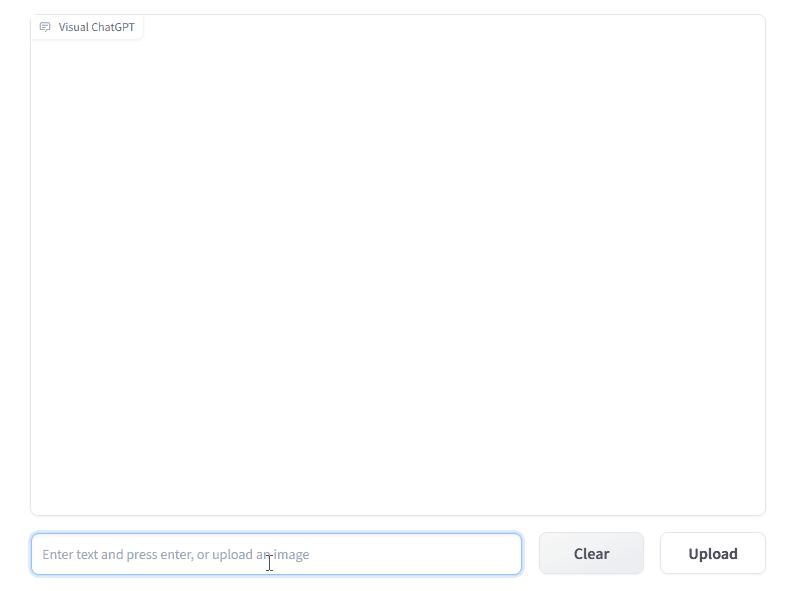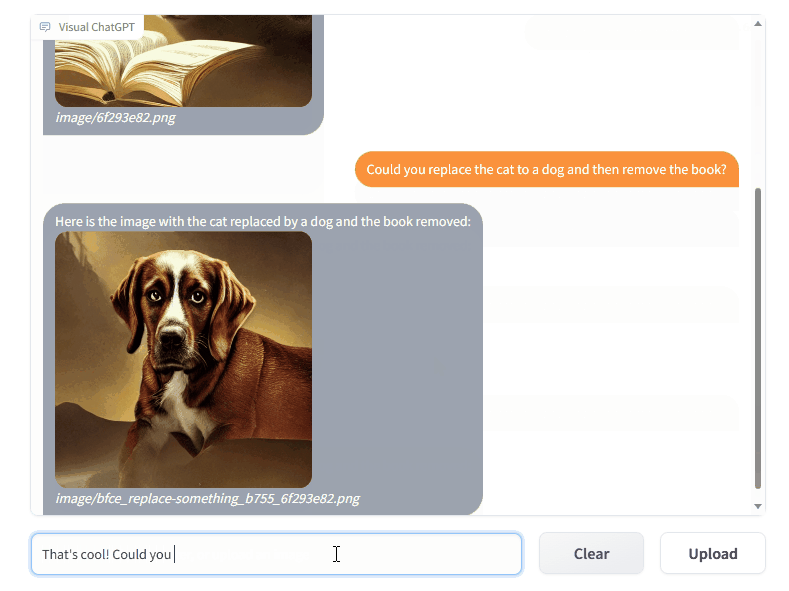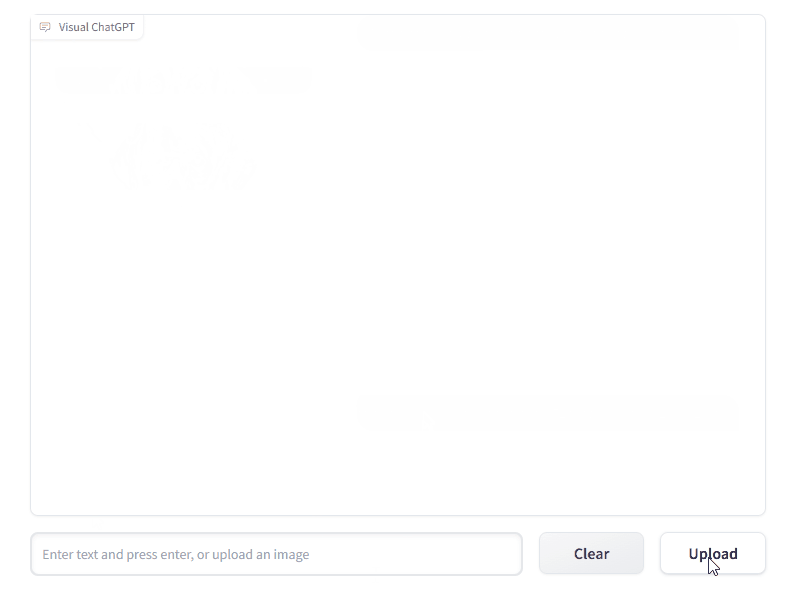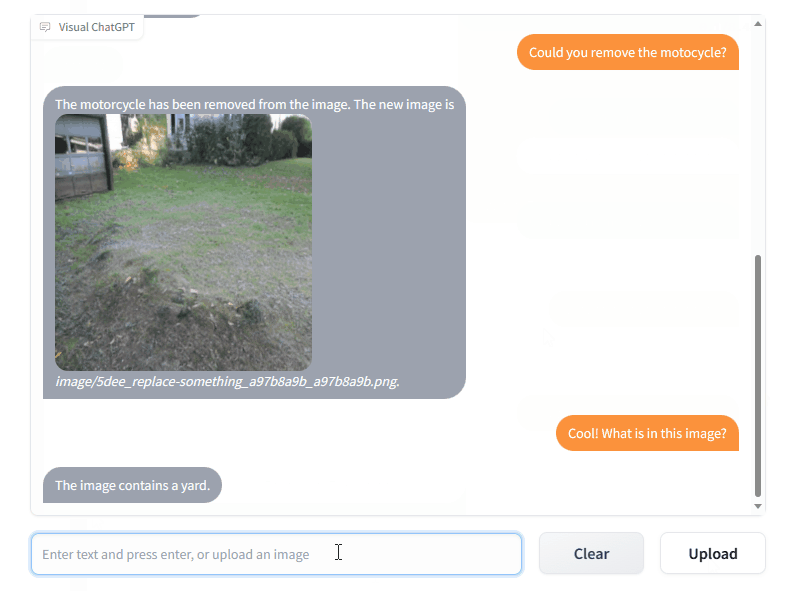
一. 先上效果
TaskMatrix通过ChatGPT 和一系列 Visual Foundation 模型,通过聊天实现图片的绘制、问答和编辑。
二. 流程概览

1. 使用者流程
多模型会话上下文+用户指令输入到本系统 -> 多模式会话基础模型 -> 理解用户指令上下文,调用API选择器,选择合适的APIs组成调用队列 -> 动作执行器基于调用队列,依次调用技能库的API,直至完成任务 -> 任务调用效果通过人类反馈,持续优化多模式会话基础模型,优化模型效果。同时部分需求反馈到API开发者,进入开发者流程
2. 开发者流程
任务调用效果反馈 -> 研发人员优化完善技能库 -> 技能库(位置API、购物API、设备API……) -> 技能库发布到API平台(具有统一API文档结构的大量API集合)
3. 应用场景
工业机器人、办公自动化、物联网、各种助手……
三. 核心原理
将统一API文档结构的API注册为langchain的自定义工具,通过与LangChain封装的底层调用LLM(OpenAI)语义理解并函数调用,实现自定义工具的调用。
四.代码解析
1. 整体处理流程
+------------------+
| 程序开始 |
+------------------+
|
v
+------------------+
| 解析命令行参数 |
+------------------+
|
v
+------------------+
| 初始化ConversationBot |
+------------------+
|
v
+------------------+
| 启动Gradio应用 |
+------------------+
/ \
/ \
/ \
/ \
v v
+--------+ +--------+
| 文本输入 | | 图像输入 |
+--------+ +--------+
| |
v v
+--------+ +--------+
| 处理文本 | | 处理图像 |
+--------+ +--------+
| |
v v
+------------------+
| Gradio显示响应 |
+------------------+
2. 核心函数ConversationBot
2.1 __init__函数
__init__函数主要完成以下几个任务:
- 加载基础模型和模板模型。
- 初始化代理工具。
- 初始化对话内存。
class ConversationBot:
def __init__(self, load_dict):
# load_dict = {'VisualQuestionAnswering':'cuda:0', 'ImageCaptioning':'cuda:1',...}
print(f"Initializing VisualChatGPT, load_dict={load_dict}")
if 'ImageCaptioning' not in load_dict:
raise ValueError("You have to load ImageCaptioning as a basic function for VisualChatGPT")
self.models = {}
# Load Basic Foundation Models
for class_name, device in load_dict.items():
self.models[class_name] = globals()[class_name](device=device)
# Load Template Foundation Models
for class_name, module in globals().items():
if getattr(module, 'template_model', False):
template_required_names = {k for k in inspect.signature(module.__init__).parameters.keys() if k!='self'}
loaded_names = set([type(e).__name__ for e in self.models.values()])
if template_required_names.issubset(loaded_names):
self.models[class_name] = globals()[class_name](
