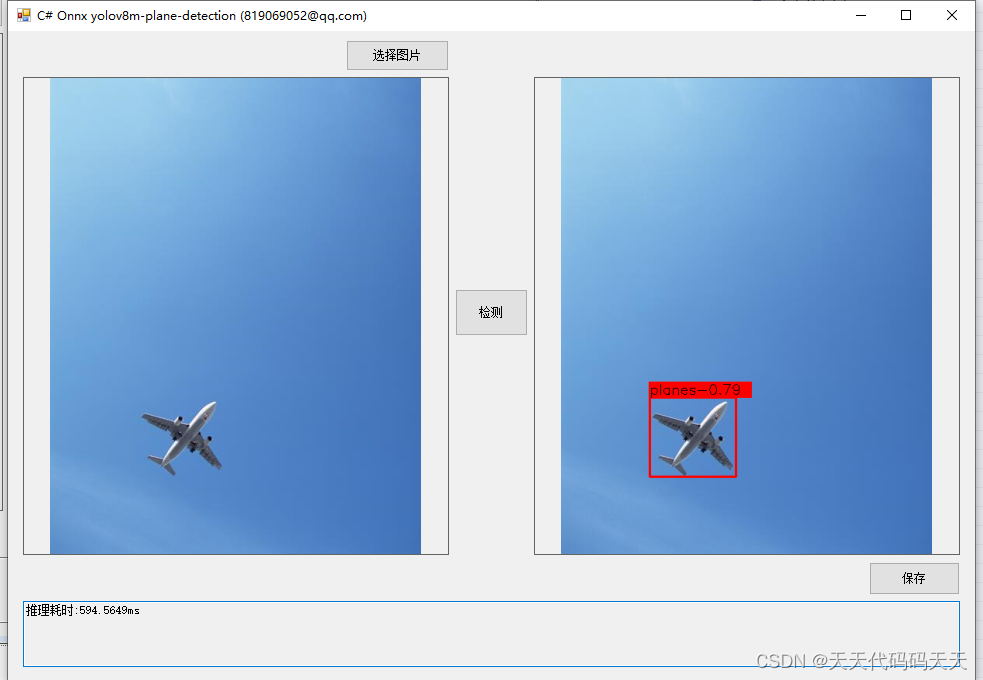
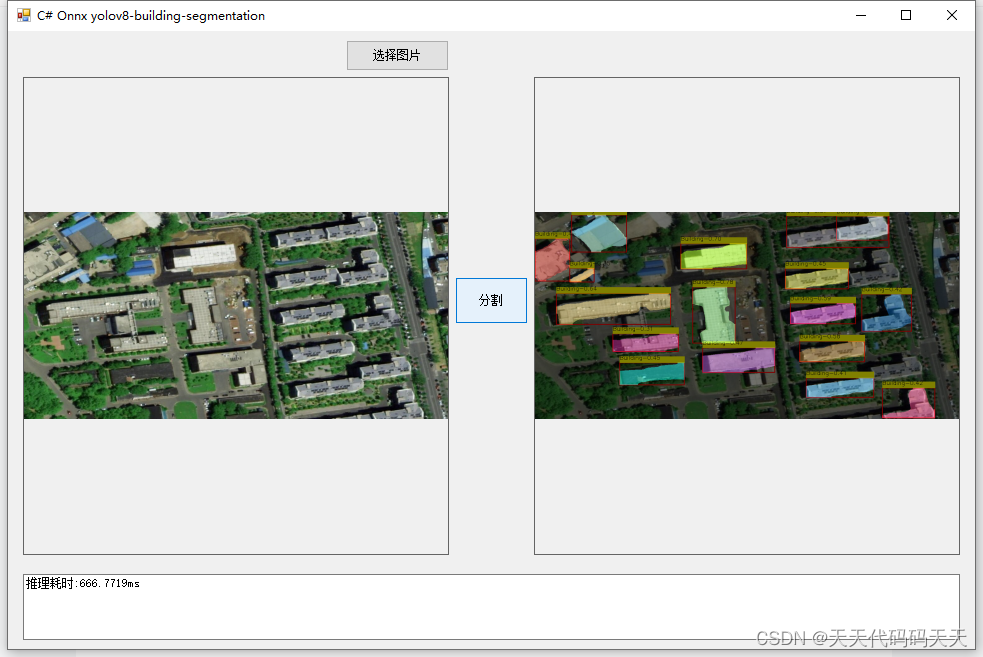
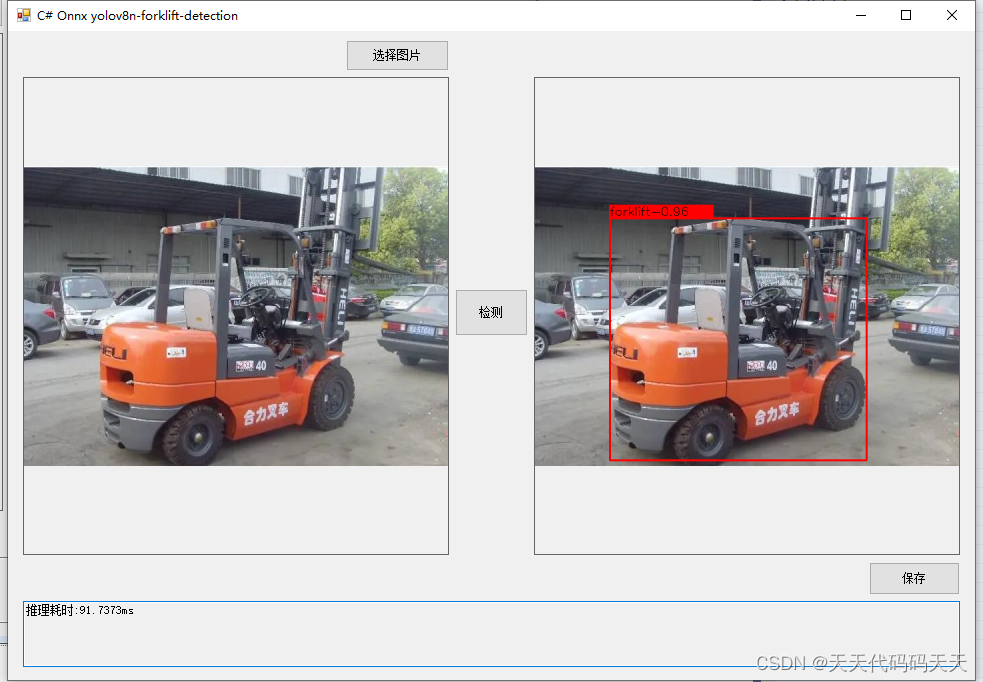
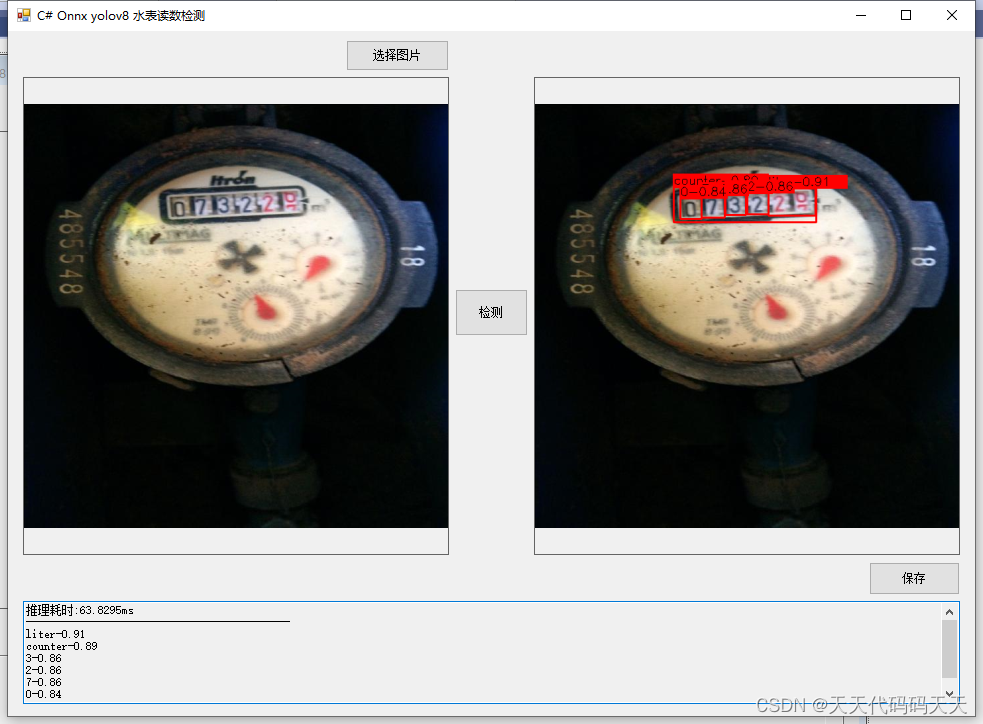
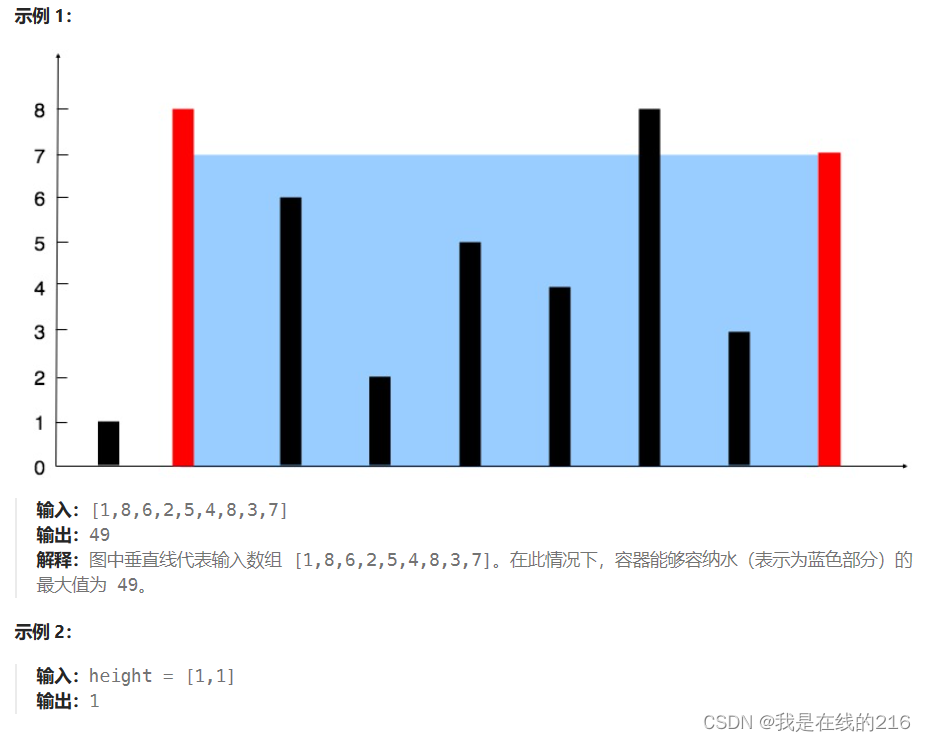
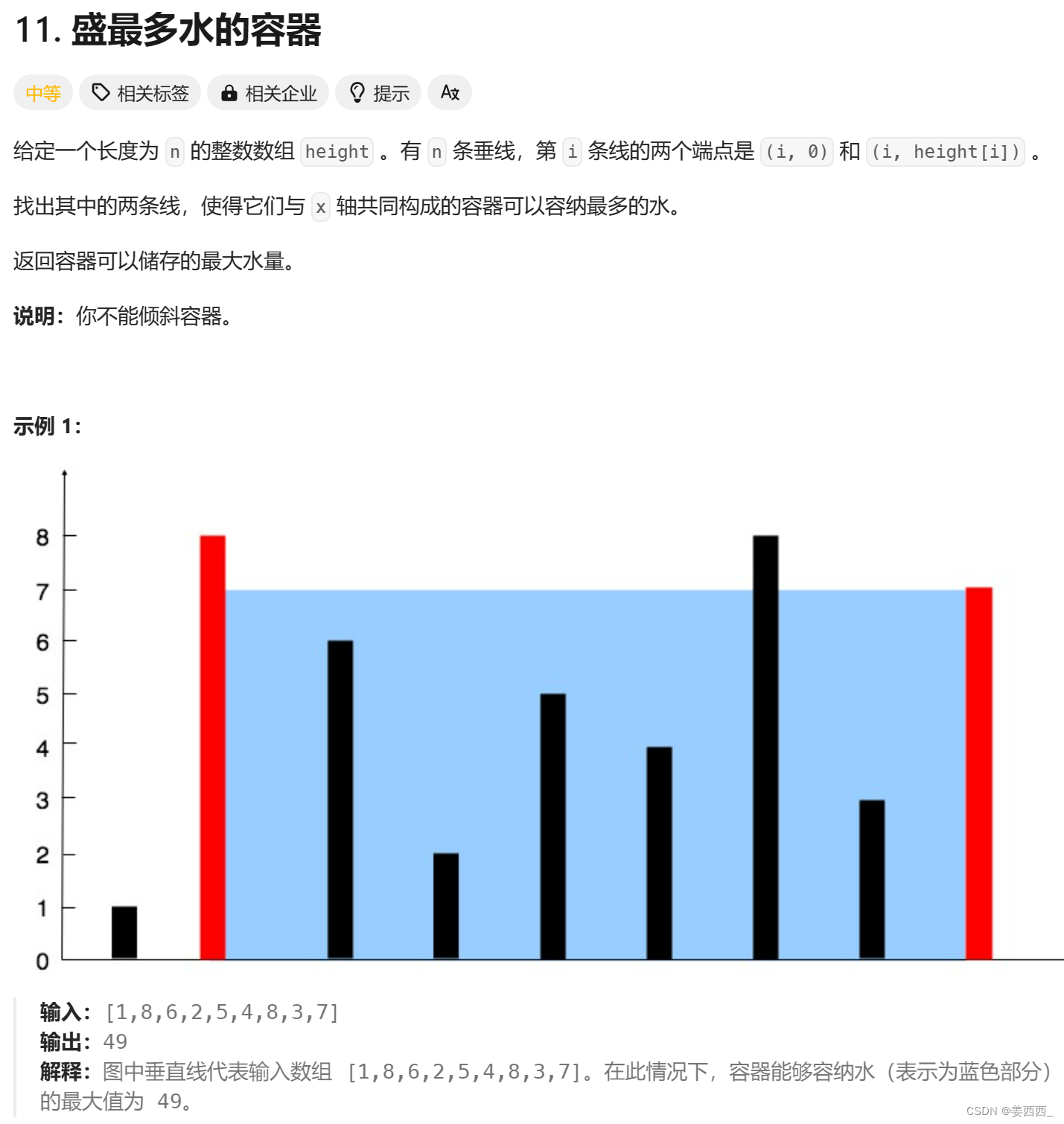
把yolov8中加载onnx和推理的代码部分全部抽出,并去掉所有使用torch的地方,onnxruntime调用cuda可能会失败,所以通过import torch,使cuda能成功调用。
import time
from PIL import Image
import torch
import cv2
import onnxruntime
import numpy as np
