pandas更新中…
pandas版本:2.0.3
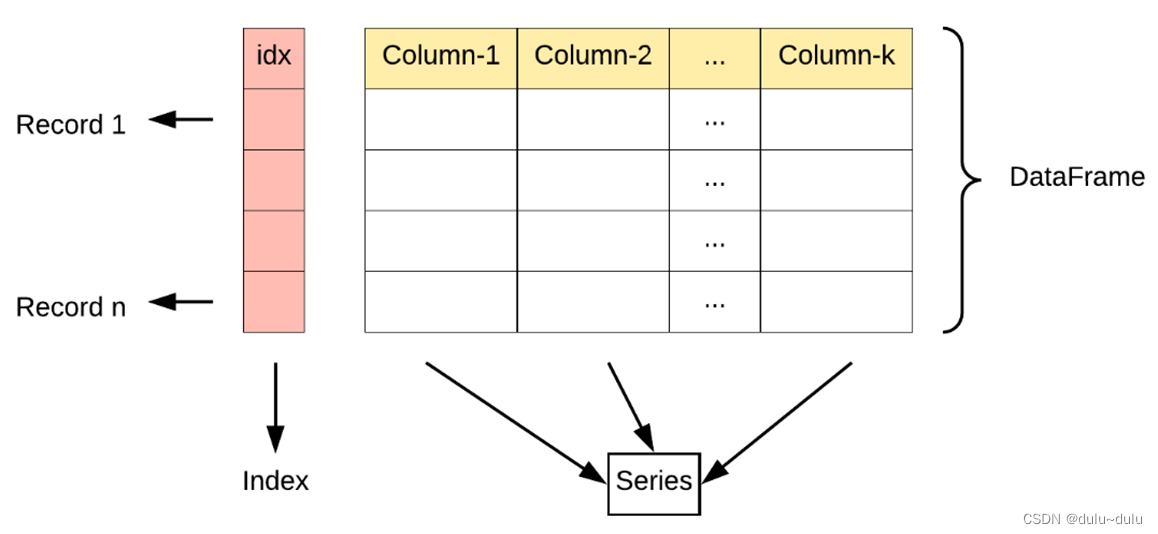
pandas两个比较重要的结构:Series和DataFrame
导包
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
Series的创建
# 创建Series的四种方式
s1 = pd.Series([1, 2, 3, 4, 5])
print(s1.iloc[1:3]) # index的切片访问
# 1 2
# 2 3
# dtype: int64
s2 = pd.Series(np.arange(10))
print(s2.loc[1:3]) # label的切片访问
# 1 1
# 2 2
# 3 3
# dtype: int64
s3 = pd.Series([1, 2, 3], index=["a", "b", "c"])
print(s3.loc[["a", "c"]])
# a 1
# c 3
# dtype: int64
print(s3.to_dict()) # 转换为字典
# {'a': 1, 'b': 2, 'c': 3}
s4_dict = {"a": 1, "b": 2, "c": 3}
s4 = pd.Series(s4_dict)
print(s4.at["a"])
# 1
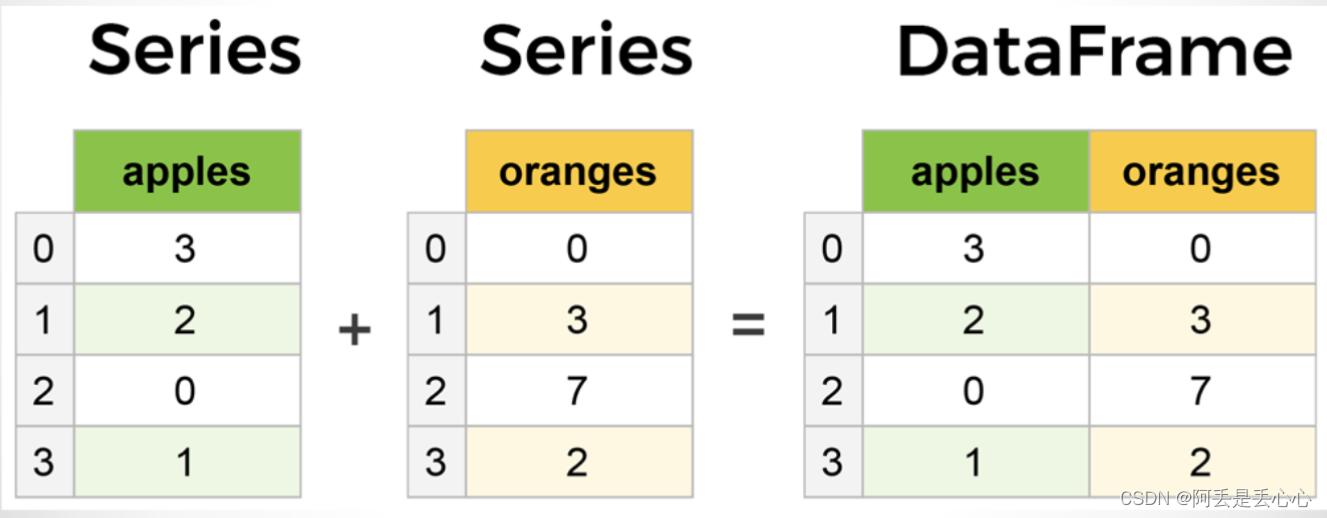
DataFrame的创建
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
columns = ["A", "B", "C"]
df = pd.DataFrame(data, columns=columns)
print(df.index)
# RangeIndex(start=0, stop=3, step=1)
print(df.columns)
# Index(['A', 'B', 'C'], dtype='object')
print(df.values)
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
s1 = pd.Series([1, 2, 3], name="A")
s2 = pd.Series([4, 5, 6], name="B")
s3 = pd.Series([7, 8, 9], name="C")
s4 = pd.Series([8, 8, 8], name="DF")
df2 = pd.DataFrame([s1, s2, s3, s4])
print(df2)
print(df2.index)
# 0 1 2
# A 1 2 3
# B 4 5 6
# C 7 8 9
# DF 8 8 8
# Index(['A', 'B', 'C', 'DF'], dtype='object')
data = {
"Programming Language": ["Java", "C", "C++", "C#", "Python", "PHP"],
"Sep 2016": [1, 2, 3, 4, 5, 6],
}
df = pd.DataFrame(data)
print(df)
# Programming Language Sep 2016
# 0 Java 1
# 1 C 2
# 2 C++ 3
# 3 C# 4
# 4 Python 5
# 5 PHP 6
print(df.dtypes)
