目录
1.Jaeger是什么
官网地址:Jaeger: open source, distributed tracing platform
Jaeger 是受到 Dapper 和 OpenZipkin 启发的由 Uber Technologies 作为开源发布的分布式跟踪系统,兼容 OpenTracing 以及 Zipkin 追踪格式,目前已成为 CNCF 基金会的开源项目。其前端采用React语言实现,后端采用GO语言实现,适用于进行链路追踪,分布式跟踪消息传递,分布式事务监控、问题分析、服务依赖性分析、性能优化等场景。
Jaeger 主要包括以下三部分:
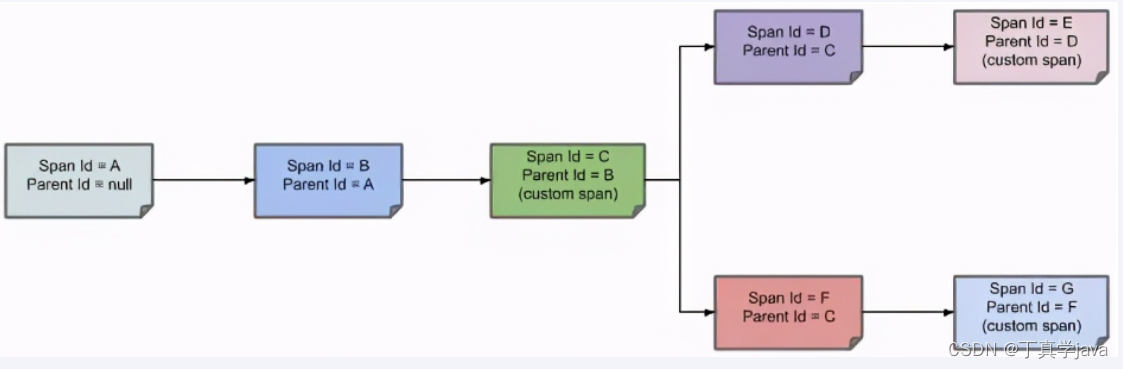
- tracer:在广义上,一个trace代表了一个事务或者流程在(分布式)系统中的执行过程。trace 是多个 span组成的一个有向无环图(DAG),每一个span代表trace中被命名并计时的连续性的执行片段。每一个 Trace 会有一个独有的 Trace ID,假设服务调用关系为 a->b->c->d,请求从 a 开始发起。 那么 a 负责生成 traceId,并在调用 b 的时候把 traceId 传递给 b,以此类推,traceId 会从 a 层层传递到 d。
- span: 是链路追踪工具的逻辑工作单元,可以是一个微服务中的 service,也可以是一次方法调用,甚至一个简单的代码块调用。具有请求名称、请求开始时间、请求持续时间。每一个 Span 会有一个独有的 Span ID。Span 会被嵌套并排序以展示服务间的关系。
- Span Context:含额外 Trace 信息的数据结构,span context 可以包含 Trace ID、Span ID,以及其他任何需要向下游服务传递的 Trace 信息。
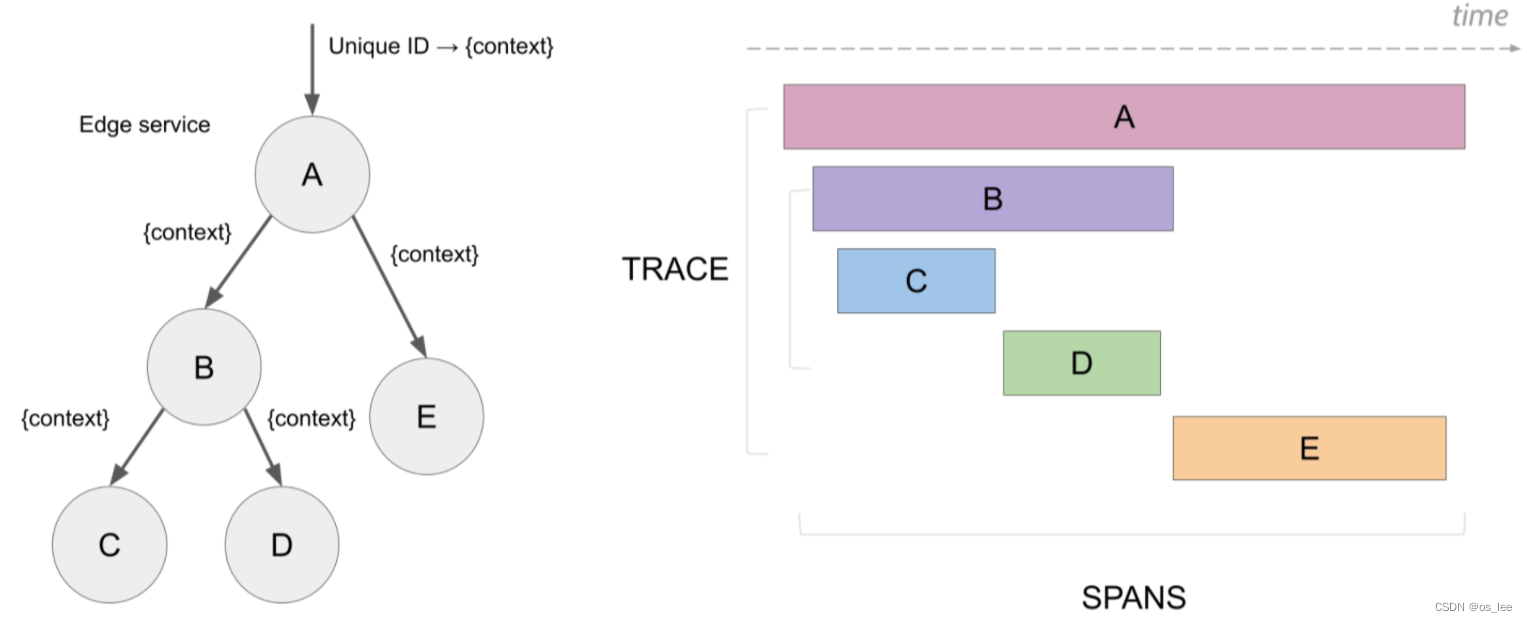
总而言之,Trace表示对一次请求完整调用链的跟踪,而将两个服务例如上面的服务A和服务B的请求/响应过程叫做一次Span,trace是通过span来体现的, 通过一句话总结,我们可以将一次trace,看成是span的有向图,而这个有向图的边即为span。而分布式跟踪系统要做的,就是记录每次发送和接受动作的标识符和时间戳,将一次请求涉及到的所有服务串联起来,只有这样才能搞清楚一次请求的完整调用链。
2.分布式链路追踪相关术语
APM
随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得更复杂:
- 不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现;
- 服务有可能布在了几千台服务器,横跨多个不同的数据中心。
因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,这就是APM系统,全称是(Application Performance Management tools,应用程序性能管理工具)。AMP最早是谷歌公开的论文提到的 Google Dapper。Dapper是Google生产环境下的分布式跟踪系统,自从Dapper发展成为一流的监控系统之后,给google的开发者和运维团队帮了大忙,所以谷歌公开论文分享了Dapper。
