct
distinct

sortBy
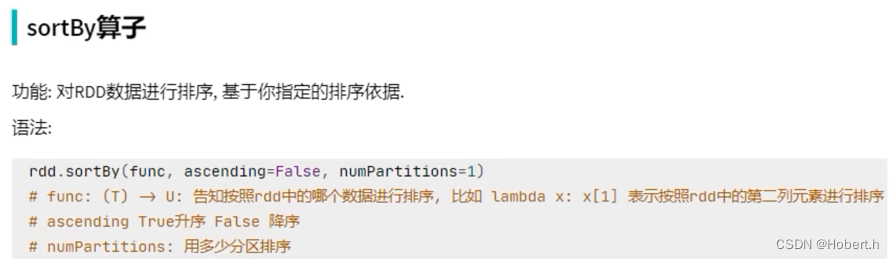

ascend:上升
RDD是带有分区的数据集
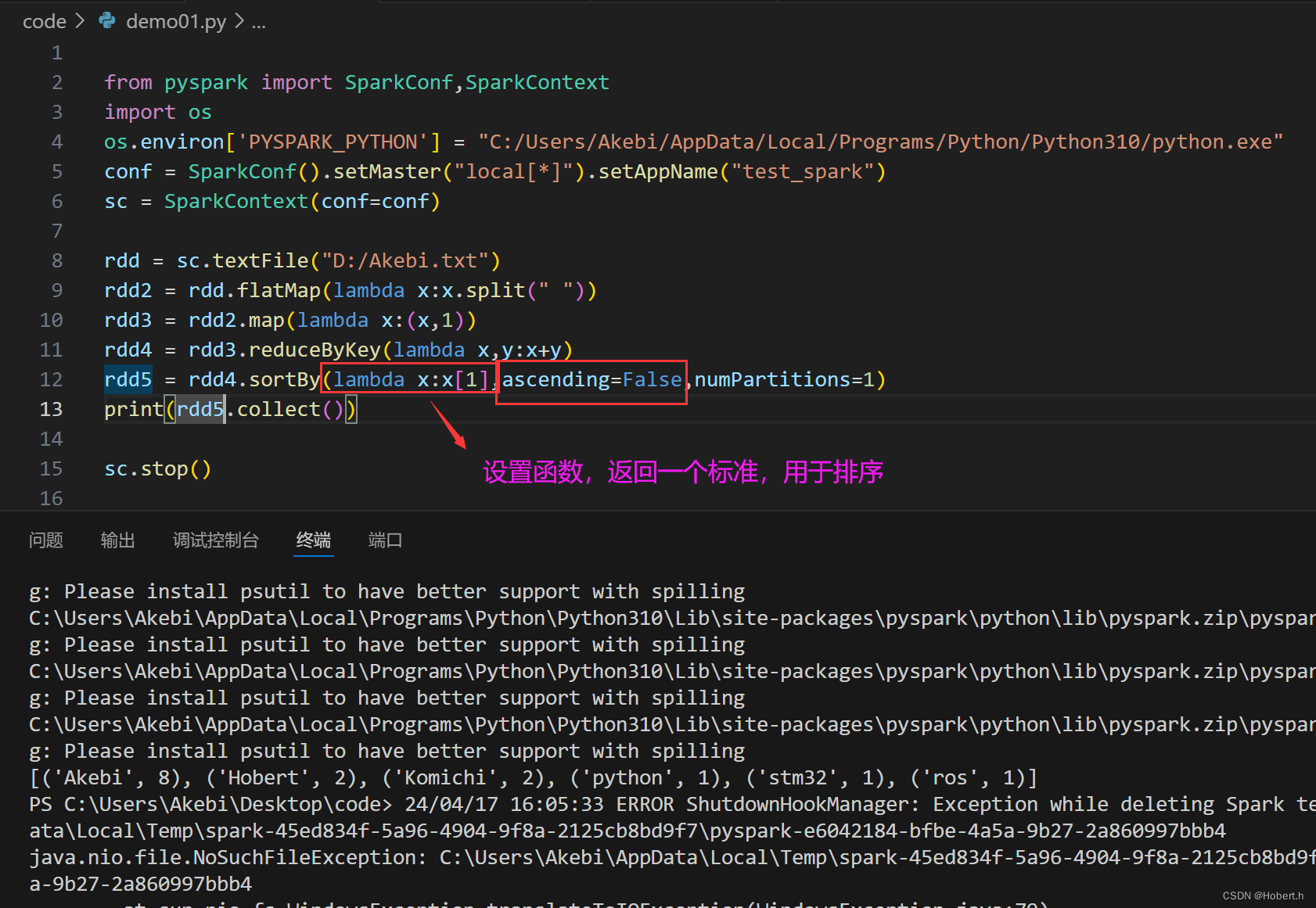
案例
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = "C:/Users/Akebi/AppData/Local/Programs/Python/Python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
rdd = sc.textFile("D:/Spark.txt")#读取文件
rdd2 = rdd.flatMap(lambda x:x.split("|")).map(lambda x:json.loads(x))#转化为python字典
rdd3 = rdd2.map(lambda x:(x["areaName"],int(x["money"])))#提取二元元组
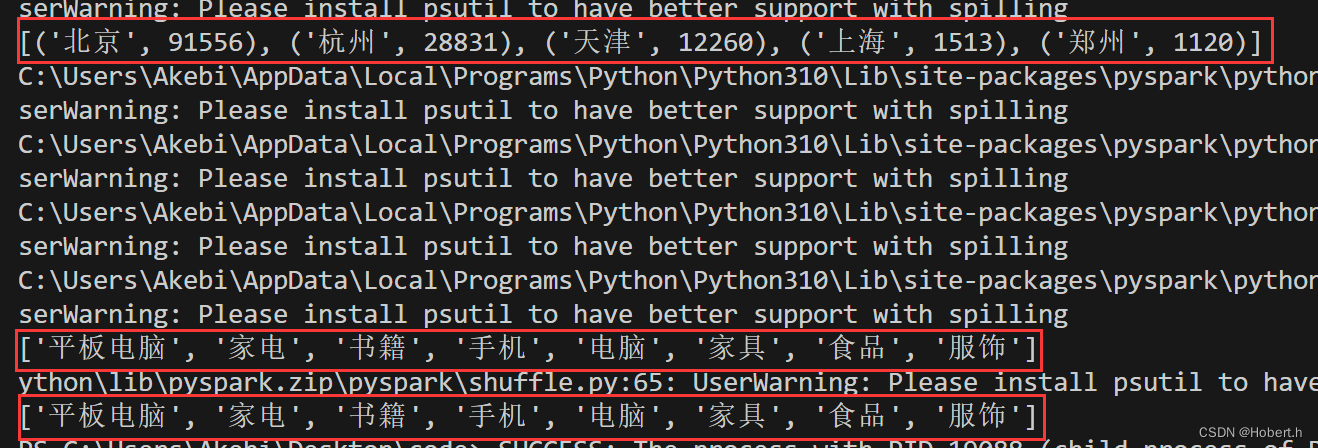
rdd4 = rdd3.reduceByKey(lambda x,y:x+y).sortBy(lambda x:x[1],ascending=False,numPartitions=1)#聚合,排序
print(rdd4.collect())
rdd5 = rdd2.map(lambda x:x["category"]).distinct()#提取类别,去重
print(rdd5.collect())
rdd6 = rdd2.filter(lambda x:x["areaName"] == "北京").map(lambda x:x["category"]).distinct()
print(rdd6.collect())
sc.stop()
数据输出
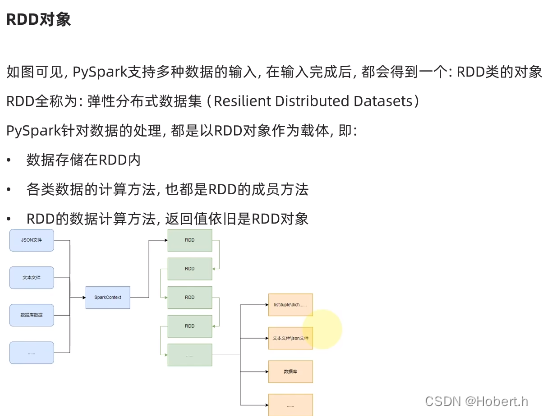
将RDD转变为python对象

