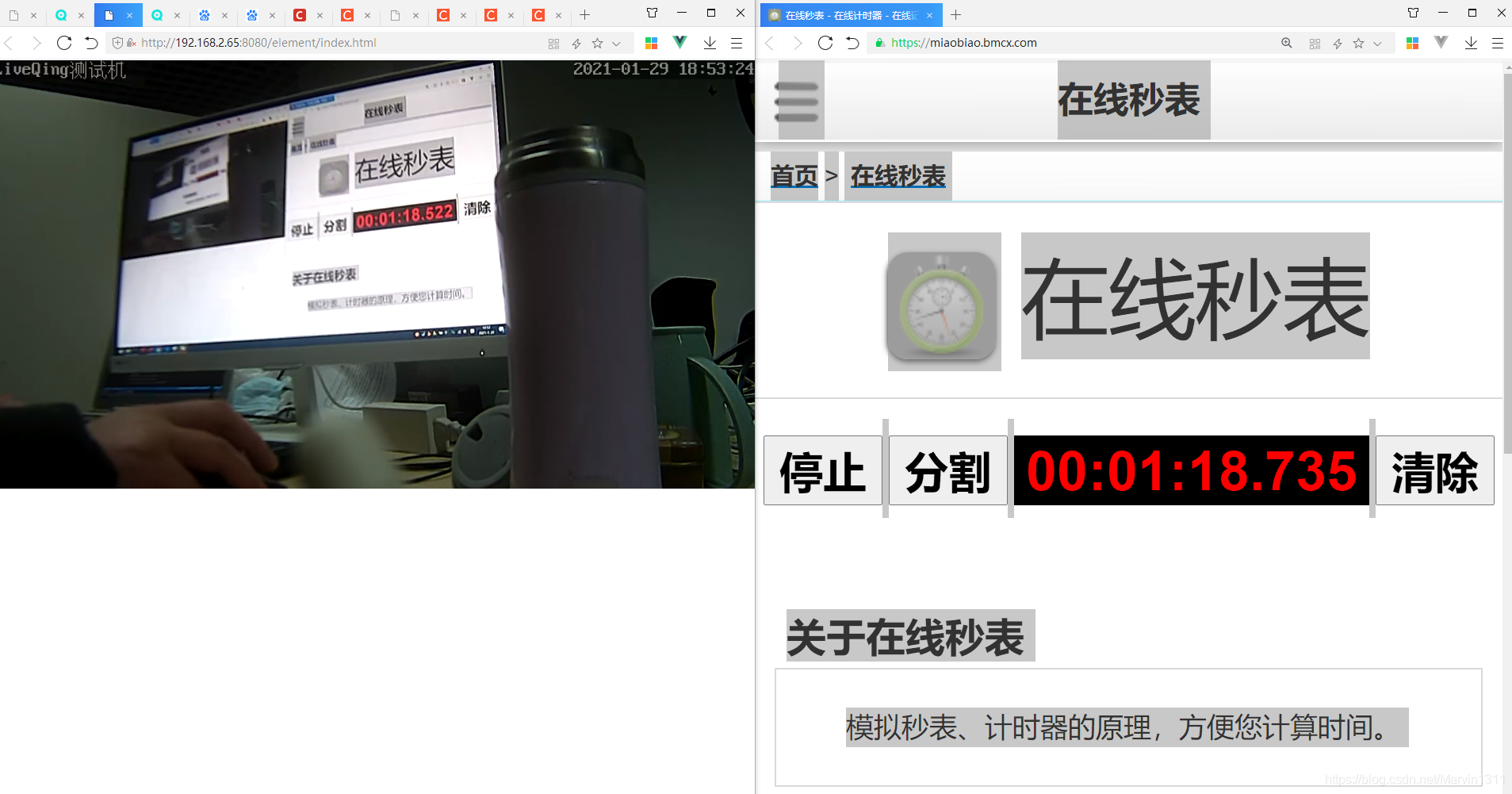
1、Hive 有哪些方式保存元数据,各有哪些优缺点
(1).DerBy数据库:默认自带
优点:使用简单,不需要额外的配置。
缺点:只有一个客户端,多个客户访问会报错。
(2).使用MySql数据库存储
优点:单独的进程,可以在同一台机器上运行,也可以在远程机器上运行。
缺点:使用时需要配置,其中包括copy驱动包,执行初始化指令等。
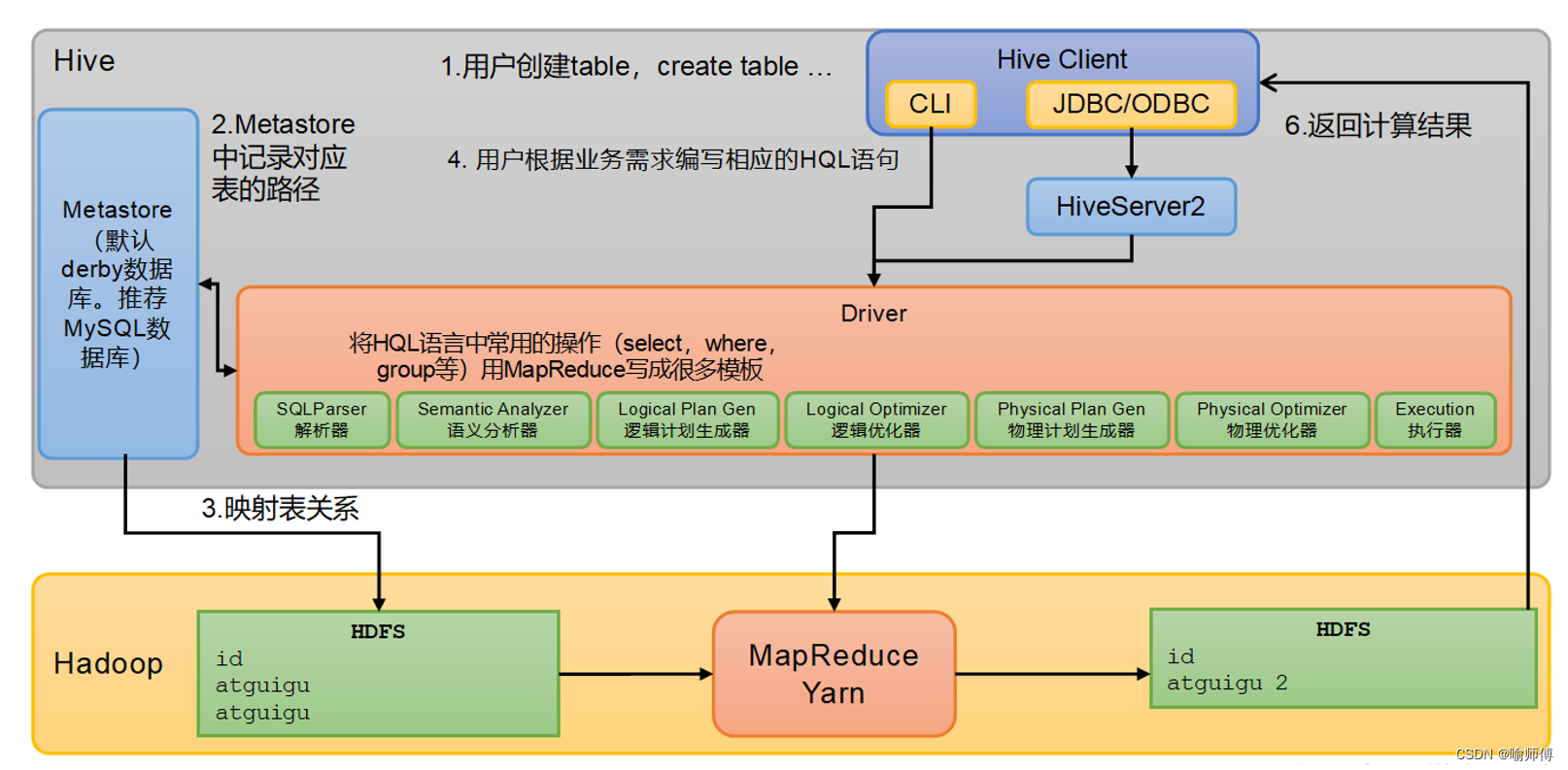
2、Hive的HiveSQL转换为MapReduce的过程?
SQL Parser:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree;
Semantic Analyzer:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree;
Logical plan optimizer: 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
Physical plan:遍历OperatorTree,翻译为MapReduce任务;
Logical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
3、写出hive中split、coalesce及collect_list函数的用法?
split:字符串分割函数,格式为split(字符串,'分隔符'),来实现字符串的分割,返回一个数组
coalesce:该函数格式为(expression1,expression2......,expression_n),依次参照各个参数表达式,遇到非null即返回,倘若所有表达式全部为空,则返回null
collect_list:该函数为聚合函数,将同一分组内的值收集到一个列表之中。
4、Hive内部表和外部表的区别?