**{name: self.models[name] for name in template_required_names})
print(f"All the Available Functions: {self.models}")
self.tools = []
for instance in self.models.values():
for e in dir(instance):
if e.startswith('inference'):
func = getattr(instance, e)
self.tools.append(Tool(name=func.name, description=func.description, func=func))
self.llm = OpenAI(temperature=0)
self.memory = ConversationBufferMemory(memory_key="chat_history", output_key='output')
详细解析:
1.模型加载:
首先,检查load_dict是否包含ImageCaptioning,如果不包含,则抛出一个ValueError。
if 'ImageCaptioning' not in load_dict:
raise ValueError("You have to load ImageCaptioning as a basic function for VisualChatGPT")
然后,遍历load_dict中的每个项,加载基础模型。
self.models = {}
for class_name, device in load_dict.items():
self.models[class_name] = globals()[class_name](device=device)
2.模板模型加载:
接着,遍历全局变量中的每个项,如果该项是一个模板模型,检查其所需的所有模型是否都已加载,如果是,则加载该模板模型。
for class_name, module in globals().items():
if getattr(module, 'template_model', False):
template_required_names = {k for k in inspect.signature(module.__init__).parameters.keys() if k!='self'}
loaded_names = set([type(e).__name__ for e in self.models.values()])
if template_required_names.issubset(loaded_names):
self.models[class_name] = globals()[class_name](
**{name: self.models[name] for name in template_required_names})
3.工具初始化:
接下来,遍历加载的所有模型,对于每个模型,检查其是否有以inference开头的方法,如果有,则创建一个Tool实例并添加到self.tools列表中。
self.tools = []
for instance in self.models.values():
for e in dir(instance):
if e.startswith('inference'):
func = getattr(instance, e)
self.tools.append(Tool(name=func.name, description=func.description, func=func))
4.OpenAI模型初始化:
初始化OpenAI的语言模型。
self.llm = OpenAI(temperature=0)
5.对话内存初始化:
初始化对话内存。
self.memory = ConversationBufferMemory(memory_key="chat_history", output_key='output')
2.2 init_agent函数
init_agent函数主要完成以下几个任务:
- 清空对话内存。
- 根据指定的语言加载对应的对话前缀、格式指令和后缀。
- 初始化代理工具。
def init_agent(self, lang):
self.memory.clear() #clear previous history
if lang=='English':
PREFIX, FORMAT_INSTRUCTIONS, SUFFIX = VISUAL_CHATGPT_PREFIX, VISUAL_CHATGPT_FORMAT_INSTRUCTIONS, VISUAL_CHATGPT_SUFFIX
place = "Enter text and press enter, or upload an image"
label_clear = "Clear"