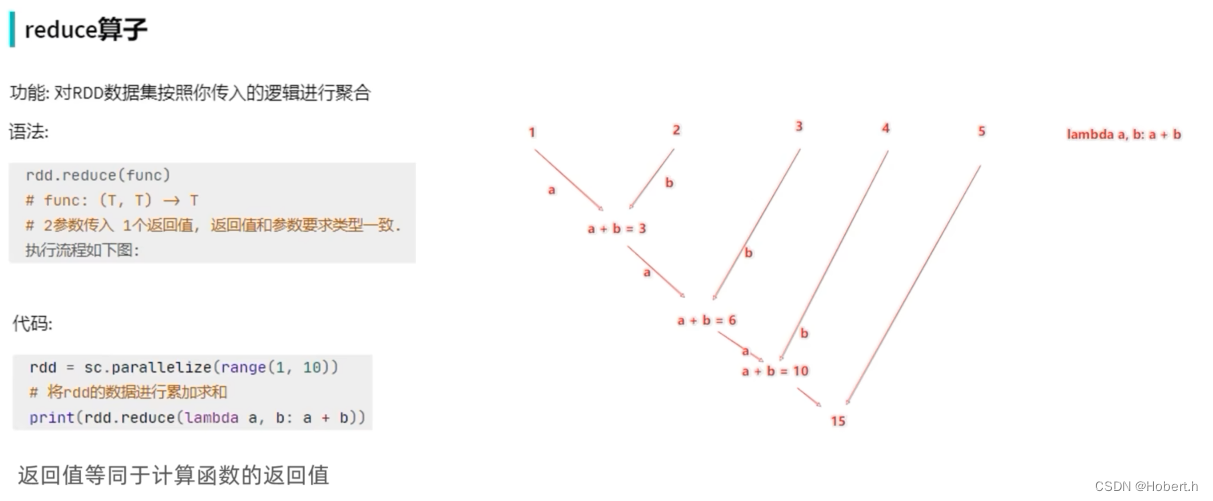 按照传入的全部数据进行两两聚合
按照传入的全部数据进行两两聚合


输出到文件中

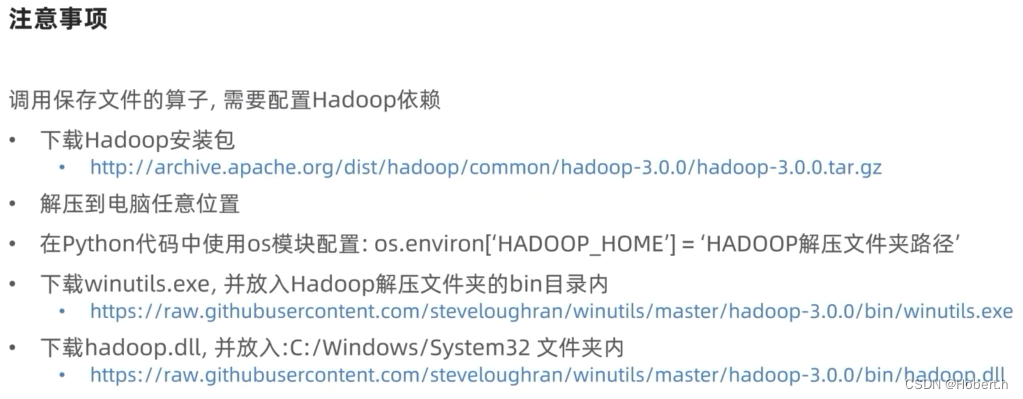
为使saveAsTextFile方法正常工作需要配置相关的依赖
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = "C:/Users/Akebi/AppData/Local/Programs/Python/Python310/python.exe"
os.environ['HADOOP_HOME'] = "C:/Users/Akebi/Desktop/pythondata/hadoop-3.0.0"
#注意vscode的python版本的选择要与路径设置的一致
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize([("Akebi",2),("Komichi",3)])
rdd3 = sc.parallelize([[1,2,3],[3,4,5],[9,8,0]])
rdd1.saveAsTextFile("D:/out1")
rdd2.saveAsTextFile("D:/out2")
rdd3.saveAsTextFile("D:/out3")
sc.stop()
 set,设置其属性值,将数据存储在一个文本文件中
set,设置其属性值,将数据存储在一个文本文件中
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = "C:/Users/Akebi/AppData/Local/Programs/Python/Python310/python.exe"
os.environ['HADOOP_HOME'] = "C:/Users/Akebi/Desktop/pythondata/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
conf.set("spark.default.parallelism","1")
#将数据存储在一个文件当中
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize([("Akebi",2),("Komichi",3)])
rdd3 = sc.parallelize([[1,2,3],[3,4,5],[9,8,0]])
rdd1.saveAsTextFile("D:/out1")
rdd2.saveAsTextFile("D:/out2")
rdd3.saveAsTextFile("D:/out3")
sc.stop()综合案例
想将数据转换为json ,最好先将其转换为字典,在转换为字典
对于Spark而言,只要将数据转换为字典,写入文件,就是json 格式
