这里写目录标题
1.树的基础
1.1 首次理解
void traverse(TreeNode root) {
if (root == null) {
return;
}
// 前序位置 刚进入这个节点时
traverse(root.left);
// 中序位置 马上要进入右孩子时
traverse(root.right);
// 后序位置 马上要退出这个节点时
}
前中后序是遍历二叉树过程中处理每一个节点的三个特殊时间点,绝不仅仅是三个顺序不同的 List:
前序位置的代码在刚刚进入一个二叉树节点的时候执行;
后序位置的代码在将要离开一个二叉树节点的时候执行;
中序位置的代码在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候执行。
1.2 深入理解
例如前序遍历:

那这不就可以分解问题了么,一棵二叉树的前序遍历结果 = 根节点 + 左子树的前序遍历结果 + 右子树的前序遍历结果。
1.2.1后序位置的特殊之处
说后序位置之前,先简单说下中序和前序。
中序位置主要用在 BST 场景中,你完全可以把 BST 的中序遍历认为是遍历有序数组。
前序位置本身其实没有什么特别的性质,之所以你发现好像很多题都是在前序位置写代码,实际上是因为我们习惯把那些对前中后序位置不敏感的代码写在前序位置罢了。
你可以发现,前序位置的代码执行是自顶向下的,而后序位置的代码执行是自底向上的:
这不奇怪,因为本文开头就说了前序位置是刚刚进入节点的时刻,后序位置是即将离开节点的时刻。
但这里面大有玄妙,意味着前序位置的代码只能从函数参数中获取父节点传递来的数据,而后序位置的代码不仅可以获取参数数据,还可以获取到子树通过函数返回值传递回来的数据。
那这里再举两个例子来区分先序和后序的差别:
1、如果把根节点看做第 1 层,如何打印出每一个节点所在的层数?
2、如何打印出每个节点的左右子树各有多少节点?
这两个问题的根本区别在于:一个节点在第几层,你从根节点遍历过来的过程就能顺带记录,用递归函数的参数就能传递下去;而以一个节点为根的整棵子树有多少个节点,你需要遍历完子树之后才能数清楚,然后通过递归函数的返回值拿到答案。
那么换句话说,一旦你发现题目和子树有关,那大概率要给函数设置合理的定义和返回值,在后序位置写代码了。
例子一的代码:
// 二叉树遍历函数
void traverse(TreeNode root, int level) {
if (root == null) {
return;
}
// 前序位置
printf("节点 %s 在第 %d 层", root, level);
traverse(root.left, level + 1);
traverse(root.right, level + 1);
}
// 这样调用