else:
PREFIX, FORMAT_INSTRUCTIONS, SUFFIX = VISUAL_CHATGPT_PREFIX_CN, VISUAL_CHATGPT_FORMAT_INSTRUCTIONS_CN, VISUAL_CHATGPT_SUFFIX_CN
place = "输入文字并回车,或者上传图片"
label_clear = "清除"
self.agent = initialize_agent(
self.tools,
self.llm,
agent="conversational-react-description",
verbose=True,
memory=self.memory,
return_intermediate_steps=True,
agent_kwargs={'prefix': PREFIX, 'format_instructions': FORMAT_INSTRUCTIONS,
'suffix': SUFFIX}, )
return gr.update(visible = True), gr.update(visible = False), gr.update(placeholder=place), gr.update(value=label_clear)
详细解析:
1.清空对话内存:
清空之前的对话历史。
self.memory.clear() #clear previous history
2.加载对话前缀、格式指令和后缀:
根据传入的lang参数,选择相应的对话前缀、格式指令和后缀。
if lang=='English':
PREFIX, FORMAT_INSTRUCTIONS, SUFFIX = VISUAL_CHATGPT_PREFIX, VISUAL_CHATGPT_FORMAT_INSTRUCTIONS, VISUAL_CHATGPT_SUFFIX
place = "Enter text and press enter, or upload an image"
label_clear = "Clear"
else:
PREFIX, FORMAT_INSTRUCTIONS, SUFFIX = VISUAL_CHATGPT_PREFIX_CN, VISUAL_CHATGPT_FORMAT_INSTRUCTIONS_CN, VISUAL_CHATGPT_SUFFIX_CN
place = "输入文字并回车,或者上传图片"
label_clear = "清除"
3.初始化代理工具:使用initialize_agent函数初始化代理工具,并设置相关参数。
self.agent = initialize_agent(
self.tools,
self.llm,
agent="conversational-react-description",
verbose=True,
memory=self.memory,
return_intermediate_steps=True,
agent_kwargs={'prefix': PREFIX, 'format_instructions': FORMAT_INSTRUCTIONS,
'suffix': SUFFIX}, )
4.更新界面状态:返回更新后的界面状态。
return gr.update(visible = True), gr.update(visible = False), gr.update(placeholder=place), gr.update(value=label_clear)
2.3 run_text函数
run_text函数的主要功能是处理文本输入并返回相应的回复。
def run_text(self, text, state):
self.agent.memory.buffer = cut_dialogue_history(self.agent.memory.buffer, keep_last_n_words=500)
res = self.agent({"input": text.strip()})
res['output'] = res['output'].replace("\\", "/")
response = re.sub('(image/[-\w]*.png)', lambda m: f'})*{m.group(0)}*', res['output'])
state = state + [(text, response)]
print(f"\nProcessed run_text, Input text: {text}\nCurrent state: {state}\n"
f"Current Memory: {self.agent.memory.buffer}")
return state, state
详细解析:
1.清除对话历史:使用cut_dialogue_history函数清除对话历史,只保留最后的500个词。