链路追踪
在传统的单体程序中,遇到问题时,我们可以通过函数间的调用栈来查看函数间的调用关系。但是在分布式的架构中,一个请求可能会导致多个不同网络的服务调用,这给我们调试问题带来了困难。Jaeger可以简单理解为微服务的函数调用栈,其记录了一个请求的各种调用关系,以便于我们分析问题。
OpenTracing
为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范。OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。
一句话总结,OpenTracing是一套标准,它通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。OpenTracing提供了用于运营支撑系统的和针对特定平台的辅助程序库。程序库的具体信息请参考详细的规范。OpenTracing 已进入 CNCF,正在为全球的分布式追踪,提供统一的概念和数据标准。
注意 1:OpenTracing现在已经成为过去式了,现在的APM世界,由一种叫做OpenTelemetry的规范所统治,具体详情参见《OpenTelemetry概述》。
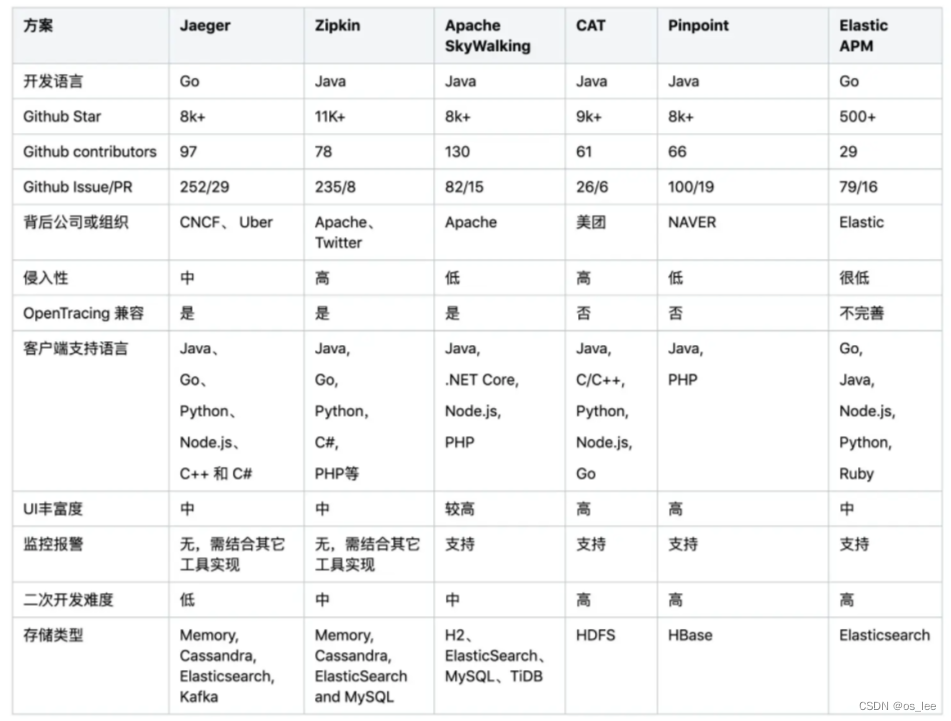
3.Jaeger和其他常用分布式链路追踪工具对比
4.Jaeger架构
Jaeger 主要由以下几个组件构成:
- Tracing SDK: 用于实现分布式链路追踪的软件开发工具包。这些 SDK 通常是针对特定编程语言或框架的,旨在帮助开发人员在应用程序中集成分布式追踪功能。这些 SDK 提供了一组 API 和工具,使开发人员能够在应用程序代码中插入相关的追踪代码,从而捕获应用程序的请求路径、性能指标和其他有关信息。通过在代码中插入追踪代码,应用程序的不同组件和服务之间的交互将被追踪,从而形成完整的请求链路。
- JaegerCollector: 接收traces,通过处理管道运行它们进行validation和清理/丰富,并将其存储在存储后端。Jaeger内置了对多个存储后端的支持,以及用于实现自定义存储插件的可扩展插件框架。
- DB: 后端存储组件,支持内存、Cassandra、Elasticsearch、Kafka 的存储方式。
- Jaeger Query: 用于接收查询请求,从数据库检索数据并通过 UI 展示。
- Jaeger UI: 使用 React 编写,用于 UI 界面展示。
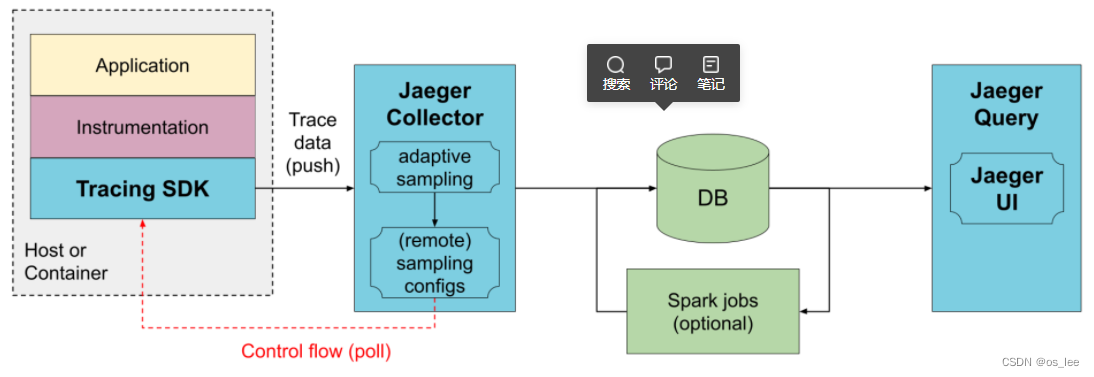
在Jaeger架构设计中,Jaeger Collector组件从被跟踪的应用程序接收数据,并将其直接写入存储。 存储必须能够同时处理平均流量和峰值流量。Jaeger Collector使用内存队列来平滑短期流量峰值,但如果存储无法跟上,持续的流量峰值可能会导致数据丢失。
5.Jaeger采样率
分布式追踪系统本身也会造成一定的性能低损耗,如果完整记录每次请求,对于生产环境可能会有极大的性能损耗,一般需要进行采样设置。