from pyspark import SparkConf,SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = "C:/Users/Akebi/AppData/Local/Programs/Python/Python310/python.exe"
os.environ['HADOOP_HOME'] = "C:/Users/Akebi/Desktop/pythondata/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("C:/Users/Akebi/Desktop/pythondata/search_log.txt")
result1 = rdd1.map(lambda x:x.split("\t")).map(lambda x:x[0][:2]).\
map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).take(3)
result2 = rdd1.map(lambda x:(x.split("\t")[2],1)).reduceByKey(lambda x,y:x+y).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).take(3)
result3 = rdd1.map(lambda x:x.split("\t")).filter(lambda x:x[2]=="黑马程序员").\
map(lambda x:(x[0][:2],1)).reduceByKey(lambda x,y:x+y).sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(1)
result4 = rdd1.map(lambda x:x.split("\t")).map(lambda x:{"key1":x[0],"key2":x[1],"key3":x[2],"key4":x[3],"key5":x[4],"key6":x[5]}).saveAsTextFile("D:/Hobert&Akebi.json")
print(result1)
print(result2)
print(result3)
sc.stop()
分布式集群运行
这里略了,看看就行
Python进阶
闭包
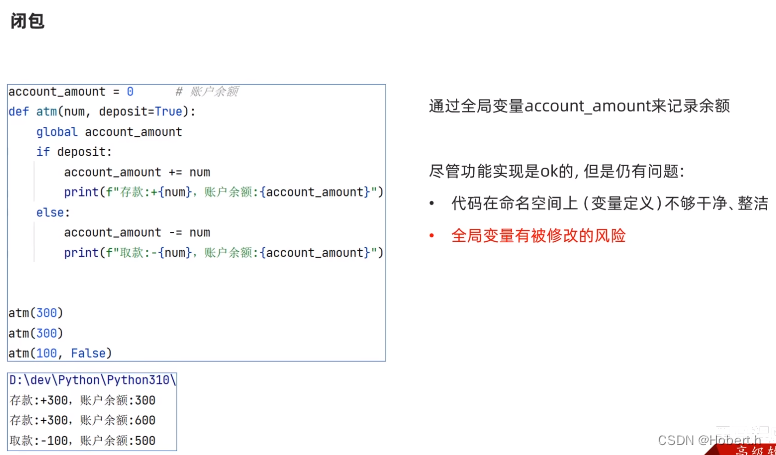
目的:即依赖全局变量,但又不想全局变量被修改到
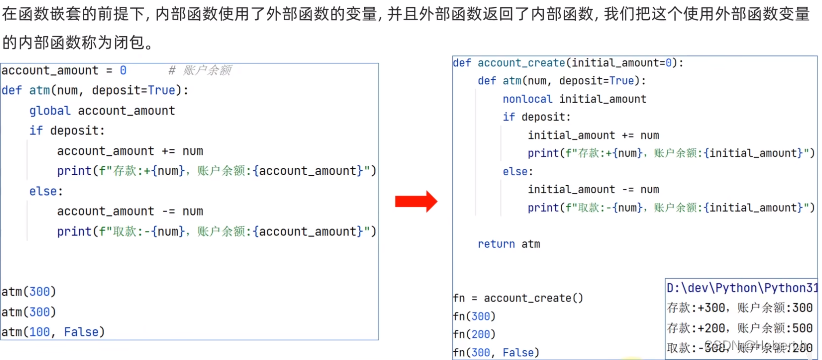
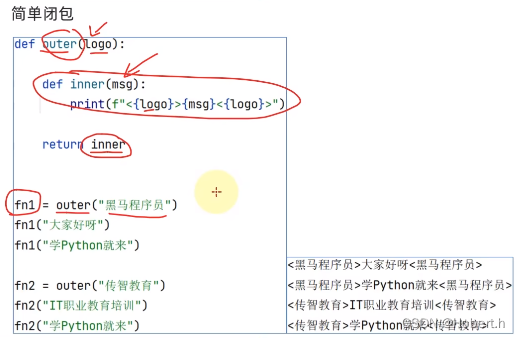
可以让内部函数去依赖外部变量
用变量接收的内部函数可以叫作闭包函数

def out(logo = 0):
def inner(data,Flag = True):
nonlocal logo
if Flag :
logo += data
print(f"存款:{logo}")
else:
logo -= data
print(f"存款:{logo}")
return inner
fuc = out()
fuc(100)
fuc(80,Flag=False)