self.agent.memory.buffer = cut_dialogue_history(self.agent.memory.buffer, keep_last_n_words=500)
2.处理文本输入:使用LangChain代理工具(self.agent),调用绑定的大语言模型处理输入文本,并获取回复。
res = self.agent({"input": text.strip()})
3.处理输出中的图片链接:替换回复中的图片链接为Markdown格式的图片显示。
res['output'] = res['output'].replace("\\", "/")
response = re.sub('(image/[-\w]*.png)', lambda m: f'})*{m.group(0)}*', res['output'])
4.更新对话状态:将输入文本和回复添加到对话状态(state)中。
state = state + [(text, response)]
2.4 run_image函数
run_image函数的主要功能是处理图像输入并返回相应的回复。
def run_image(self, image, state, txt, lang):
image_filename = os.path.join('image', f"{str(uuid.uuid4())[:8]}.png")
print("======>Auto Resize Image...")
img = Image.open(image.name)
width, height = img.size
ratio = min(512 / width, 512 / height)
width_new, height_new = (round(width * ratio), round(height * ratio))
width_new = int(np.round(width_new / 64.0)) * 64
height_new = int(np.round(height_new / 64.0)) * 64
img = img.resize((width_new, height_new))
img = img.convert('RGB')
img.save(image_filename, "PNG")
print(f"Resize image form {width}x{height} to {width_new}x{height_new}")
description = self.models['ImageCaptioning'].inference(image_filename)
if lang == 'Chinese':
Human_prompt = f'\nHuman: 提供一张名为 {image_filename}的图片。它的描述是: {description}。 这些信息帮助你理解这个图像,但是你应该使用工具来完成下面的任务,而不是直接从我的描述中想象。 如果你明白了, 说 \"收到\". \n'
AI_prompt = "收到。 "
else:
Human_prompt = f'\nHuman: provide a figure named {image_filename}. The description is: {description}. This information helps you to understand this image, but you should use tools to finish following tasks, rather than directly imagine from my description. If you understand, say \"Received\". \n'
AI_prompt = "Received. "
self.agent.memory.buffer = self.agent.memory.buffer + Human_prompt + 'AI: ' + AI_prompt
state = state + [(f"*{image_filename}*", AI_prompt)]
print(f"\nProcessed run_image, Input image: {image_filename}\nCurrent state: {state}\n"
f"Current Memory: {self.agent.memory.buffer}")
return state, state, f'{txt} {image_filename} '
详细解析:
1.图像预处理:生成一个唯一的图像文件名。自动调整图像大小,并将其保存。
image_filename = os.path.join('image', f"{str(uuid.uuid4())[:8]}.png")
print("======>Auto Resize Image...")