def LetterBox(img, new_shape=(640, 640)):
"""Resize and pad the image to new_shape maintaining aspect ratio."""
height, width = img.shape[:2]
scale = min(new_shape[1] / width, new_shape[0] / height)
new_width, new_height = int(width * scale), int(height * scale)
dw, dh = (new_shape[1] - new_width) // 2, (new_shape[0] - new_height) // 2
img_resized = cv2.resize(img, (new_width, new_height), interpolation=cv2.INTER_LINEAR)
img_padded = cv2.copyMakeBorder(img_resized, dh, new_shape[0] - new_height - dh,
dw, new_shape[1] - new_width - dw, cv2.BORDER_CONSTANT, value=(114, 114, 114))
return img_padded
def preprocess(im):
# 图像预处理
im = np.stack(im)
im = im[None]
im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)
im = np.ascontiguousarray(im).astype('float32') # contiguous
im /= 255 # 0 - 255 to 0.0 - 1.0
return im
def xywh_to_xyxy(x):
"""Convert bounding box format from (x_center, y_center, width, height) to (x_min, y_min, x_max, y_max)."""
y = np.zeros_like(x)
dw = x[..., 2] / 2 # half-width
dh = x[..., 3] / 2 # half-height
y[..., 0] = x[..., 0] - dw # top left x
y[..., 1] = x[..., 1] - dh # top left y
y[..., 2] = x[..., 0] + dw # bottom right x
y[..., 3] = x[..., 1] + dh # bottom right y
return y
def nms(boxes, scores, iou_threshold=0.5, score_threshold=0.5):
"""Apply non-maximum suppression to avoid overlapping bounding boxes."""