traverse(root, 1);
例子2的代码:
// 定义:输入一棵二叉树,返回这棵二叉树的节点总数
int count(TreeNode root) {
if (root == null) {
return 0;
}
int leftCount = count(root.left);
int rightCount = count(root.right);
// 后序位置
printf("节点 %s 的左子树有 %d 个节点,右子树有 %d 个节点",
root, leftCount, rightCount);
return leftCount + rightCount + 1;
}
1.2.2 二叉树的思维指导
二叉树解题的思维模式分两类:
1、是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
其中最重要的是:
如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做? 其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
关于二叉树思维的例题请见例题2.3-2.5
1.3 层序遍历
// 输入一棵二叉树的根节点,层序遍历这棵二叉树
void levelTraverse(TreeNode root) {
if (root == null) return;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
// 从上到下遍历二叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
// 将下一层节点放入队列
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
}
}
1.4 二叉搜索树 BST
BST 的基础操作主要依赖「左小右大」的特性,可以在二叉树中做类似二分搜索的操作,寻找一个元素的效率很高。
比如下面这就是一棵合法的二叉树:
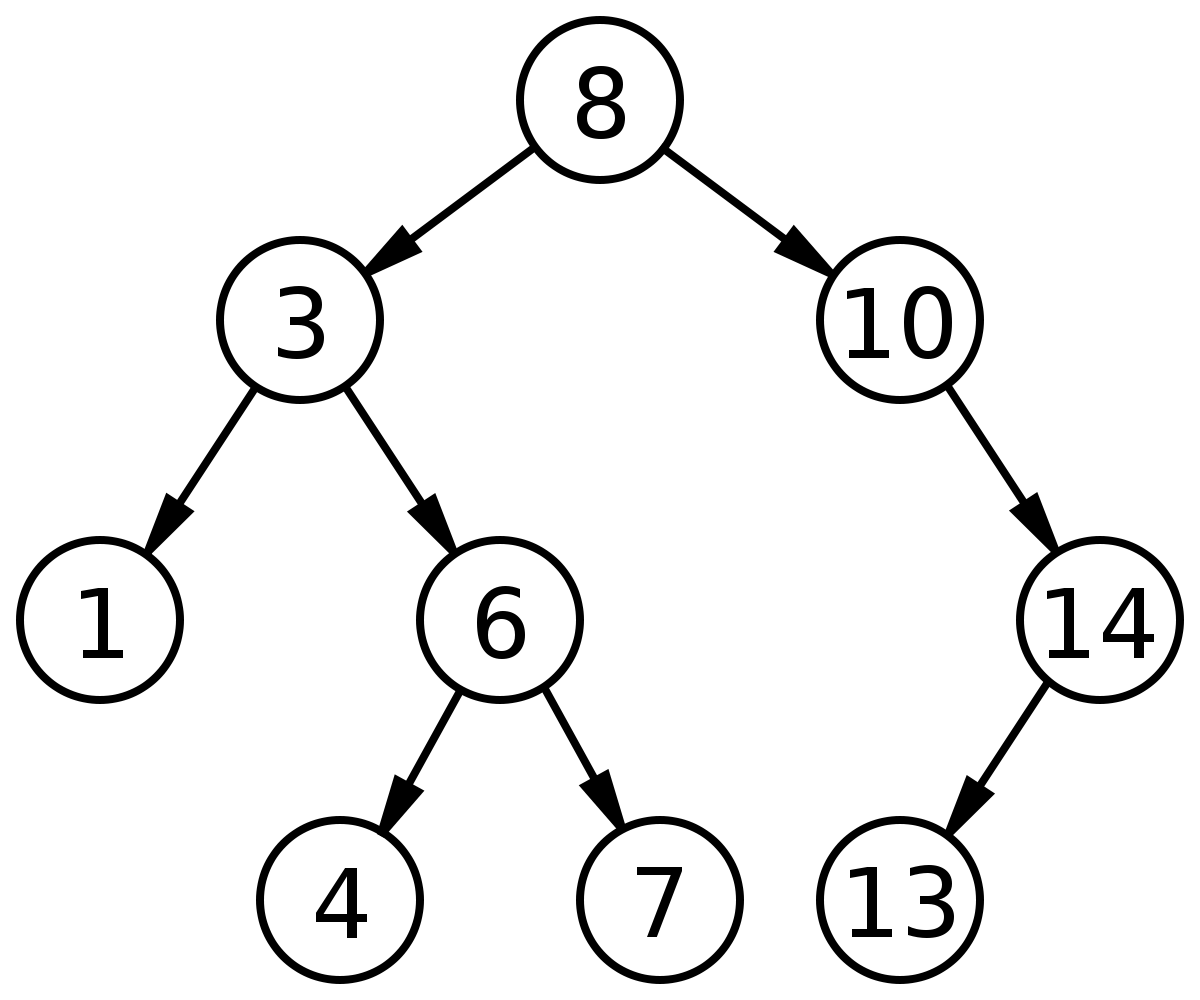
BST的框架如下:
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
}
2.二叉树例题
2.1 树的最大深度
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
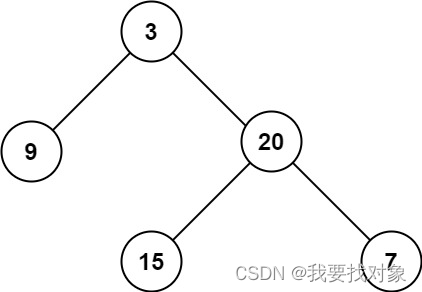
输入:root = [3,9,20,null,null,15,7]
输出:3
思路
这个解法应该很好理解,但为什么需要在前序位置增加 depth,在后序位置减小 depth?
因为前面说了,前序位置是进入一个节点的时候,后序位置是离开一个节点的时候,depth 记录当前递归到的节点深度,你把 traverse 理解成在二叉树上游走的一个指针,所以当然要这样维护。
至于对 res 的更新,你放到前中后序位置都可以,只要保证在进入节点之后,离开节点之前(即 depth 自增之后,自减之前)就行了。
代码
回溯法:
class Solution {
//记录最大深度
int res;
//记录遍历深度
int depth;
public int maxDepth(TreeNode root) {
traverse(root);
return res;
}
public void traverse(TreeNode root){
if(root == null){
return;
}
//刚进入这个结点 深度+1
depth++;
//遍历到叶子节点 更新res
if(root.left==null && root.right==null){
res = Math.max(res,depth);
}
traverse(root.left);
traverse(root.right);
//后序位置
depth--;
}
}
dp法:
// 定义:输入根节点,返回这棵二叉树的最大深度
int maxDepth(TreeNode root) {
if (root == null) {
return 0;
}
// 利用定义,计算左右子树的最大深度
int leftMax = maxDepth(root.left);
int rightMax = maxDepth(root.right);
// 整棵树的最大深度等于左右子树的最大深度取最大值,
// 然后再加上根节点自己
int res = Math.max(leftMax, rightMax) + 1;
return res;
}
2.2 二叉树的直径
给你一棵二叉树的根节点,返回该树的 直径 。
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
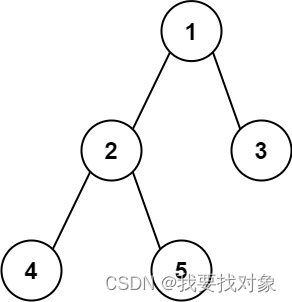
输入:root = [1,2,3,4,5]
输出:3
解释:3 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。
思路:
解决这题的关键在于,每一条二叉树的「直径」长度,就是一个节点的左右子树的最大深度之和。
这就出现了刚才探讨的情况,前序位置无法获取子树信息,所以只能让每个节点调用 maxDepth 函数去算子树的深度。
我们应该把计算「直径」的逻辑放在后序位置,准确说应该是放在 maxDepth 的后序位置,因为 maxDepth 的后序位置是知道左右子树的最大深度的。
代码
class Solution {
int res = 0;
public int diameterOfBinaryTree(TreeNode root) {
travarse(root);
return res;
}
public int travarse(TreeNode root){
if(root == null){
return 0;
}
int llength = travarse(root.left);
int rlength = travarse(root.right);
//后续位置,计算左右子树的最大深度
res = Math.max(llength+rlength,res);
//返回本结点到叶子节点的最大深度
return Math.max(llength,rlength)+1;
}
}
2.3 二叉树的翻转
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
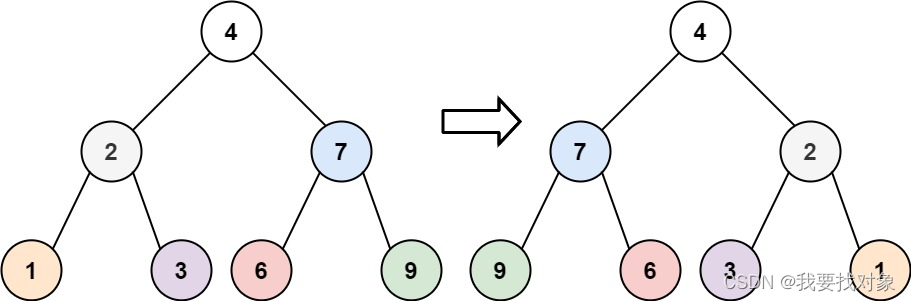
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
思路以及代码:
1、这题能不能用「遍历」的思维模式解决?
可以,我写一个 traverse 函数遍历每个节点,让每个节点的左右子节点颠倒过来就行了。
单独抽出一个节点,需要让它做什么?让它把自己的左右子节点交换一下。
需要在什么时候做?好像前中后序位置都可以。
代码
// 主函数
TreeNode invertTree(TreeNode root) {
// 遍历二叉树,交换每个节点的子节点
traverse(root);
return root;
}
// 二叉树遍历函数
void traverse(TreeNode root) {
if (root == null) {
return;
}
/**** 前序位置 ****/
// 每一个节点需要做的事就是交换它的左右子节点
TreeNode tmp = root.left;
root.left = root.right;
root.right = tmp;
// 遍历框架,去遍历左右子树的节点
traverse(root.left);
traverse(root.right);
}
2.这题能不能用「分解问题」的思维模式解决?
