目录
一、循环神经网络
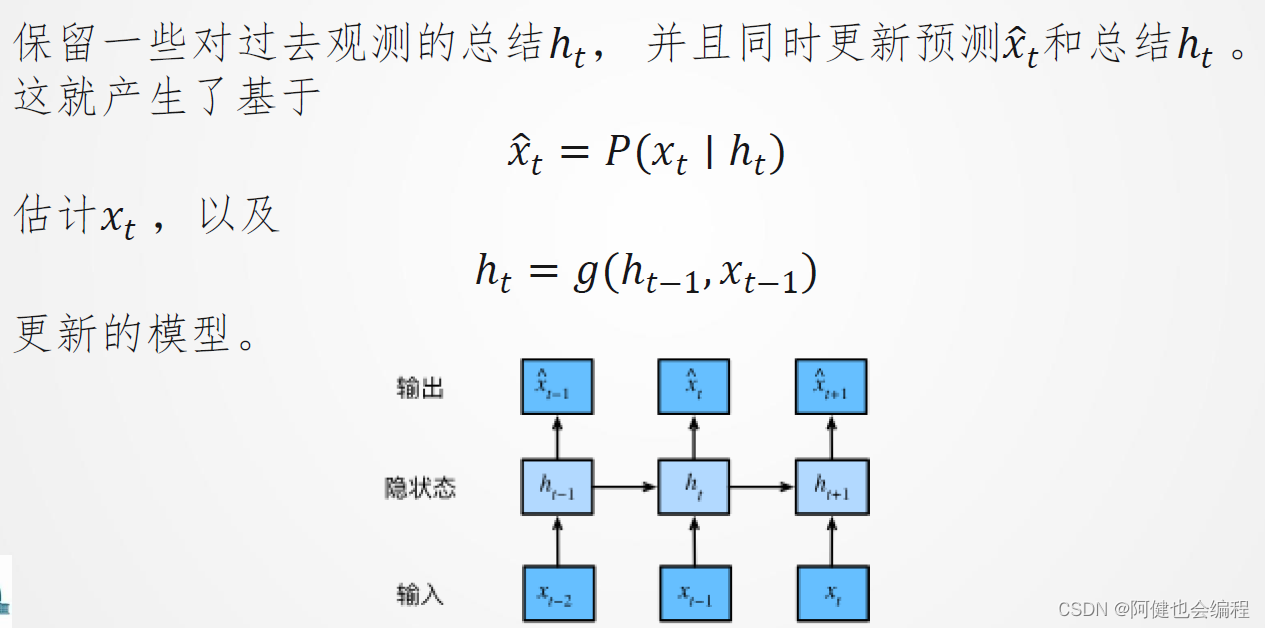
循环神经网络(RNN)是一类人工神经网络,特别适用于处理序列数据,例如时间序列数据或自然语言文本。RNN的独特之处在于其内部循环结构,允许信息持续传递到后续时间步。这使得RNN能够在处理序列数据时考虑上下文信息,并在此基础上做出预测或生成输出。RNN在自然语言处理(NLP)领域广泛应用,包括语言建模、机器翻译、文本生成等任务。它们也被用于时间序列预测、音频处理等领域。然而,传统的RNN存在梯度消失或梯度爆炸的问题,导致难以捕捉长期依赖关系。为了解决这个问题,出现了许多改进的RNN架构,如长短期记忆网络(LSTM)和门控循环单元(GRU),它们通过引入门控机制来更好地捕获长期依赖性。RNN的一个重要应用是在序列到序列(seq2seq)模型中,例如用于机器翻译的编码器-解码器结构。编码器RNN将输入序列编码成固定长度的向量表示,然后解码器RNN将这个向量解码成输出序列。
1.1 门控循环单元(GRU)
门控循环单元(Gated Recurrent Unit,GRU) 是一种改进的循环神经网络(RNN)结构,旨在解决传统RNN中的梯度消失和梯度爆炸问题,并提高模型学习长期依赖性的能力。
GRU与长短期记忆网络(LSTM)类似,都具有门控机制,但相对于LSTM,GRU的结构更加简单。GRU包括一个更新门和一个重置门,以及一个用于生成当前时间步输出的候选值。这些门控制了信息在时间步之间的流动和更新。具体来说:
更新门(Update Gate):决定了过去时间步的记忆是否要被保留,更新到当前时间步的记忆中。它的值在0到1之间,0表示完全忽略过去的记忆,1表示完全保留过去的记忆。
重置门(Reset Gate):决定了如何结合当前输入和过去记忆来计算候选值。重置门的作用是帮助模型忘记一些过去的信息,以便更好地适应当前输入。
GRU的结构相对简单,参数量较少,因此在一些场景下训练速度可能会更快。它在许多序列建模任务中表现良好,尤其是当数据量较小或计算资源有限时。
- GRU基本结构:
$𝑹𝑡 = 𝜎(𝑿𝑡𝑾𝑥𝑟 + 𝑯𝑡−1𝑾ℎ𝑟 + 𝒃𝑟)$
- 候选隐状态
$𝒁𝑡 = 𝜎(𝑿𝑡𝑾𝑥𝑧 + 𝑯𝑡−1𝑾ℎ𝑧 + 𝒃𝑧)$
- 隐状态
$𝑯𝑡 = tanh(𝑿𝑡𝑾𝑥ℎ + (𝑹𝑡 ⊙ 𝑯𝑡−1)𝑾ℎℎ + 𝒃ℎ)$
1.2 长短期记忆网络(LSTM)
长短期记忆网络(Long Short-Term Memory,LSTM) 是一种特殊的循环神经网络(RNN)结构,设计用于解决传统RNN中的梯度消失和梯度爆炸问题,并且能够更好地捕获长期依赖性。
LSTM通过引入门控机制,包括遗忘门、输入门和输出门,来控制信息的流动和更新。这些门控制了哪些信息可以通过网络保留、删除或读取。具体来说:
- 遗忘门(Forget Gate):决定了过去记忆中哪些信息需要被遗忘。它的值在0到1之间,0表示完全忘记过去的记忆,1表示完全保留过去的记忆。
- 输入门(Input Gate):决定了当前输入中哪些信息需要被添加到记忆中。它的值在0到1之间,0表示完全忽略当前输入,1表示完全添加当前输入。
- 输出门(Output Gate):决定了从记忆中读取出来的信息如何被输出到当前时间步。它的值在0到1之间,0表示完全不输出记忆中的信息,1表示完全输出记忆中的信息。
这些门控制了LSTM的记忆单元中的信息流动,使得LSTM能够在长序列上有效地捕获长期依赖性,同时缓解了梯度消失和梯度爆炸问题。
LSTM在各种序列建模任务中表现出色,包括自然语言处理、语音识别、时间序列预测等领域。它的结构相对复杂,参数量较大,但能够处理更加复杂和长期依赖性强的序列数据。
1.3 深度循环神经网络
深度循环神经网络(Deep Recurrent Neural Networks,Deep RNNs) 是指在循环神经网络(RNN)结构中引入多个循环层的网络模型。与传统的RNN相比,深度循环神经网络具有更深的网络结构,能够更好地捕获数据中的抽象特征和高级表示。
在深度循环神经网络中,每个时间步的输入都会经过多个循环层进行处理,每个循环层都可以视为一个抽象层次,负责学习不同级别的表示。这样的结构使得网络能够学习到更复杂的时间依赖关系和序列特征,从而提高模型的性能和泛化能力。
深度循环神经网络可以使用各种类型的循环层,包括:
- 传统的RNN
- 长短期记忆网络(LSTM)
- 门控循环单元(GRU)
深度循环神经网络在许多序列建模任务中表现出色,例如语言建模、机器翻译、文本生成、语音识别等。它们能够处理复杂的时间序列数据,并且在一些情况下比单层RNN具有更好的性能。
1.4 双向循环神经网络
双向循环神经网络(Bidirectional Recurrent Neural Networks,Bi-RNNs) 是一种循环神经网络(RNN)结构,能够同时考虑序列数据的过去和未来信息。它通过在每个时间步上同时运行两个独立的RNN,一个按照正序处理序列,另一个按照逆序处理序列,然后将它们的输出进行拼接或合并,以获得更全面的序列信息。
双向循环神经网络包括两个方向的循环层 :正向循环层和逆向循环层。
- 在正向循环层中,序列数据按照时间顺序依次输入;
- 而在逆向循环层中,序列数据按照时间的逆序输入。
- 每个方向的循环层都可以是传统的RNN、LSTM或GRU等结构。
双向循环神经网络的优势:
在于它能够同时利用序列中的历史和未来信息,从而更全面地捕获序列中的特征和依赖关系。
例如,在自然语言处理任务中,双向循环神经网络可以更好地理解一个单词在句子中的含义,因为它可以同时考虑该单词之前和之后的上下文信息。
双向循环神经网络广泛应用:
- 各种序列建模任务中
- 语言建模
- 命名实体识别
- 情感分析
- 机器翻译
- 它们能够提高模型的性能和泛化能力,尤其在处理需要考虑上下文信息的任务中表现出色。
二、NLP
NLP(自然语言处理) 是一门人工智能领域,旨在使计算机能够理解、解释、操纵和生成人类语言。
- NLP利用机器学习和深度学习等技术,如循环神经网络(RNN)、卷积神经网络(CNN)、注意力机制(Attention)、预训练模型(如BERT、GPT等)等来解决这些问题。随着深度学习技术的不断发展和自然语言处理任务的不断拓展,NLP在各个领域都得到了广泛应用,包括搜索引擎、社交媒体分析、智能客服、智能翻译等。
应用场景:- 文本分类:将文本分成不同的类别,如情感分析、主题分类等。
- 命名实体识别:识别文本中提及的实体,如人名、地名、组织机构等。
- 信息抽取:从非结构化文本中提取结构化信息,如从新闻文章中提取事件、日期、地点等。
- 语言生成:生成自然语言文本,如机器翻译、摘要生成、对话系统等。
- 语言理解:理解自然语言文本的含义,包括语义分析、句法分析、语义角色标注等。
- 问答系统:基于自然语言文本回答用户提出的问题,如基于知识库的问答、基于文本的问答等。
- 文本生成:生成自然语言文本,如文章写作、诗歌生成、对话系统等。
2.1 序列模型
- 序列模型是一类机器学习模型,专门用于处理序列数据,即按照顺序排列的数据集合。这些模型可以从序列中学习到数据之间的关系和模式,并用于预测、分类、生成等任务。
图像分类:
- 当前输入−>当前输出
时间序列预测: - 当前+过去输入−>当前输出
自回归模型: - 自回归模型是一种时间序列模型,用于预测时间序列数据中下一个时间步的值。在自回归模型中,当前时间步的观测值被假定为过去时间步的观测值的线性组合,加上一个误差项。