当前支持四种采样率设置:
- 固定采样(sampler.type=const)sampler.param=1 全采样, sampler.param=0 不采样;
- 按百分比采样(sampler.type=probabilistic)sampler.param=0.1 则随机采十分之一的样本;
- 采样速度限制(sampler.type=ratelimiting)sampler.param=2.0 每秒采样两个traces;
- 动态获取采样率 (sampler.type=remote) ,允许根据特定条件动态地决定是否采集某个请求的追踪数据,以减少性能开销并确保系统的稳定性。
6.Jaeger部署方式
Jaeger 的部署方式主要有以下几种:
all-in-one 部署
适用于快速体验 Jaeger ,所有追踪数据存储在内存中,不适用于生产环境。
docker run --rm --name jaeger \
-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
-p 14250:14250 \
-p 14268:14268 \
-p 14269:14269 \
-p 9411:9411 \
jaegertracing/all-in-one:1.49
分开部署
Jaeger-Collector + Jaeger-Query + Elasticsearch + kibana
Jaeger-Collector
Jaeger-Collector收集器从 SDK 或 Jaeger代理接收跟踪,通过处理管道运行它们以进行验证和清理/丰富,并将它们存储在存储后端中。
Jaeger-Query
Jaeger-Query查询是一种服务,它公开用于从存储中检索跟踪的API,并托管用于搜索和分析跟踪的 Web UI。
部署
下载jaeger对应镜像
#collector镜像
docker pull jaegertracing/jaeger-collector:1.49
#query镜像
docker pull jaegertracing/jaeger-query:1.49
下载es+kibana对应镜像
#注意:这里我使用的是7.17.10版本 最好是使用7版本的es
docker pull elasticsearch:7.17.10
docker pull kibana:7.17.10
启动对应的镜像,使用docker-compose
version: "3"
services:
busybox:
image: busybox:latest
container_name: busybox
privileged: true
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
- ./elasticsearch/logs:/usr/share/elasticsearch/logs
command: chmod -R 777 /usr/share/elasticsearch
elasticsearch:
image: elasticsearch:7.17.10
restart: always