可以,我先这样定义:
// 定义:将以 root 为根的这棵二叉树翻转,返回翻转后的二叉树的根节点
TreeNode invertTree(TreeNode root);
然后思考,对于某一个二叉树节点 x 执行 invertTree(x),你能利用这个递归函数的定义做点啥?
我可以用 invertTree(x.left) 先把 x 的左子树翻转,再用 invertTree(x.right) 把 x 的右子树翻转,最后把 x 的左右子树交换,这恰好完成了以 x 为根的整棵二叉树的翻转,即完成了 invertTree(x) 的定义。
代码
// 定义:将以 root 为根的这棵二叉树翻转,返回翻转后的二叉树的根节点
TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
// 利用函数定义,先翻转左右子树
TreeNode left = invertTree(root.left);
TreeNode right = invertTree(root.right);
// 然后交换左右子节点
root.left = right;
root.right = left;
// 和定义逻辑自恰:以 root 为根的这棵二叉树已经被翻转,返回 root
return root;
}
2.4 填充每个节点的下一个右侧节点指针
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
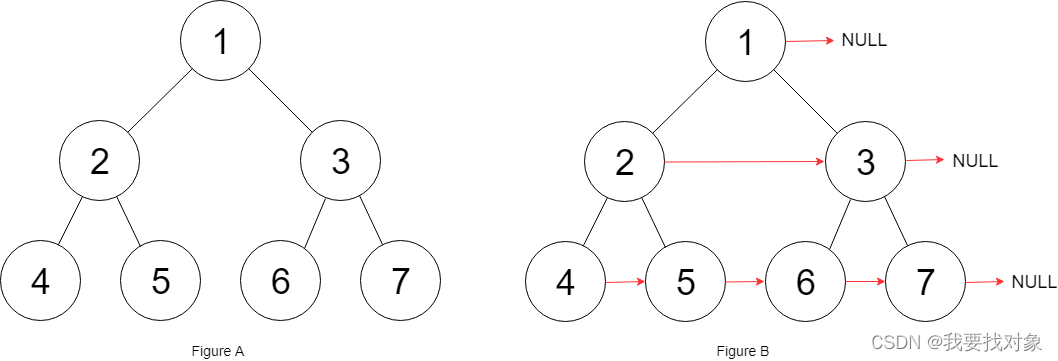
输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,‘#’ 标志着每一层的结束。