Hive内部表与外部表的区别在于内部表有控制器,在删除表时,内部的数据也会被删除,但是外部表不会。
5、Hive 中的压缩格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
(1).TextFile(文本文件)
- 特点: TextFile 是一种简单的文本文件格式,数据以文本形式存储,每行代表一条记录,字段之间通常使用特定的分隔符(如制表符
\t或逗号,)分隔。 - 优点: TextFile 格式简单,易于阅读和处理。
- 缺点: 不适合存储大量结构化数据,查询性能较差,因为每次查询需要扫描整个文件。
(2).SequenceFile(序列文件)
- 特点: SequenceFile 是 Hadoop 中的一种二进制文件格式,它将数据序列化为二进制格式进行存储,支持键值对形式的数据。
- 优点: SequenceFile 适合存储大规模的数据集,可以减少存储空间,并且支持高效的序列化和反序列化操作。
- 缺点: 不太适合直接阅读和处理,需要使用特定的工具或 API 进行操作。
(3). RCFile(记录列文件)
- 特点: RCFile 是一种列式存储文件格式,将数据按列存储,每个列单独存储在文件中,相同列的数据存储在一起。
- 优点: RCFile 适合存储大规模的结构化数据,可以提高查询性能,特别是对于查询特定列的数据时,效率更高。
- 缺点: 对于频繁更新和删除操作的场景,RCFile 可能不太适用。
(4).ORCFile(Optimized Row Columnar File)
- 特点: ORCFile 是一种高度优化的列式存储文件格式,它在 RCFile 的基础上进行了进一步的优化,支持更高的压缩比和更快的查询性能。
- 优点: ORCFile 能够在保证数据压缩的同时提高查询性能,减少 I/O 开销,同时支持更多的数据类型和高级特性,如嵌套数据类型、复杂数据结构等。
- 缺点: ORCFile 文件格式相比其他格式可能稍微复杂一些,但对于大规模数据的存储和查询,通常是更优的选择。
6、Hive函数分为哪三大类?
(1).内置函数(Built-in Functions)
内置函数是 Hive 提供的一组默认函数,用于执行常见的数据操作和计算。这些函数涵盖了各种数据类型和操作,包括字符串操作、数值操作、日期操作、聚合函数等。内置函数通常是高效的,并且在 Hive 中使用广泛。
示例:
- 字符串函数:
substring(),concat(),lower(),upper()等 - 数值函数:
abs(),round(),ceil(),floor()等 - 日期函数:
year(),month(),dayofweek(),datediff()等 - 聚合函数:
sum(),avg(),min(),max()等
(2). 用户自定义函数(User-Defined Functions,UDFs)
用户自定义函数是用户根据自己的需求编写的函数,用于扩展 Hive 的功能。UDFs 可以是标量函数(Scalar UDFs)、聚合函数(Aggregate UDFs)或表生成函数(Table-Generating UDFs),允许用户根据特定的业务逻辑定义自己的函数,以便在 Hive 中使用。
示例:
- 标量函数:自定义一个函数用于计算两个字符串的相似度。
- 聚合函数:自定义一个函数用于计算一组数据的中位数。
- 表生成函数:自定义一个函数用于生成指定格式的数据表。
(3).内置表生成函数(Built-in Table-Generating Functions)
内置表生成函数是一类特殊的内置函数,用于生成表格化的数据输出。这些函数通常用于查询操作或者连接操作中,可以生成结果数据的格式化输出。
示例:
explode(): 将一个数组列拆分成多行。inline(): 将 MAP 类型列展开成键值对形式的多行输出。json_tuple(): 从 JSON 字符串中提取指定键的值。
7、Hive的动态分区和静态分区?使用动态分区两个具体事项?
区别:
静态分区:静态分区是手动指定,有没有结果集都会创建
动态分区:是通过数据来进行判断,只有有结果集时才会创建,没有则不创建。
注意事项:
1-需要先将动态分区设置打开(set hive.exec.dynamic.partition.mode=nonstrict )
2-通过普通表选出的字段包含分区字段,分区字段放置在最后,多个分区字段按照分区顺序放置
8、大数据项目的数据仓库是如何设计数据分层的,阐述每层的具体做的事情?
此层可以细分为三层:
明细层DWD(Data Warehouse Detail):存储明细数据,此数据是最细粒度的事实数据。该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
中间层DWM(Data WareHouse Middle):存储中间数据,为数据统计需要创建的中间表数据,此数据一般是对多个维度的聚合数据,此层数据通常来源于DWD层的数据。
业务层DWS(Data WareHouse Service):存储宽表数据,此层数据是针对某个业务领域的聚合数据,业务层的数据通常来源与此层,为什么叫宽表,主要是为了业务层的需要在这一层将业务相关的所有数据统一汇集起来进行存储,方便业务层获取。此层数据通常来源与DWD和DWM层的数据。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS亦可。
9、大数据项目是如何组织的?请以一个看板为例梳理业务看板具体的构建流程及思路?
数据采集,数据存储,数据分析,数据清洗,数据展示。
教育项目看板构建流程思路分别从建模,数据采集,数据存储,数据分析,指标分析,任务调度回答。
10、美图鉴赏