# Programming Language object
# Sep 2016 int64
# dtype: object
DataFrame的遍历(重要)
data = {
"Country": ["Belggium", "India", "Brazil"],
"Capital": ["Brussels", "New Delhi", "Brasilia"],
"Population": [11190846, 1303171035, 20183971],
}
df1 = pd.DataFrame(data)
print(df1)
# Country Capital Population
# 0 Belggium Brussels 11190846
# 1 India New Delhi 1303171035
# 2 Brazil Brasilia 20183971
print(df1.iterrows()) # 将DataFrame数据转化为可迭代对象
# <generator object DataFrame.iterrows at 0x7f03fcec6cf0>
for row in df1.iterrows():
# print(row) # row的type为tuple
print(row[0]) # row[0]为index
# 0
print(row[1]) # row[1]为Series
# Country Belggium
# Capital Brussels
# Population 11190846
# Name: 0, dtype: object
print(row[1]["Country"]) # 获取Series中具体的值
# Belggium
break # 为了说明只打印一次
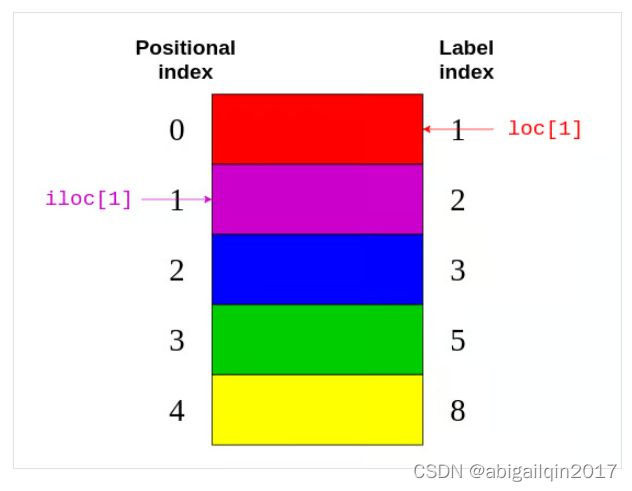
两个很重要的函数iloc和loc
iloc 和 loc 是 Pandas 库中两种用于在 DataFrame 或 Series 上进行数据选取的主要方法。
iloc
全称:index location
索引依据:基于位置的整数索引。
用法:
接受整数(包括整数列表、数组、切片等)作为参数。
可以作用于Series和DataFrame对象。
采用 Python 切片语法时,遵循 Python 的惯例,即左闭右开(iloc[start:stop:step])。loc
全称:label of columns
索引依据:基于标签(通常是字符串或其他非数值类型)的索引。
用法:
接受索引标签、布尔型数组等作为参数。
可以作用于Series和DataFrame对象。
支持混合索引,即同时使用标签选取行和列(loc[row_label, column_label])。区别
索引方式不同:iloc 使用整数位置索引,而 loc 使用标签索引。
索引错误处理:如果使用 iloc 选取不存在的位置,Pandas 不会抛出错误;而如果使用 loc 选取不存在的标签,则会引发 KeyError。
切片行为:iloc 的切片遵循 Python 数组切片规则(左闭右开),而 loc 的切片是包含两端的(左闭右闭)。
iloc操作
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
columns = ["A", "B", "C"]
df = pd.DataFrame(data, columns=columns)
print(df)