img = Image.open(image.name)
width, height = img.size
ratio = min(512 / width, 512 / height)
width_new, height_new = (round(width * ratio), round(height * ratio))
width_new = int(np.round(width_new / 64.0)) * 64
height_new = int(np.round(height_new / 64.0)) * 64
img = img.resize((width_new, height_new))
img = img.convert('RGB')
img.save(image_filename, "PNG")
print(f"Resize image form {width}x{height} to {width_new}x{height_new}")
2.获取图像描述:使用ImageCaptioning模型获取图像的描述。
description = self.models['ImageCaptioning'].inference(image_filename)
3.设置对话提示:根据语言设置相应的对话提示,并将其添加到对话内存中。
if lang == 'Chinese':
Human_prompt = f'\nHuman: 提供一张名为 {image_filename}的图片。它的描述是: {description}。 这些信息帮助你理解这个图像,但是你应该使用工具来完成下面的任务,而不是直接从我的描述中想象。 如果你明白了, 说 \"收到\". \n'
AI_prompt = "收到。 "
else:
Human_prompt = f'\nHuman: provide a figure named {image_filename}. The description is: {description}. This information helps you to understand this image, but you should use tools to finish following tasks, rather than directly imagine from my description. If you understand, say \"Received\". \n'
AI_prompt = "Received. "
4.更新对话状态:将输入图像和回复添加到对话状态(state)中。
self.agent.memory.buffer = self.agent.memory.buffer + Human_prompt + 'AI: ' + AI_prompt
state = state + [(f"*{image_filename}*", AI_prompt)]
五. 附录
1.核心提示词工程
VISUAL_CHATGPT_PREFIX = """Visual ChatGPT is designed to be able to assist with a wide range of text and visual related tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. Visual ChatGPT is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Visual ChatGPT is able to process and understand large amounts of text and images. As a language model, Visual ChatGPT can not directly read images, but it has a list of tools to finish different visual tasks. Each image will have a file name formed as "image/xxx.png", and Visual ChatGPT can invoke different tools to indirectly understand pictures. When talking about images, Visual ChatGPT is very strict to the file name and will never fabricate nonexistent files. When using tools to generate new image files, Visual ChatGPT is also known that the image may not be the same as the user's demand, and will use other visual question answering tools or description tools to observe the real image. Visual ChatGPT is able to use tools in a sequence, and is loyal to the tool observation outputs rather than faking the image content and image file name. It will remember to provide the file name from the last tool observation, if a new image is generated.
Human may provide new figures to Visual ChatGPT with a description. The description helps Visual ChatGPT to understand this image, but Visual ChatGPT should use tools to finish following tasks, rather than directly imagine from the description.
Overall, Visual ChatGPT is a powerful visual dialogue assistant tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics.
TOOLS:
------
Visual ChatGPT has access to the following tools:"""
VISUAL_CHATGPT_FORMAT_INSTRUCTIONS = """To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
{ai_prefix}: [your response here]
```
"""
VISUAL_CHATGPT_SUFFIX = """You are very strict to the filename correctness and will never fake a file name if it does not exist.
You will remember to provide the image file name loyally if it's provided in the last tool observation.
Begin!
Previous conversation history:
{chat_history}
New input: {input}
Since Visual ChatGPT is a text language model, Visual ChatGPT must use tools to observe images rather than imagination.
The thoughts and observations are only visible for Visual ChatGPT, Visual ChatGPT should remember to repeat important information in the final response for Human.
Thought: Do I need to use a tool? {agent_scratchpad} Let's think step by step.
"""
VISUAL_CHATGPT_PREFIX_CN = """Visual ChatGPT 旨在能够协助完成范围广泛的文本和视觉相关任务,从回答简单的问题到提供对广泛主题的深入解释和讨论。 Visual ChatGPT 能够根据收到的输入生成类似人类的文本,使其能够进行听起来自然的对话,并提供连贯且与手头主题相关的响应。
Visual ChatGPT 能够处理和理解大量文本和图像。作为一种语言模型,Visual ChatGPT 不能直接读取图像,但它有一系列工具来完成不同的视觉任务。每张图片都会有一个文件名,格式为“image/xxx.png”,Visual ChatGPT可以调用不同的工具来间接理解图片。在谈论图片时,Visual ChatGPT 对文件名的要求非常严格,绝不会伪造不存在的文件。在使用工具生成新的图像文件时,Visual ChatGPT也知道图像可能与用户需求不一样,会使用其他视觉问答工具或描述工具来观察真实图像。 Visual ChatGPT 能够按顺序使用工具,并且忠于工具观察输出,而不是伪造图像内容和图像文件名。如果生成新图像,它将记得提供上次工具观察的文件名。
Human 可能会向 Visual ChatGPT 提供带有描述的新图形。描述帮助 Visual ChatGPT 理解这个图像,但 Visual ChatGPT 应该使用工具来完成以下任务,而不是直接从描述中想象。有些工具将会返回英文描述,但你对用户的聊天应当采用中文。
总的来说,Visual ChatGPT 是一个强大的可视化对话辅助工具,可以帮助处理范围广泛的任务,并提供关于范围广泛的主题的有价值的见解和信息。
工具列表:
------
Visual ChatGPT 可以使用这些工具:"""
VISUAL_CHATGPT_FORMAT_INSTRUCTIONS_CN = """用户使用中文和你进行聊天,但是工具的参数应当使用英文。如果要调用工具,你必须遵循如下格式:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
当你不再需要继续调用工具,而是对观察结果进行总结回复时,你必须使用如下格式:
```
Thought: Do I need to use a tool? No
{ai_prefix}: [your response here]
```
"""
VISUAL_CHATGPT_SUFFIX_CN = """你对文件名的正确性非常严格,而且永远不会伪造不存在的文件。
开始!
因为Visual ChatGPT是一个文本语言模型,必须使用工具去观察图片而不是依靠想象。
推理想法和观察结果只对Visual ChatGPT可见,需要记得在最终回复时把重要的信息重复给用户,你只能给用户返回中文句子。我们一步一步思考。在你使用工具时,工具的参数只能是英文。
聊天历史:
{chat_history}
新输入: {input}
Thought: Do I need to use a tool? {agent_scratchpad}
"""2.工具清单
基础模型 |
工具名称 |
工具描述 |
运行显存 (MB) |
Inpainting/InfinityOutPainting |
Extend An Image |
"useful when you need to extend an image into a larger image." "like: extend the image into a resolution of 2048x1024, extend the image into 2048x1024. " "The input to this tool should be a comma separated string of two, representing the image_path and the resolution of widthxheight" |
|
ObjectSegmenting |
egment the given object |
"useful when you only want to segment the certain objects in the picture" "according to the given text" "like: segment the cat," "or can you segment an obeject for me" "The input to this tool should be a comma separated string of two, " "representing the image_path, the text description of the object to be found" |
|
BackgroundRemoving |
Remove the background |
"useful when you want to extract the object or remove the background," "the input should be a string image_path" |
|
Segmenting |
Segment the Image |
"useful when you want to segment all the part of the image, but not segment a certain object." "like: segment all the object in this image, or generate segmentations on this image, " "or segment the image," "or perform segmentation on this image, " "or segment all the object in this image." "The input to this tool should be a string, representing the image_path" |
|
Text2Box |
Detect the Give Object |
"useful when you only want to detect or find out given objects in the picture" "The input to this tool should be a comma separated string of two, " "representing the image_path, the text description of the object to be found" |
|
ImageEditing |
Remove Something From The Photo |
"useful when you want to remove and object or something from the photo " "from its description or location. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the object need to be removed. " |
3981 |
Replace Something From The Photo |
"useful when you want to replace an object from the object description or " "location with another object from its description. " "The input to this tool should be a comma separated string of three, " "representing the image_path, the object to be replaced, the object to be replaced with " |
||
InstructPix2Pix |
Instruct Image Using Text |
useful when you want to the style of the image to be like the text. " "like: make it look like a painting. or make it like a robot. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the text. |
2827 |
Text2Image |
Generate Image From User Input Text |
useful when you want to generate an image from a user input text and save it to a file. " "like: generate an image of an object or something, or generate an image that includes some objects. " "The input to this tool should be a string, representing the text used to generate image. |
3385 |
ImageCaptioning |
Get Photo Description |
useful when you want to know what is inside the photo. receives image_path as input. " "The input to this tool should be a string, representing the image_path. |
1209 |
Image2Canny |
Edge Detection On Image |
useful when you want to detect the edge of the image. " "like: detect the edges of this image, or canny detection on image, " "or perform edge detection on this image, or detect the canny image of this image. " "The input to this tool should be a string, representing the image_path |
0 |
CannyText2Image |
Generate Image Condition On Canny Image |
"useful when you want to generate a new real image from both the user description and a canny image." " like: generate a real image of a object or something from this canny image," " or generate a new real image of a object or something from this edge image. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description. " |
3531 |
Image2Line |
Line Detection On Image |