思路及代码
传统的 traverse 函数是遍历二叉树的所有节点,但现在我们想遍历的其实是两个相邻节点之间的「空隙」
所以我们可以在二叉树的基础上进行抽象,你把图中的每一个方框看做一个节点:
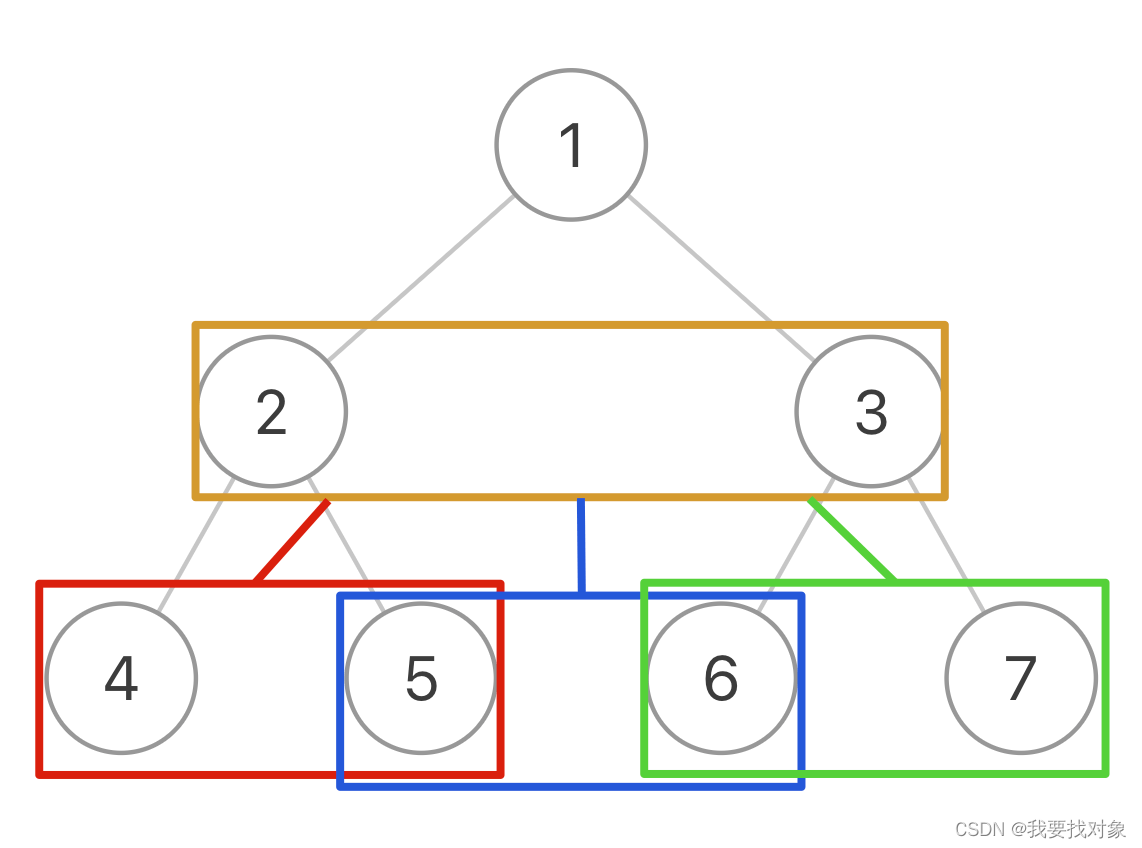
2.5 二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
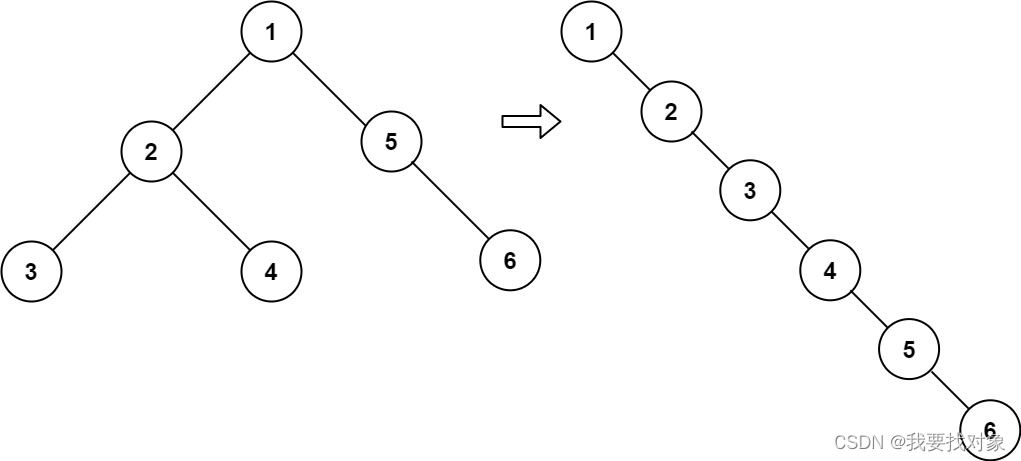
输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]
思路以及代码:
1、这题能不能用「遍历」的思维模式解决?
乍一看感觉是可以的:对整棵树进行前序遍历,一边遍历一边构造出一条「链表」就行了:
代码:
// 虚拟头节点,dummy.right 就是结果
TreeNode dummy = new TreeNode(-1);
// 用来构建链表的指针
TreeNode p = dummy;
void traverse(TreeNode root) {
if (root == null) {
return;
}
// 前序位置
p.right = new TreeNode(root.val);
p = p.right;
traverse(root.left);
traverse(root.right);
}
由于题目给的主函数为:
public void flatten(TreeNode root) {
}
因此,题目的要求是原地改变树,这种方法显然不行。
2、这题能不能用「分解问题」的思维模式解决?