装饰器

def sleep():
import time
import random
print("我要睡觉了")
time.sleep(random.randint(1,5))
def out(fuc):
def inner():
print("AKebi seki")
fuc()
print("AKebi seki")
return inner
fuc = out(sleep)
fuc()

设计模式

单例模式


工厂模式


多线程


import time
import threading
def Akebi():
while 1:
print("Akebi seki")
time.sleep(1)
def Komichi():
while 1:
print("Komichi seki")
time.sleep(1)
if __name__ == "__main__":
Akebi_thread = threading.Thread(target=Akebi)
Komichi_thread = threading.Thread(target=Komichi)
Akebi_thread.start()
Komichi_thread.start()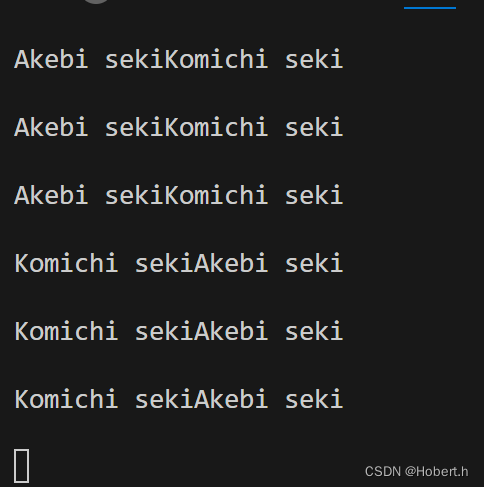
import time
import threading
def Akebi(msg):
while 1:
print(msg)
time.sleep(1)
def Komichi(msg):
while 1:
print(msg)
time.sleep(1)
if __name__ == "__main__":
Akebi_thread = threading.Thread(target=Akebi,args="Akebi seki")
Komichi_thread = threading.Thread(target=Komichi,kwargs={"msg":"Komichi seki"})
Akebi_thread.start()
Komichi_thread.start()网络编程
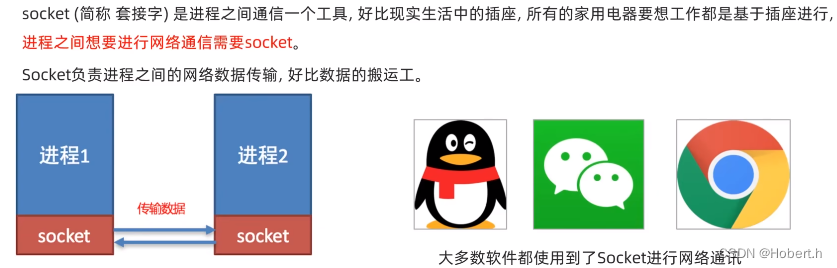
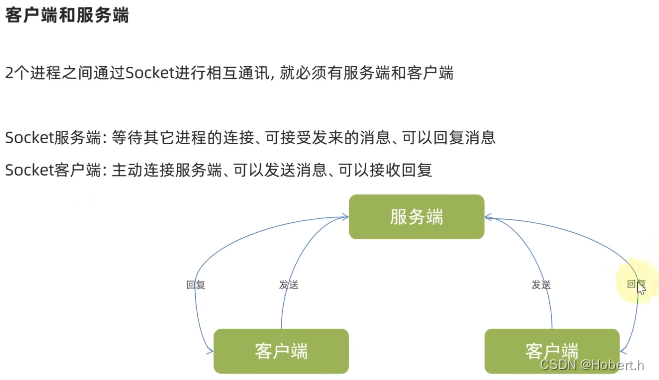