# Calculate the maximum score for each box across all categories
max_scores = scores.max(axis=1)
max_class_indices = scores.argmax(axis=1)
# Filter boxes and scores based on the score threshold
keep = max_scores > score_threshold
boxes = boxes[keep]
scores = max_scores[keep]
class_indices = max_class_indices[keep]
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1) * (y2 - y1)
order = scores.argsort()[::-1]
kept_indices = []
while order.size > 0:
i = order[0]
kept_indices.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0, xx2 - xx1)
h = np.maximum(0, yy2 - yy1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= iou_threshold)[0]
order = order[inds + 1]
return boxes[kept_indices], scores[kept_indices], class_indices[kept_indices]
# 将坐标还原回到原图中
def reverse_letterbox(x1, y1, original_shape, new_shape=[640, 640]):
# 计算缩放比例
r = min(new_shape[0] / original_shape[0], new_shape[1] / original_shape[1])
r = min(r, 1.0)
# 计算未填充的新尺寸
new_unpad = (int(round(original_shape[1] * r)), int(round(original_shape[0] * r)))
# 计算边框宽度
dw = (new_shape[1] - new_unpad[0]) / 2
dh = (new_shape[0] - new_unpad[1]) / 2
# 计算实际边框大小
left = int(round(dw - 0.1))
top = int(round(dh - 0.1))
# 去除边框偏移
x_original = (x1 - left) / r
y_original = (y1 - top) / r
return int(x_original), int(y_original)
def load_model(model_path, cuda=False):
providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] if cuda else ["CPUExecutionProvider"]
session = onnxruntime.InferenceSession(model_path, providers=providers)
output_names = [x.name for x in session.get_outputs()]
return session, output_names
def inference(onnx_model, img_orig: np.ndarray, iou_thres=0.5, score_thres=0.5):
im0s = LetterBox(img_orig)
im = preprocess(im0s)
res = onnx_model[0].run(onnx_model[1], {onnx_model[0].get_inputs()[0].name: im})
prediction = res[0].transpose((0, 2, 1))
boxes = xywh_to_xyxy(prediction[0, :, :4])
scores = prediction[0, :, 4:]
filtered_boxes, filtered_scores, filtered_classes = nms(boxes, scores, iou_thres, score_thres)
filtered_boxes = [[*reverse_letterbox(b[0], b[1], img_orig.shape), *reverse_letterbox(b[2], b[3], img_orig.shape)]
for b in filtered_boxes]
return filtered_boxes, filtered_scores, filtered_classes
class Dataloader:
# 自定义加载图片
def __init__(self, mod, file_path=None, video_path=None, camera=None, screenshot=None):
self.mod = mod
self.stream = file_path or video_path or screenshot
if mod == "camera" and camera is not None:
self.stream = int(camera)
def load_stream(self):
match self.mod:
case "file":
while True:
yield self.read_img(self.stream)
case "video" | "camera":
cap = cv2.VideoCapture(self.stream)
while True:
flag, frame = cap.read()
if not flag:
return StopIteration
yield frame
case "screenshot":
from PIL import ImageGrab
x1, y1 = self.stream[0] # 左上角
x2, y2 = self.stream[1] # 右下角
# 截取屏幕区域
while True:
img = ImageGrab.grab(bbox=(x1, y1, x2, y2))
im0 = np.array(img)
im0 = cv2.cvtColor(im0, cv2.COLOR_BGR2RGB)
yield im0
case _:
raise ValueError("Invalid stream type")
@staticmethod
def read_img(img_path):
# 使用Pillow打开图像, 防止出现中文路径错误
pil_image = Image.open(img_path)
# 将Pillow图像转换为NumPy数组
image_np = np.array(pil_image)
# 将NumPy数组转换为OpenCV格式的图像
opencv_image = cv2.cvtColor(image_np, cv2.COLOR_RGB2BGR)
return opencv_image
__call__ = load_stream
def plot(names=None, im: np.ndarray = None, boxes: list = None, cls: list = None) -> np.ndarray:
if names:
cls = [names[i] for i in cls]
for i, box in enumerate(boxes):
cv2.rectangle(im, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
cv2.putText(im, str(cls[i]), (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36, 255, 12), 2)
return im
if __name__ == '__main__':
onnx_model = load_model('yolov8n.onnx', cuda=False) # cuda = True调用cuda
# dataloader = Dataloader('camera', camera=0) # 加载本地相机
# dataloader = Dataloader('video', video_path='1.mp4') # 加载本地视频
# dataloader = Dataloader('file', file_path='img.png') # 加载本地图片
dataloader = Dataloader('screenshot', screenshot=[(1000, 100), (1800, 800)]) # 加载屏幕截图
for im_ in dataloader():
boxes, scores, classes = inference(onnx_model, im_)
im_ = plot(boxes=boxes, cls=classes, im=im_)
cv2.imshow('result', im_)
if cv2.waitKey(10) & 0xFF == ord('q'):
break