Flink和Spark的区别主要体现在以下几个方面:
- 数据处理模型:
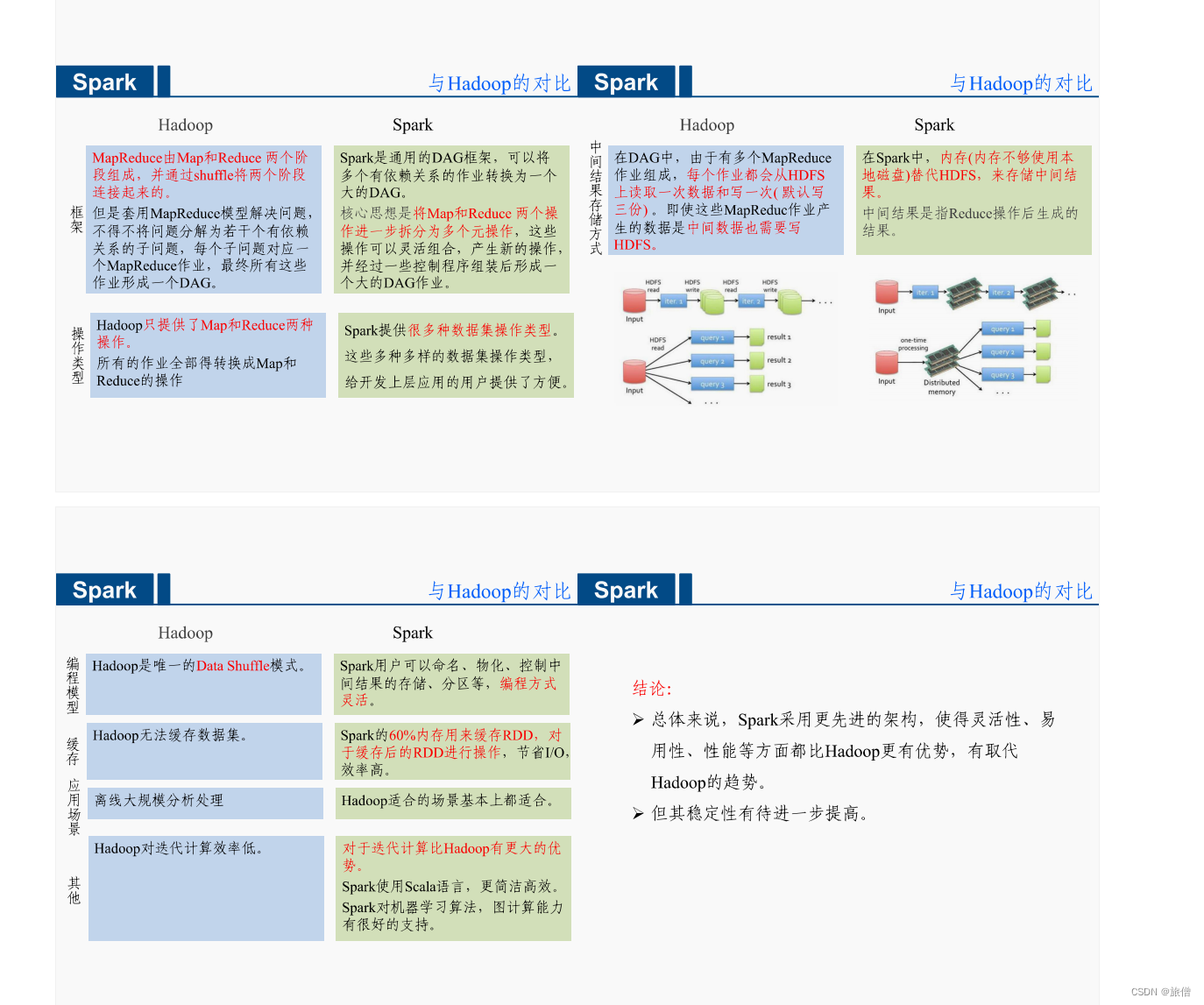
- Flink是一个流处理引擎,同时支持批处理和流处理,可以在同一个引擎上进行实时和离线数据处理,且流处理性能较好,延迟可达到毫秒级。它还支持基于事件时间的处理模型,可以确保数据的顺序和完整性。1
- Spark主要是一个批处理引擎,虽然也支持流处理,但是需要通过Spark Streaming或Structured Streaming来实现,且其流处理模式是基于微批处理的,即将数据分成小的批次进行处理,因此会有一定的延迟,通常延迟较高。12
- 状态管理:
- Flink提供了内置的状态管理功能,可以将数据状态保存在内存或者持久化到外部存储系统中,这使得处理复杂的有状态流处理任务更加方便。
- Spark则需要使用外部的存储系统来管理状态,如HDFS或者数据库。
- 执行引擎:
- Flink采用了基于数据流的执行引擎,可以对数据流进行优化和调度,提供较低的延迟和较高的吞吐量。
- Spark采用了基于RDD的执行引擎,对于批处理任务有更好的性能表现,但处理实时数据时延迟相对较高。
- 生态系统:
- Spark拥有更广泛的生态系统,包括Spark SQL、Spark Streaming、MLlib和GraphX等模块,用户可以在一个统一的框架中进行多种数据处理任务。2
- Flink的生态系统相对较小,但也在不断发展。
综上所述,Flink和Spark各有优势,分别适用于不同的数据处理场景。Flink更适合需要低延迟、高吞吐量的实时流处理场景,而Spark则更适合批处理和大规模数据处理任务,同时提供了丰富的生态系统和高级API支持。