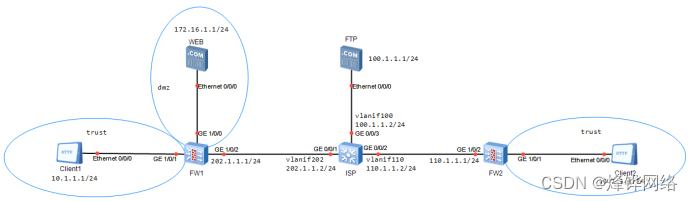
1 概述
SARSA 算法是在 Q-Learning 算法基础上实现的,如果对 Q-Learning 算法了解较少,建议先学习一下:Q-Learning 算法。
SARSA 是指state、action、reward、state’、action’五个单词,后见会看到这五个单词的作用。
2 SARSA 与 Q-Learning
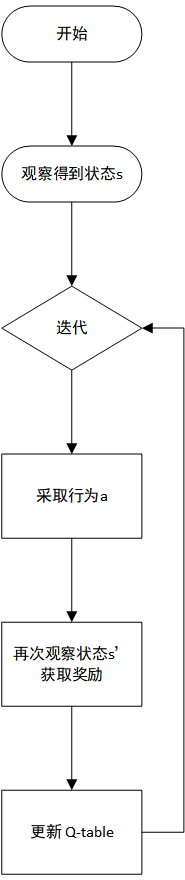
SARSA 算法与 Q-Learning 算法的学习流程都如上所示。
接下来通过 SARSA 算法与 Q-Learning 算法的对比来学习 SARSA 算法。
2.1 Q-value 更新
两个算法其实差不太多,他们的区别主要是更新 Q-value 的方式不同。
Q-Learning 算法一般使用 TD 更新 Q-value,公式如下:

而 SARSA 算法的更新策略则如下:

比较两者:
- Q-Learning 是在下一步 state’ 的所有可能的选择中,挑取 Q-value 最大的 action‘,来假设为下一步动作,然后用这个 action 对应的 Q-value’ 来更新当前 state 和当前 action 所对应的 Q-value。
- SARSA 则不做假设,也就是说,他会等下一步真的做完 action‘,在根据 state’ 和真正的 action’ 所对应的 Q-value’ 来更新当前 state 和当前 action 所对应的 Q-value。
可以看到,SARSA 更新 Q-value 所使用的公式中需要state、action、reward、state‘、action,这也就是它的名字的由来。
2.2 off-policy 和 on-policy
off-policy 称为异策略,就是指行动策略和评估策略不是同一个策略。反之,on-policy 成为同策略,就是指行动策略和评估策略是同一个策略。
- Q-Learning 是 off-policy。行动策略采用了 ε-Greedy 策略,而评估策略采用了取 max{Q(s,a)} 的贪心策略。
- SARSA 是 on-policy。行动策略和评估策略都采用了 ε-Greedy 策略。
因此 Q-Learning 的学习过程更具有探索性,SARSA 则相对保守。
3 SARSA(λ) 算法
前面所说的 Q-Learning 和 SARSA 都是根据下一步来更新当前的 Q-value,如果想要根据接下来 n 步更新 Q-value 的话,就可以使用 SARSA(λ) 算法。如果 n 为一个回合(episode)的步数,就变成了回合更新。λ 是衰减值,取值范围是 [ 0 , 1 ]。
3.1 E 表
Agent 在一个 episode 中,会经历若干步,需要将这些步记录下来。对此,需要创建一个二维矩阵来存储 Agent 在一个 episode 经历的所有情况。
假设当前 Agent 的经历为:s1,a2,s2,a1,s3,a3,s4,a4,…
E 表就可能如下:

(1)初始化
初始可以使所有数据都为0。、
(2)数值更新
当 Agent 当前情况为 (s,a)时。
对 E(s,a) 更新有两种方式:
- 第一种:直接加一。

- 第二种:将当前 s 行所有数值清 0,然后E(s,a)置 1。

一般情况下可以选择第二种。
对 E(s,a) 以外的 E 值更新为:

如果没经历过 (s*,a*),那么 E(s*,a*) 始终为 0。如果经历过 (s*,a*),那么 E(s*,a*) 每次衰减 γ λ 倍。
3.2 数值更新
需要注意的是,每一步先更新 Q-value,在更新 E 表。
假设当前为 (s,a),下一步为 (s’,a’),则数值更新步骤如下: