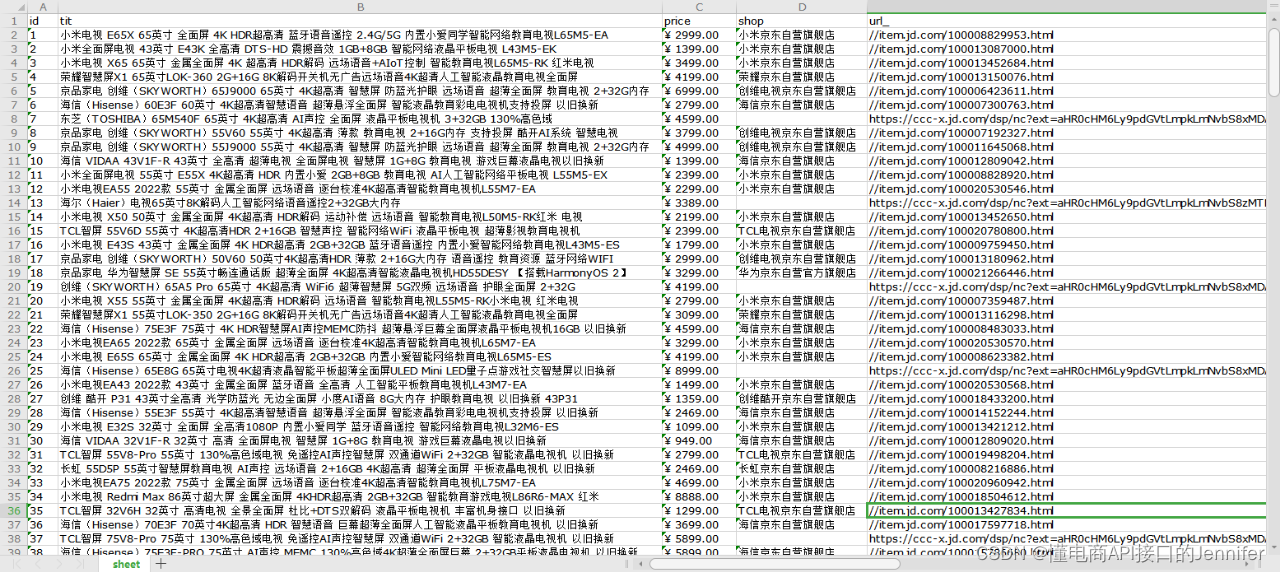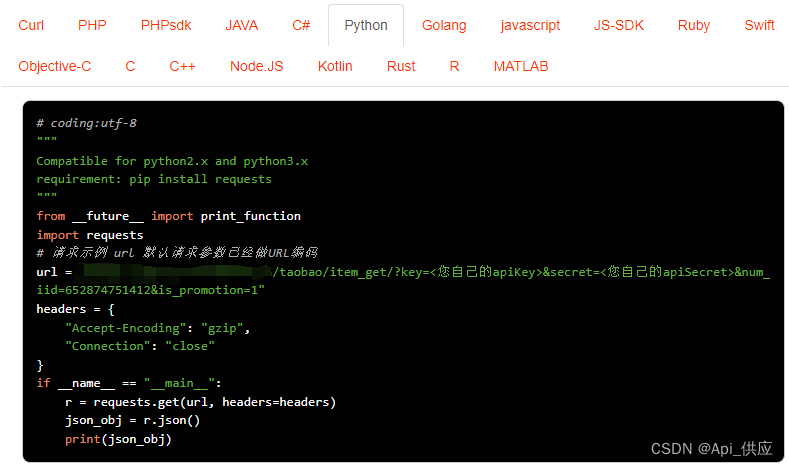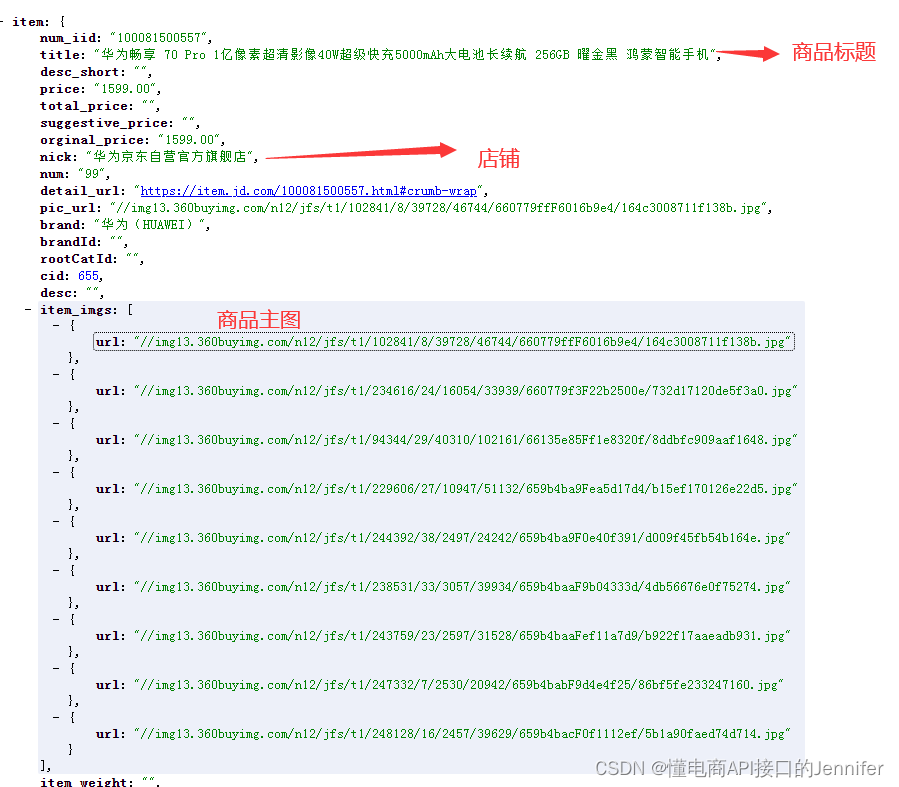
这段Python代码主要用于从京东网站的搜索结果页面抓取关于手机商品的信息,包括商品标题,价格,评论数以及商品图片的链接。
代码都测试验证过都能正常跑通,实现效果,由于各大网站防爬机制随时可能更新,代码可能失效。思路可以参考
它首先向给定的URL发出请求,然后使用BeautifulSoup库来解析返回的HTML文档。在解析过程中,它查找包含商品信息的HTML元素,并从这些元素中提取出我们需要的信息。提取出的信息会被保存为一个Python列表,每一项都代表一个商品,每一项都是一个包含商品标题,价格,评论数以及商品图片链接的列表。商品采集封装API测试
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
然后,这个程序使用Pandas库将提取出的数据转换为一个DataFrame对象,这样就可以方便地处理数据,比如进行排序,过滤,统计等操作。最后,它将DataFrame对象保存为一个Excel文件,可以直接在Excel中打开查看。
在实现过程中,这段代码使用了requests库来发出HTTP请求,BeautifulSoup库来解析HTML文档,Pandas库来处理和保存数据。
你需要安装如下几个Python库:
requests:发送HTTP请求
BeautifulSoup:解析HTML代码
pandas:处理数据和保存数据到Excel
openpyxl:pandas的依赖库,用于写入Excel文件
如果这些库尚未安装,可以使用pip进行安装:
pip install requests beautifulsoup4 pandas openpyxlimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# Xpanx.com 专业网络爬虫程序定制,加微信 LiteMango(付费)def get_data(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36","Referer": "https://search.jd.com"}r = requests.get(url, headers=headers)r.encoding = 'utf-8'soup = BeautifulSoup(r.text, "html.parser")return soupdef parse_data(soup):data = []items = soup.find_all('li', {'class': 'gl-item'})for item in items:try:title = item.find('div', {'class': 'p-name p-name-type-2'}).a.em.textprice = item.find('div', {'class': 'p-price'}).strong.i.textcomment = item.find('div', {'class': 'p-commit'}).strong.a.textimg_url = item.find('div', {'class': 'p-img'}).a.img['data-lazy-img']data.append([title, price, comment, img_url])except AttributeError:continuereturn datadef data_to_excel(data):df = pd.DataFrame(data, columns=['Title', 'Price', 'Comment', 'Image URL'])df.to_excel('jd_products.xlsx', index=False)if __name__ == "__main__":url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=541bde5713154895ad650c43c4167c10"soup = get_data(url)data = parse_data(soup)data_to_excel(data)