- 具体来说,自回归模型可以表示为:
y t = c + ∑ i = 1 p ϕ i y t − i + ϵ t y_t = c + \sum_{i=1}^{p} \phi_i y_{t-i} + \epsilon_t yt=c+∑i=1pϕiyt−i+ϵt
其中:- ( y t y_t yt ) 是时间步 ( t ) 的观测值。
- ( c ) 是常数项。
- ( p h i 1 , ϕ 2 , . . . , ϕ p phi_1, \phi_2, ..., \phi_p phi1,ϕ2,...,ϕp) 是自回归系数,表示过去 ( p ) 个时间步的影响权重。
- ( e t e_t et ) 是时间步 ( t ) 的误差项,通常假定为独立同分布的随机变量。
- 自回归模型中的 ( p p p ) 称为自回归阶数,决定了模型考虑过去多少个时间步的观测值。
自回归模型常用于时间序列分析和预测任务中。
- 在建模时,通常使用已知的历史数据来拟合模型参数,并使用拟合好的模型进行未来时间步的预测。
2.2 数据预处理
特征编码
- 特征编码是将原始数据转换成机器学习算法可以处理的特征表示形式的过程。在特征编码中,原始数据的各种属性或特征被映射到数值化的形式,以便机器学习算法能够对其进行有效的处理和分析。
- 常见的特征编码方法:
- 独热编码(One-Hot Encoding):将分类变量转换为二进制向量的形式,其中每个可能的类别对应一个二进制位,只有属于某个类别的位被设置为1,其余位被设置为0。
- 标签编码(Label Encoding):将分类变量转换为从0到N-1的整数形式,其中N是类别的数量。这种编码适用于某些机器学习算法,如决策树和随机森林。
- 数值化(Numerical Encoding):对于具有顺序关系的分类变量,可以使用数值化方法将其映射为有序的数字。
- Embedding编码:对于自然语言文本或其他高维度的数据,可以使用Embedding技术将其映射到低维度的连续向量空间中,以便更好地表示语义和相关性。
- 特征缩放(Feature Scaling):将数值型特征进行归一化或标准化,以确保各个特征在相似的尺度范围内,避免某些特征对模型的影响过大。
- 特征衍生(Feature Engineering):根据原始特征衍生出新的特征,以提高模型的性能和泛化能力,如多项式特征、交互特征等。
文本处理
- 文本处理是对文本数据进行预处理、分析、理解和转换的过程。它是自然语言处理(NLP)的一个重要组成部分,涉及到从原始文本中提取信息、进行文本挖掘、文本分类、文本生成等各种任务。
- 主要步骤:
- 文本清洗(Text Cleaning):去除文本中的噪声和不必要的信息,如HTML标记、特殊字符、标点符号等。
- 分词(Tokenization):将文本分割成单词或子词的序列,以便后续处理。
- 停用词去除(Stopwords Removal):去除常见的停用词,如“and”、“the”、“is”等,这些词对文本分析和模型训练往往没有帮助。
- 词干提取(Stemming)和词形还原(Lemmatization):将单词转换为它们的基本形式,以减少词汇的变化形式对模型的影响。
- 词向量化(Word Vectorization):将文本转换为数值化的形式,以便输入到机器学习算法中。常见的方法包括独热编码、词袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)和词嵌入(Word Embedding)。
- 特征选择(Feature Selection):选择最具代表性的特征,以减少数据维度和提高模型性能。