对于一个节点 x,可以执行以下流程:
1、先利用 flatten(x.left) 和 flatten(x.right) 将 x 的左右子树拉平。
2、将 x 的右子树接到左子树下方,然后将整个左子树作为右子树。
代码:
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode root) {
// base case
if (root == null) return;
// 利用定义,把左右子树拉平
flatten(root.left);
flatten(root.right);
/**** 后序遍历位置 ****/
// 1、左右子树已经被拉平成一条链表
TreeNode left = root.left;
TreeNode right = root.right;
// 2、将左子树作为右子树
root.left = null;
root.right = left;
// 3、将原先的右子树接到当前右子树的末端
//ps:p是一个指针而不是一个新对象,p指向root,所以对p操作就是对树的结构操作
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
3 BST例题
3.1 验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
示例:
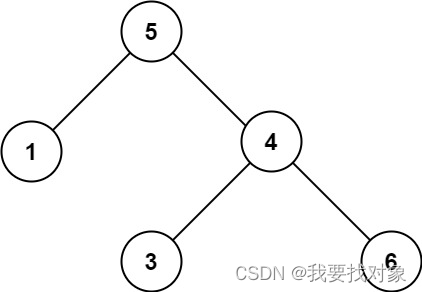
输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
思路以及代码:
刚看到这道题,我犯迷糊了,写的代码如下:
class Solution {
boolean res = true;
public boolean isValidBST(TreeNode root) {
travarse(root);
return res;
}
public void travarse(TreeNode root){
if(root == null){
return;
}
if(root.left != null){
if(root.left.val >= root.val){
res = false;
return;
}
}
if(root.right != null){
if(root.right.val <= root.val){
res = false;
return ;
}
}
travarse(root.left);
travarse(root.right);
}
}
但是这个算法出现了错误,BST 的每个节点应该要小于右边子树的所有节点,下面这个二叉树显然不是 BST,因为节点 10 的右子树中有一个节点 6,但是我们的算法会把它判定为合法 BST:
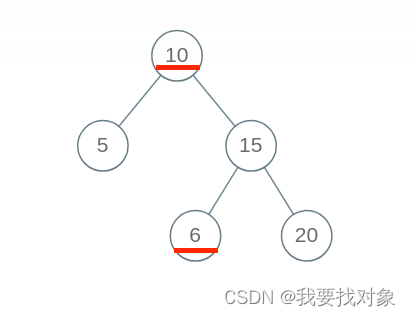
出现问题的原因在于,对于每一个节点 root,代码值检查了它的左右孩子节点是否符合左小右大的原则;但是根据 BST 的定义,root 的整个左子树都要小于 root.val,整个右子树都要大于 root.val。
问题是,对于某一个节点 root,他只能管得了自己的左右子节点,怎么把 root 的约束传递给左右子树呢?请看正确的代码:
class Solution {
public boolean isValidBST(TreeNode root) {
return travarse(root,null,null);
}
public boolean travarse(TreeNode root,TreeNode minNode,TreeNode maxNode){
if(root == null){
return true;
}
//左子树的最大值为根节点
//右子树的最小值为根节点
if (minNode != null && root.val <= minNode.val) return false;
if (maxNode != null && root.val >= maxNode.val) return false;
// 限定左子树的最大值是 root.val,右子树的最小值是 root.val
return travarse(root.left,minNode,root)&&travarse(root.right,root,maxNode);
}
}
这个代码的核心思想是分治,我只考虑一个节点,那么进入这个节点,我要保证这个节点的值比maxNode节点的值小且比minNode节点的值大,那么我就继续遍历左右节点,左节点应该满足都比root小,右节点应该满足都比root大。
3.2 二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
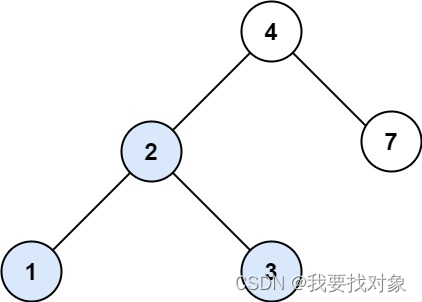
示例 1:
输入:root = [4,2,7,1,3], val = 2
输出:[2,1,3]
代码:
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if(root == null){
return null;
}
if(root.val < val){
return searchBST(root.right,val);
}
if(root.val > val){
return searchBST(root.left,val);
}
return root;
}
}
3.3 BST常用技能