container_name: elasticsearch
privileged: true
ports:
- 9200:9200
- 9300:9300
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms2046m -Xmx2046m
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
- ./elasticsearch/logs:/usr/share/elasticsearch/logs
depends_on:
- busybox
kibana:
image: kibana:7.17.10
restart: always
container_name: kibana
privileged: true
ports:
- 5601:5601
volumes:
- "./kibana/config:/usr/share/kibana/config"
depends_on:
- elasticsearch
jaeger-collector:
image: jaegertracing/jaeger-collector:1.49
restart: always
container_name: jaeger-collector
privileged: true
ports:
- 14268:14268
- 14269:14269
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=http://elasticsearch:9200
depends_on:
- elasticsearch
jaeger-query:
image: jaegertracing/jaeger-query:1.49
restart: always
container_name: jaeger-query
privileged: true
ports:
- 16686:16686
- 16687:16687
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=http://elasticsearch:9200
depends_on:
- elasticsearch# kibana.yml 配置文件
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
i18n.locale: "zh-CN"然后您可以导航到http://localhost:16686访问Jaeger UI。
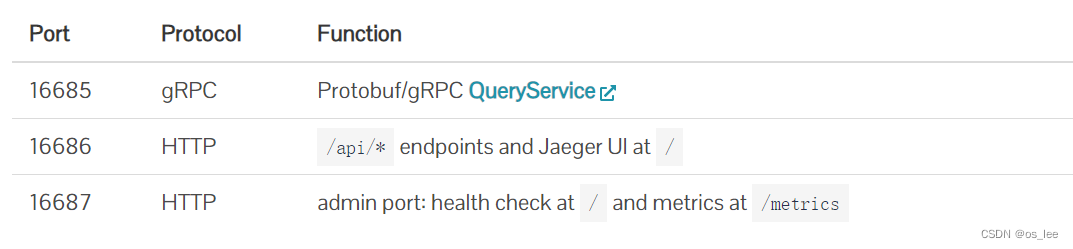
Collector暴露的端口
14268端口是用于接受外部client的数据,14269是用于监控健康指标的。

参考:Deployment — Jaeger documentation
Query暴露的端口
16686端口是用于WebUI的,16687是用于监控健康指标的。
参考:Deployment — Jaeger documentation
查看效果
打开浏览器,在地址栏上输入服务器IP:16686访问