服务端开发
import socket
socket_server = socket.socket()#创建socket对象
socket_server.bind(("localhost",8888))#绑定IP地址和端口
socket_server.listen()
result = socket_server.accept()
conn = result[0] #客户端和服务端的连接对象
address = result[1] #客户端的地址信息
#上面3行也可以写成conn,address = socket_server.accept(),可以用这种形式直接接收两个元素
#accept()返回的是二元元组(连接对象,客户端地址信息)
#是一组阻塞的方法,等待客户端的连接。如果没有连接,就卡在这一行不向下执行了
while 1:#放入循环实现不断地发送和接收
data = conn.recv(1024).decode("UTF-8")
#接收客户端发送的数据
#recv接收的对象参数是缓冲区的大小,一般给1024即可
#进行UTF-8解码
print(f"发来的消息是{data}")
msg = input("输入回复消息")
if msg == 'exit':
break
conn.send(msg.encode("UTF-8"))#给客户端回复消息,将数据编码为字节数组
conn.close()
socket_server.close()客户端开发
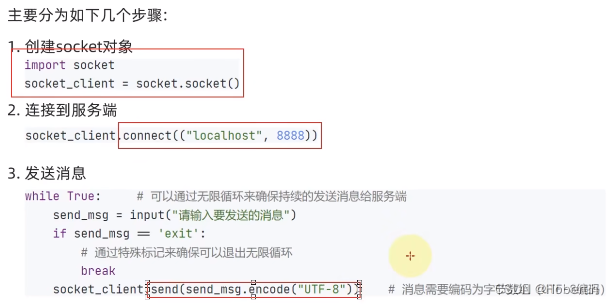
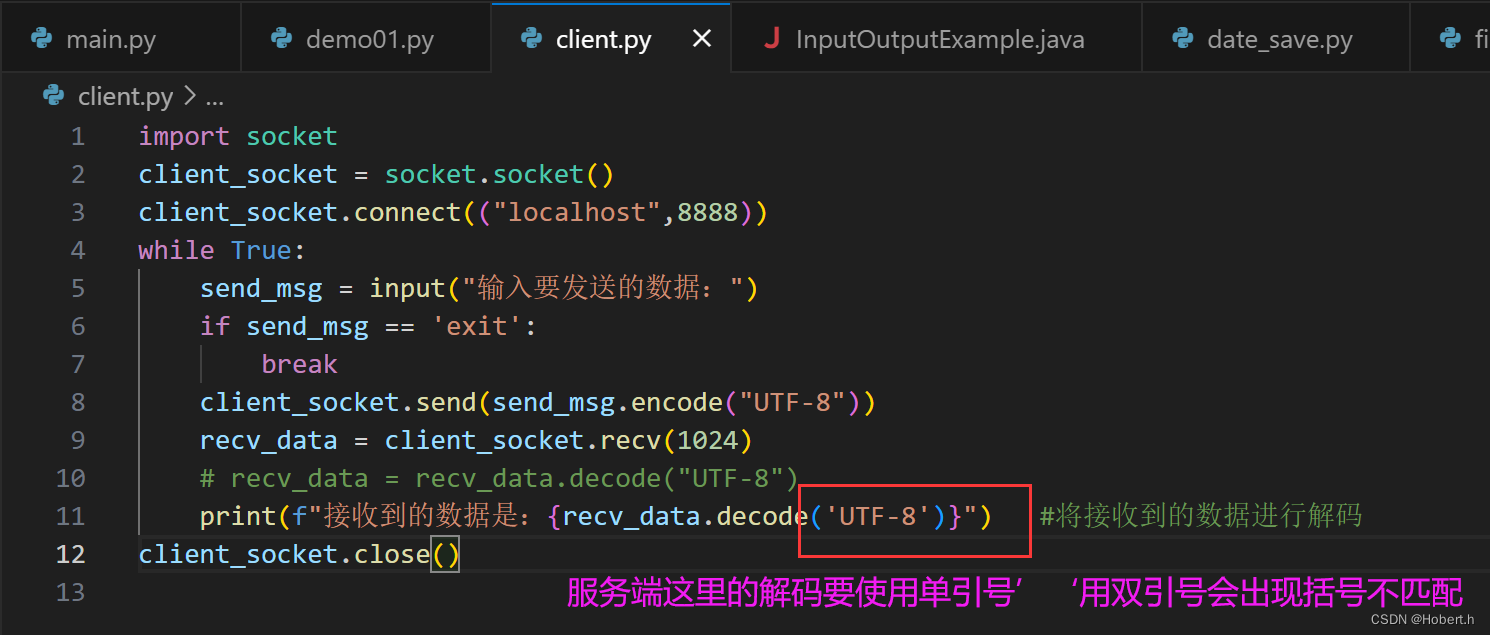
import socket
client_socket = socket.socket()
client_socket.connect(("localhost",8888))
while True:
send_msg = input("输入要发送的数据:")
if send_msg == 'exit':
break
client_socket.send(send_msg.encode("UTF-8"))
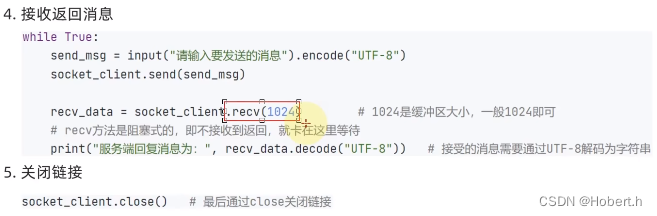
recv_data = client_socket.recv(1024)
# recv_data = recv_data.decode("UTF-8")
print(f"接收到的数据是:{recv_data.decode('UTF-8')}") #将接收到的数据进行解码
client_socket.close()
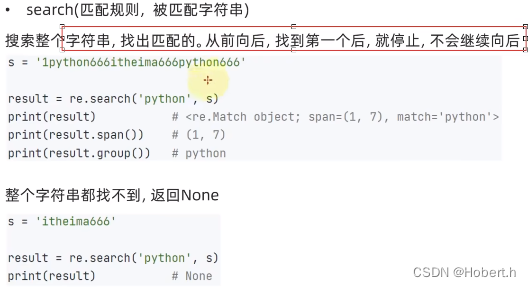
正则表达式