"useful when you want to detect the straight line of the image. " "like: detect the straight lines of this image, or straight line detection on image, " "or perform straight line detection on this image, or detect the straight line image of this image. " "The input to this tool should be a string, representing the image_path" |
0 |
LineText2Image |
Generate Image Condition On Line Image |
"useful when you want to generate a new real image from both the user description " "and a straight line image. " "like: generate a real image of a object or something from this straight line image, " "or generate a new real image of a object or something from this straight lines. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description. " |
3529 |
Image2Hed |
Hed Detection On Image |
"useful when you want to detect the soft hed boundary of the image. " "like: detect the soft hed boundary of this image, or hed boundary detection on image, " "or perform hed boundary detection on this image, or detect soft hed boundary image of this image. " "The input to this tool should be a string, representing the image_path" |
0 |
HedText2Image |
Generate Image Condition On Soft Hed Boundary Image |
"useful when you want to generate a new real image from both the user description " "and a soft hed boundary image. " "like: generate a real image of a object or something from this soft hed boundary image, " "or generate a new real image of a object or something from this hed boundary. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description" |
3529 |
Image2Scribble |
Sketch Detection On Image |
"useful when you want to generate a scribble of the image. " "like: generate a scribble of this image, or generate a sketch from this image, " "detect the sketch from this image. " "The input to this tool should be a string, representing the image_path" |
0 |
ScribbleText2Image |
Generate Image Condition On Sketch Image |
"useful when you want to generate a new real image from both the user description and " "a scribble image or a sketch image. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description" |
3531 |
Image2Pose |
Pose Detection On Image |
"useful when you want to detect the human pose of the image. " "like: generate human poses of this image, or generate a pose image from this image. " "The input to this tool should be a string, representing the image_path" |
0 |
PoseText2Image |
Generate Image Condition On Pose Image |
"useful when you want to generate a new real image from both the user description " "and a human pose image. " "like: generate a real image of a human from this human pose image, " "or generate a new real image of a human from this pose. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description" |
3529 |
Image2Seg |
Predict Depth On Image |
"useful when you want to detect depth of the image. like: generate the depth from this image, " "or detect the depth map on this image, or predict the depth for this image. " "The input to this tool should be a string, representing the image_path" |
919 |
SegText2Image |
Generate Image Condition On Segmentations |
"useful when you want to generate a new real image from both the user description and segmentations. " "like: generate a real image of a object or something from this segmentation image, " "or generate a new real image of a object or something from these segmentations. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description" |
3529 |
Image2Depth |
Predict Depth On Image |
"useful when you want to detect depth of the image. like: generate the depth from this image, " "or detect the depth map on this image, or predict the depth for this image. " "The input to this tool should be a string, representing the image_path" |
0 |
DepthText2Image |
Generate Image Condition On Depth |
"useful when you want to generate a new real image from both the user description and depth image. " "like: generate a real image of a object or something from this depth image, " "or generate a new real image of a object or something from the depth map. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description" |
3531 |
Image2Normal |
Predict Normal Map On Image |
"useful when you want to detect norm map of the image. " "like: generate normal map from this image, or predict normal map of this image. " "The input to this tool should be a string, representing the image_path" |
0 |
NormalText2Image |
Generate Image Condition On Normal Map |
"useful when you want to generate a new real image from both the user description and normal map. " "like: generate a real image of a object or something from this normal map, " "or generate a new real image of a object or something from the normal map. " "The input to this tool should be a comma separated string of two, " "representing the image_path and the user description" |
3529 |
VisualQuestionAnswering |
Answer Question About The Image |
"useful when you need an answer for a question based on an image. " "like: what is the background color of the last image, how many cats in this figure, what is in this figure. " "The input to this tool should be a comma separated string of two, representing the image_path and the question" |
1495 |






















![[网鼎杯 2020 青龙组]AreUSerialz](https://img-blog.csdnimg.cn/direct/414b2bb89c554c538e18c780330bd58c.png)