# A B C
# 0 1 2 3
# 1 4 5 6
# 2 7 8 9
# 选取第二行,index索引为1,返回 Series
print(df.iloc[1])
# A 4
# B 5
# C 6
# Name: 1, dtype: int64
# 选取第二、三行,返回 DataFrame
print(df.iloc[[1, 2]])
# A B C
# 1 4 5 6
# 2 7 8 9
# 选取第二列,index索引为1,返回 Series
print(df.iloc[:, 1])
# 0 2
# 1 5
# 2 8
# Name: B, dtype: int64
# 切片操作,左闭右开
# 选取第二行至第三行,以及第二列至第三列,返回 DataFrame
print(df.iloc[1:3, 1:3])
# B C
# 1 5 6
# 2 8 9
# 切片操作,左闭右开
# 选取第二行至第三行,所有列,返回 DataFrame
print(df.iloc[1:3, :])
# A B C
# 1 4 5 6
# 2 7 8 9
# 选取不连续的行,第一、三行,所有列,返回 DataFrame
print(df.iloc[[0, 2], :])
# A B C
# 0 1 2 3
# 2 7 8 9
loc操作
s1 = pd.Series([1, 2, 3], name="A")
s2 = pd.Series([4, 5, 6], name="B")
s3 = pd.Series([7, 8, 9], name="C")
s4 = pd.Series([8, 8, 8], name="DF")
df2 = pd.DataFrame([s1, s2, s3, s4])
print(df2)
# 0 1 2
# A 1 2 3
# B 4 5 6
# C 7 8 9
# DF 8 8 8
print(df2.index) # !!记住这里的index!
# Index(['A', 'B', 'C', 'DF'], dtype='object')
# 报错KeyError: 1, 索引1不存在
# print(df2.loc[1])
# 不报错,index location的方式可以访问,返回 Series
# 但是df2中的index是字符串,用iloc方式访问很容易混淆
# iloc始终基于数据行在内存中的位置进行访问
print(df2.iloc[1])
# 0 4
# 1 5
# 2 6
# Name: B, dtype: int64
# 取索引为'B'的行,返回 Series
print(df2.loc["B"])
# 0 4
# 1 5
# 2 6
# Name: B, dtype: int64
# 选取索引为'B'和'C'的行,返回 DataFrame
print(df2.loc[["B", "C"]])
# 0 1 2
# B 4 5 6
# C 7 8 9
# 选取列名为1的列,返回 Series
print(df2.loc[:, 1])
# A 2
# B 5
# C 8
# Name: 1, dtype: int64
# 切片操作,左闭右闭
# 取连续索引'B'到'DF'的行,列名1到2的列,返回 DataFrame
print(df2.loc["B":"DF", 1:2])
# 1 2
# B 5 6
# C 8 9
# DF 8 8
# 切片操作,左闭右闭
# 取不连续索引'A'、'DF'的行,列名1到2的列,返回 DataFrame
print(df2.loc[["A", "DF"], 1:2])
# 1 2
# A 2 3
# DF 8 8