开头不匹配,默认后面也不匹配
(0,6)表示从0开始,不包含6
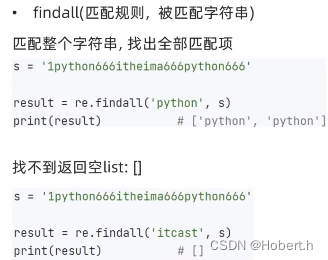
元字符匹配


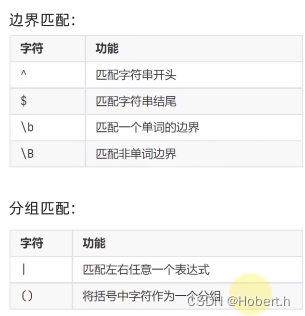
^...$:表示从头开始到尾结束的意思,可以明确取字符串的子串或是整体
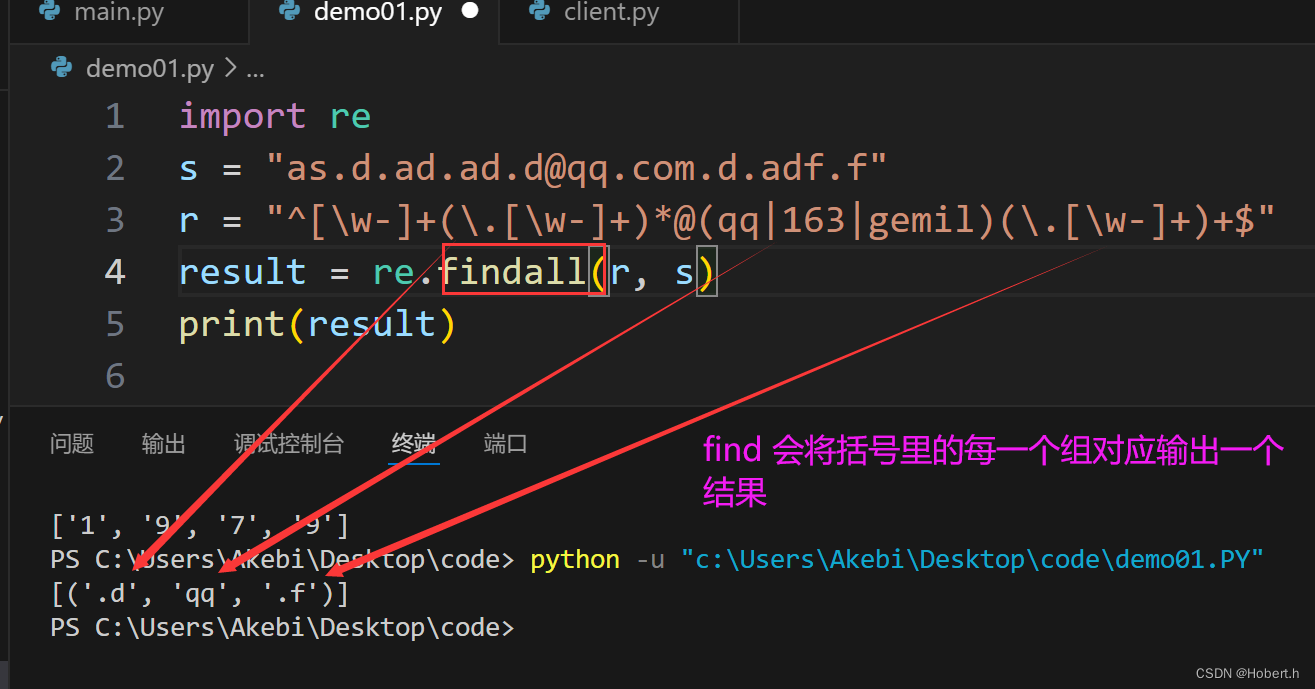
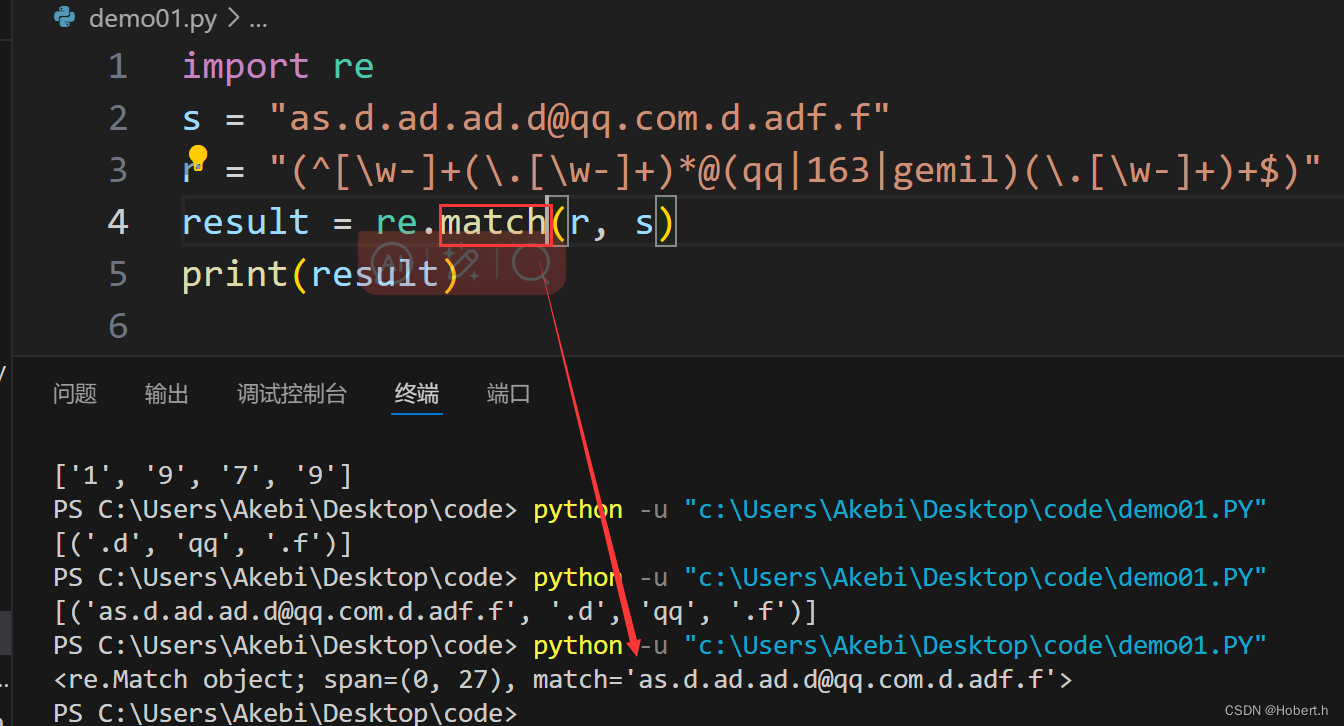
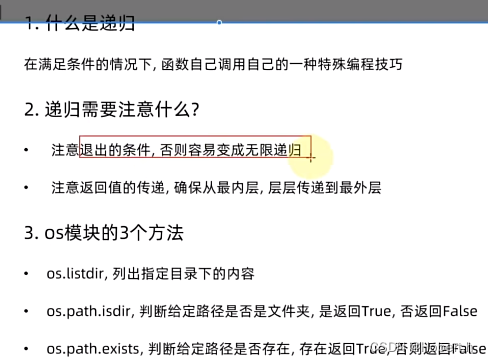
递归