- 文本分析和挖掘:对文本数据进行分析、探索和发现隐藏在其中的模式和规律,如主题建模、情感分析、实体识别等。
- 模型训练和评估:利用机器学习和深度学习模型对文本数据进行训练,并评估模型的性能和泛化能力。
2.3 文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将 解析文本的常见预处理步骤。
这些步骤通常包括:
1.将文本作为字符串加载到内存中。
2.将字符串切分为词元(如单词和字符)。
3.建立一个字典,将拆分的词元映射到数字索引。
4.将文本转换为数字索引序列,方便模型操作。
第一步读取数据集
- 文本预处理的第一步是读取数据集。以下是一个使用Pandas库读取文本数据集的示例代码:
import pandas as pd
# 读取文本文件,假设数据集以CSV格式存储
data = pd.read_csv("your_dataset.csv")
# 显示数据集的前几行
print(data.head())
- 如果数据集不是以CSV格式存储,而是以其他格式存储,如JSON、TSV等,你可以使用Pandas提供的相应读取函数,例如
pd.read_json()、pd.read_table()等。
第二步词汇切分
词汇切分,也称为分词(Tokenization)。在这一步,文本被切分成单词或者子词的序列,以便进一步处理。
以下是使用NLTK和spaCy进行分词的示例代码:
import nltk
from nltk.tokenize import word_tokenize
# 下载NLTK分词器所需的数据
nltk.download('punkt')
# 使用NLTK的分词器进行分词
text = "This is a sample sentence for tokenization."
tokens = word_tokenize(text)
# 显示分词结果
print(tokens)
import spacy
# 加载spaCy的英文分词器
nlp = spacy.load("en_core_web_sm")
# 使用spaCy进行分词
text = "This is a sample sentence for tokenization."
doc = nlp(text)
# 获取分词结果
tokens = [token.text for token in doc]
# 显示分词结果
print(tokens)
第三步构建词索引表
构建词索引表是自然语言处理(NLP)中的一个重要步骤,它通常用于将文本数据转换为计算机可以理解和处理的数字形式。如何构建词索引表:
1. 收集词汇
- 首先,你需要收集所有出现在你的文本数据集中的词汇。这通常意味着你需要遍历你的整个数据集,提取出所有的单词或标记。
2. 去除停用词
- 停用词是那些在文本中频繁出现但对文本意义贡献不大的词,如“的”、“是”、“了”等。为了提高效率和减少存储需求,通常会在构建词索引表之前去除这些停用词。
3. 词汇唯一化
- 确保词汇表中的每个词都是唯一的。这意味着你需要删除重复的词汇。
4. 排序
- 对词汇表中的词汇进行排序,这有助于后续的查找和索引操作。
5. 分配索引
- 给词汇表中的每个词分配一个唯一的索引。这通常是一个整数,从0或1开始递增。索引值用于在后续的文本处理中代替实际的词汇。
6. 创建映射关系
- 创建一个映射关系,将每个词与其对应的索引关联起来。这可以是一个字典、哈希表或其他数据结构,它允许你通过词快速查找其索引,反之亦然。
7. 保存词索引表
- 将构建好的词索引表保存下来,以便在后续的文本处理任务中使用。