pandas是基于numpy数组构建的,但二者最大的不同是pandas是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而numpy更适合处理统一的数值数组数据。pandas数组结构有一维Series和二维DataFrame。
Series的字符串表现形式为:索引在左边,值在右边。如果不为数据指定索引,则会默认创建一个0到n-1的整数型索引。
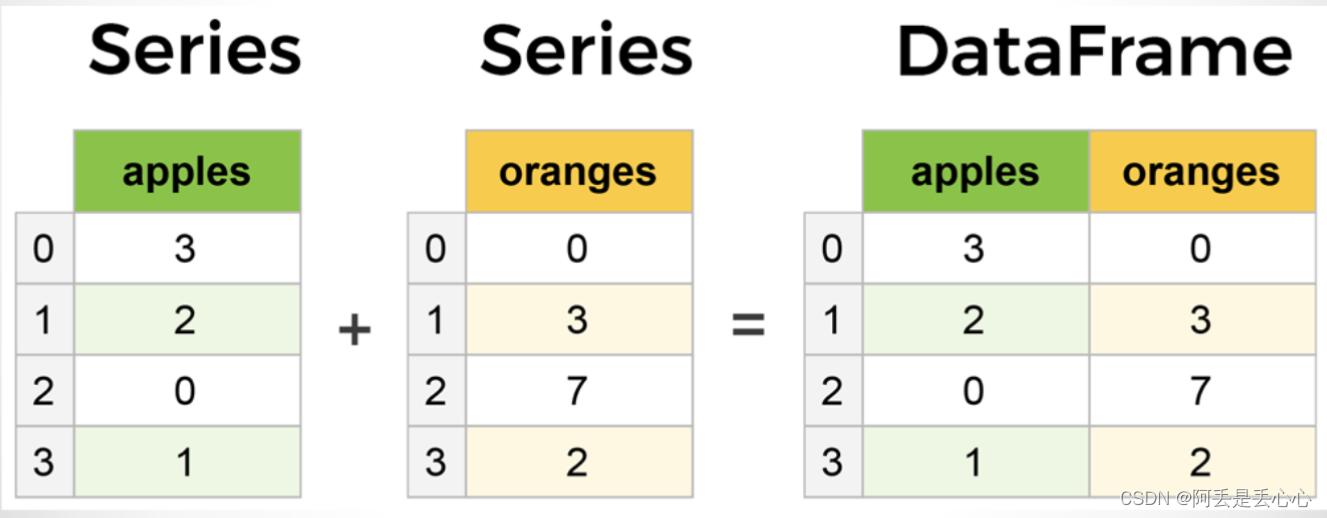
DataFrame是一个表格型的数据结构,其中的数据是以一个或多个二维块存放的,而不是列表、字典或别的一维数据结构。它含有一组有序的列,每列可以是不同的数据类型,它既有行索引,也有列索引。
数据集通常以表格的形式呈现,其中每一行代表一个数据点(或称为样本),每一列代表一个变量(特征变量或目标变量)。
pandas:一维数据结构为series,多维是dataframe
shape()
shape返回的是hg的行数和列数
shape[0]返回的是hg的行数,有几行
shape[1]返回的是hg的列数,有几列
reshape()
在使用Pandas中的reshape()函数时,有两个非常重要的参数,分别是:
index: 将某一列设置为行标签。columns: 将某些列设置为列标签。
melt()
在Pandas中,除了reshape()函数之外,还有一种更加方便的方法可以重新组织数据,那就是melt()函数。使用melt()函数可以将多列压缩成为一列,并将这些列标签转换成行中的某个变量
pivot()
除了使用melt()函数,我们还可以使用pivot()函数将长格式的数据框架变成宽格式的数据框架,和reshape()函数一样,pivot()函数也需要指定行和列标签。