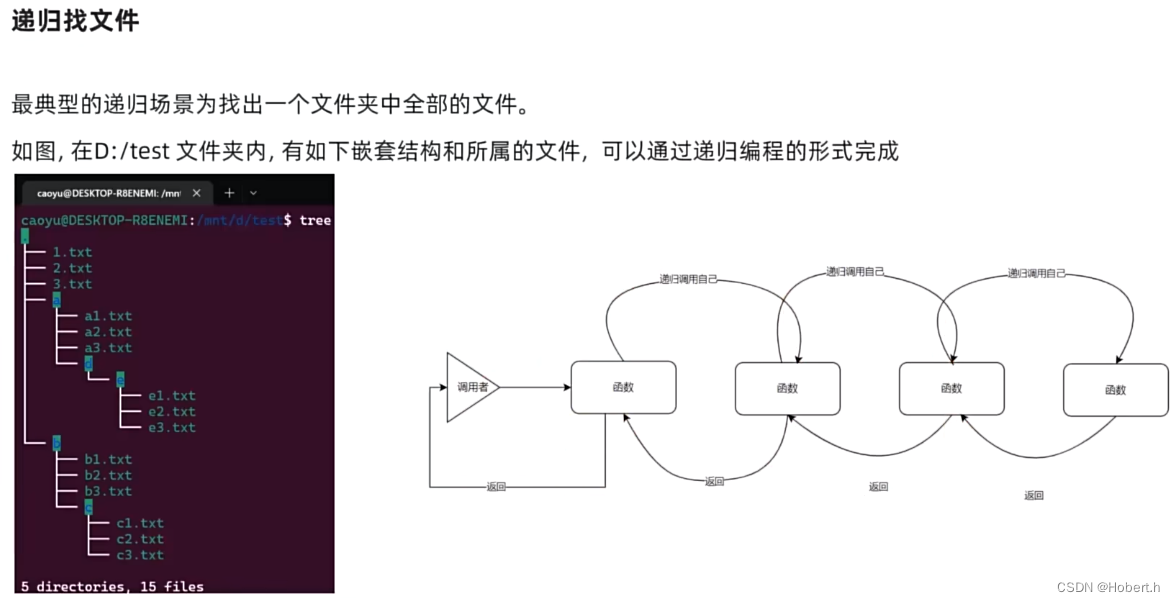
直到找到最后一层不再有文件夹后,往回返回文件

import os
def get_file_txt(path):
file_list = []
print(path)
if os.path.isdir(path): #判断是否为路径
for i in os.listdir(path):
new_path = path+"/"+i #产生新路径
if os.path.isdir(new_path): #判断是否为文件夹或是文件
file_list += get_file_txt(new_path) #实现递归累加
else:
file_list.append(new_path)
else :
return []
return file_list
if __name__ == "__main__":
print(get_file_txt("D:/abc"))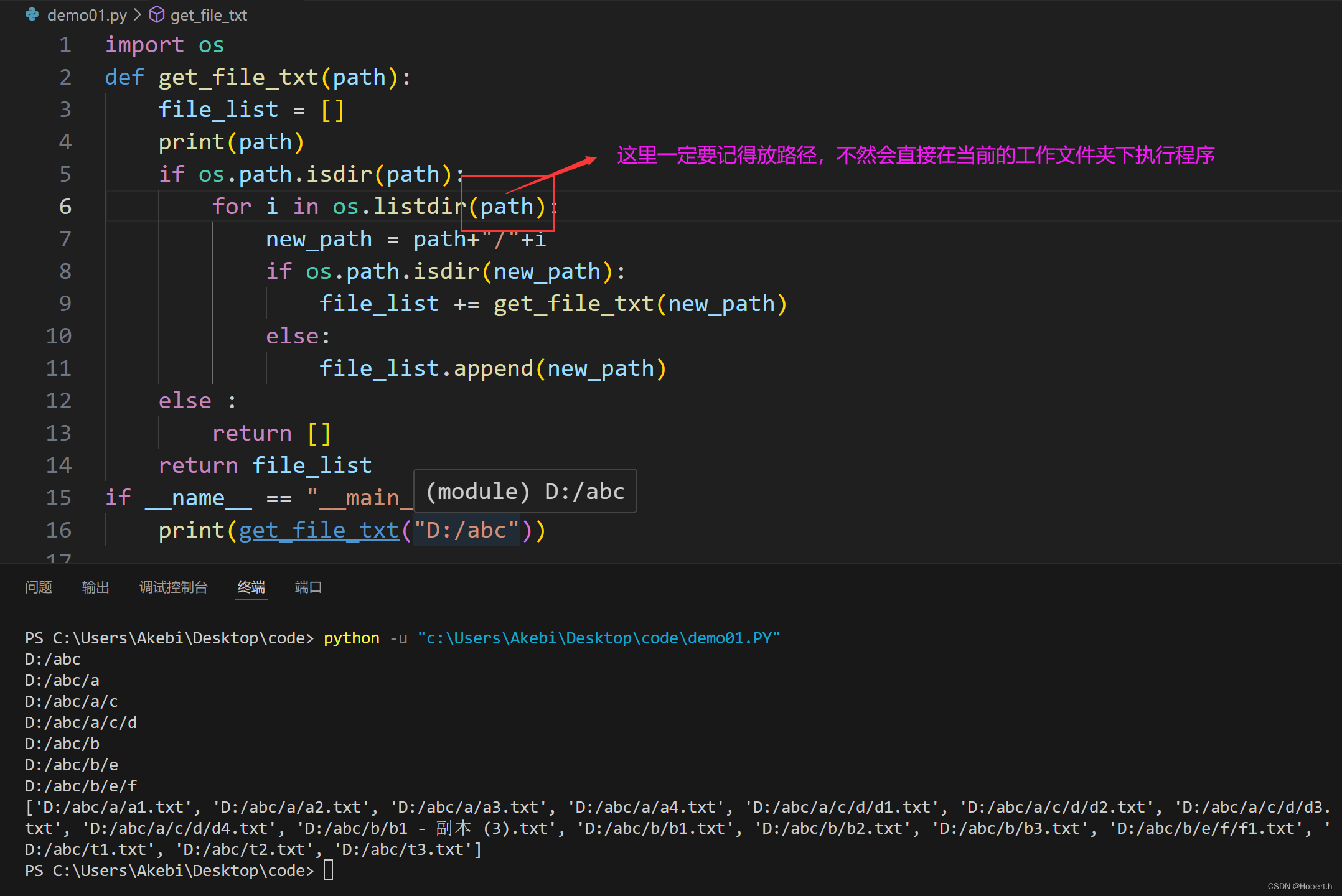
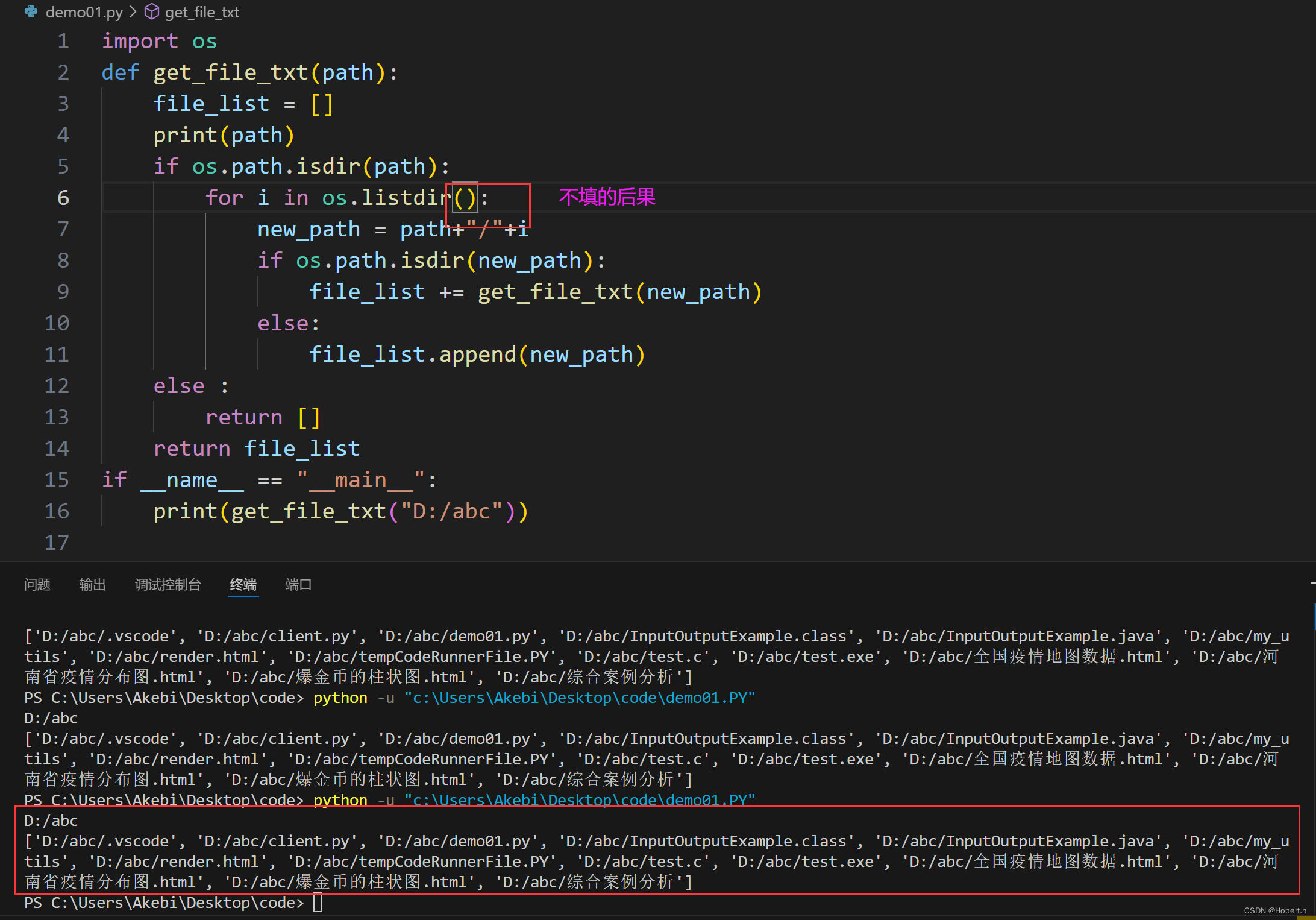
递归一定要对每次的结果进行处理,一定要有终止条件




















![[第五空间-2021]yet_another_mysql_injection](https://img-blog.csdnimg.cn/img_convert/ab8112ab99f9ce1c0fa4fad0622f169b.png)