3.3.1 在 BST 中插入一个数
对数据结构的操作无非遍历 + 访问,遍历就是「找」,访问就是「改」。具体到这个问题,插入一个数,就是先找到插入位置,然后进行插入操作。
一旦涉及「改」,就类似二叉树的构造问题,函数要返回 TreeNode 类型,并且要对递归调用的返回值进行接收。
代码:
TreeNode insertIntoBST(TreeNode root, int val) {
// 找到空位置插入新节点
if (root == null) return new TreeNode(val);
// if (root.val == val)
// BST 中一般不会插入已存在元素
if (root.val < val)
root.right = insertIntoBST(root.right, val);
if (root.val > val)
root.left = insertIntoBST(root.left, val);
return root;
}
3.3.2 在 BST 中删除一个数
这个问题稍微复杂,跟插入操作类似,先「找」再「改」,先把框架写出来再说
第一步:找
TreeNode deleteNode(TreeNode root, int key) {
if (root.val == key) {
// 找到啦,进行删除
} else if (root.val > key) {
// 去左子树找
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
// 去右子树找
root.right = deleteNode(root.right, key);
}
return root;
}
找到目标节点了,比方说是节点 A,如何删除这个节点,这是难点。因为删除节点的同时不能破坏 BST 的性质。有三种情况,用图片来说明。
情况 1:A 恰好是末端节点,两个子节点都为空,那么它可以当场去世了。
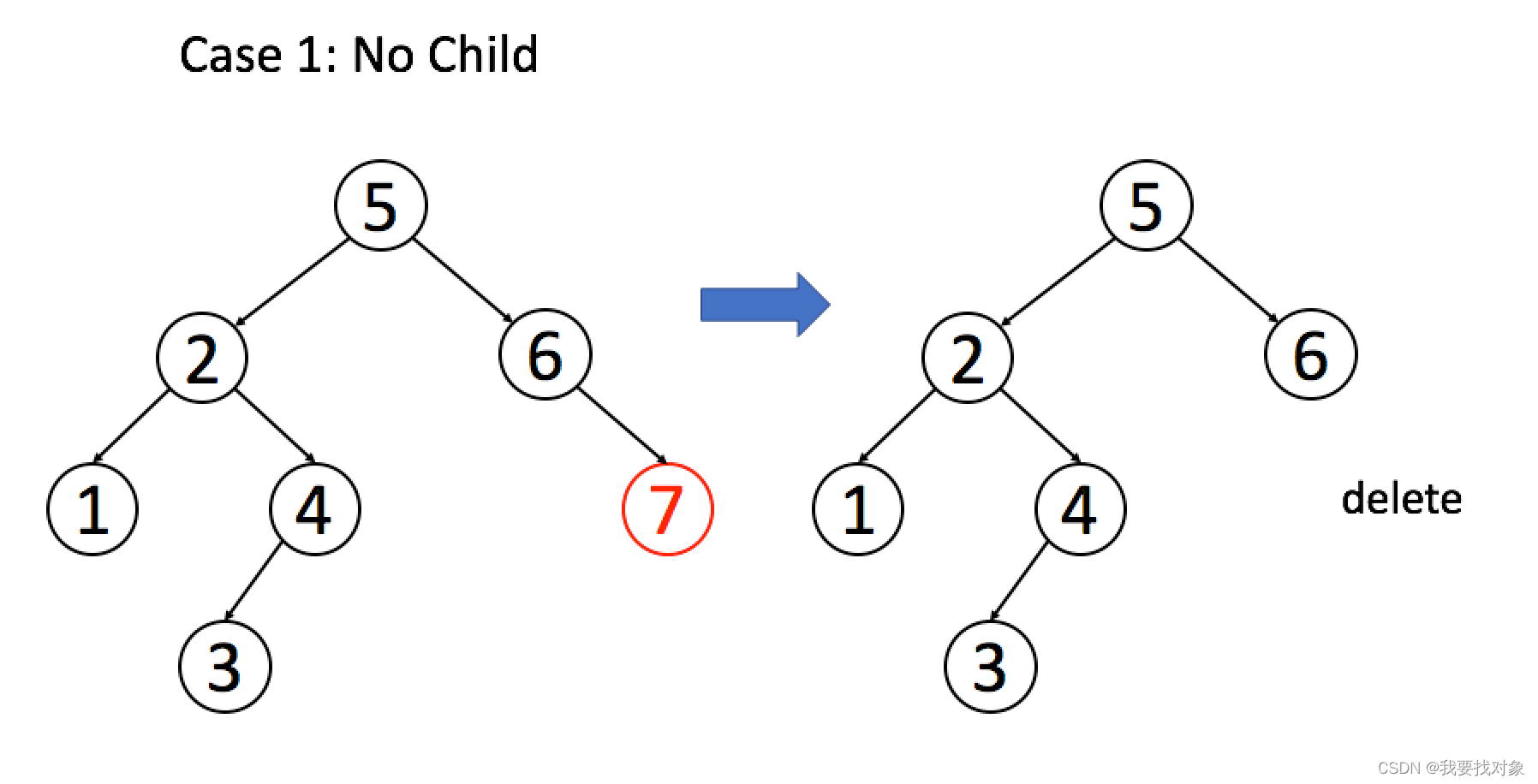
if (root.left == null && root.right == null)
return null;
情况 2:A 只有一个非空子节点,那么它要让这个孩子接替自己的位置。
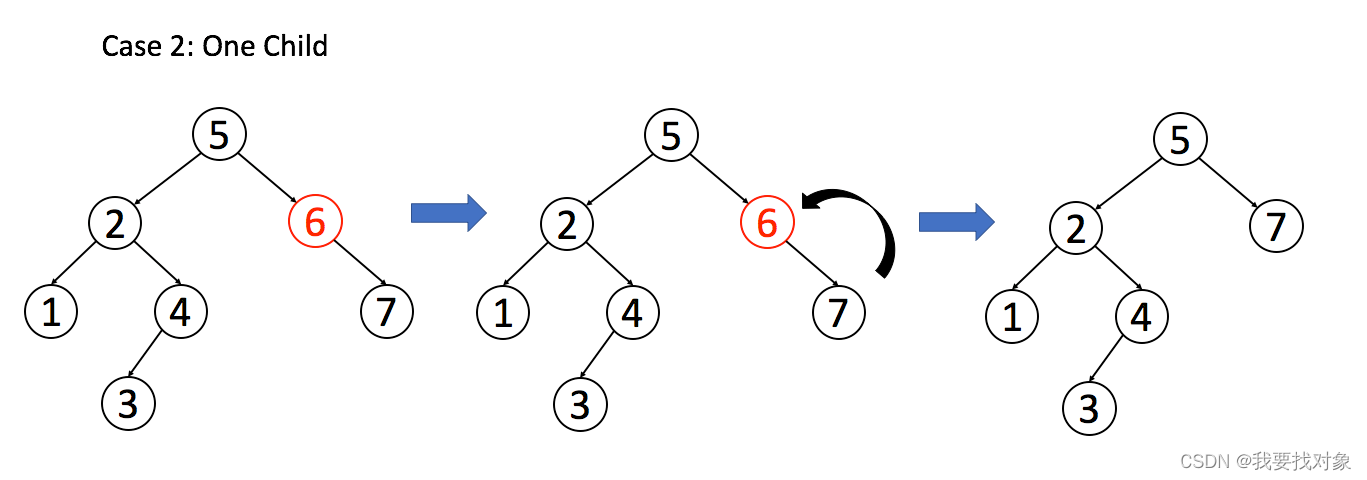
// 排除了情况 1 之后
if (root.left == null) return root.right;
if (root.right == null) return root.left;
情况 3:A 有两个子节点,麻烦了,为了不破坏 BST 的性质,A 必须找到左子树中最大的那个节点,或者右子树中最小的那个节点来接替自己。我们以第二种方式讲解。
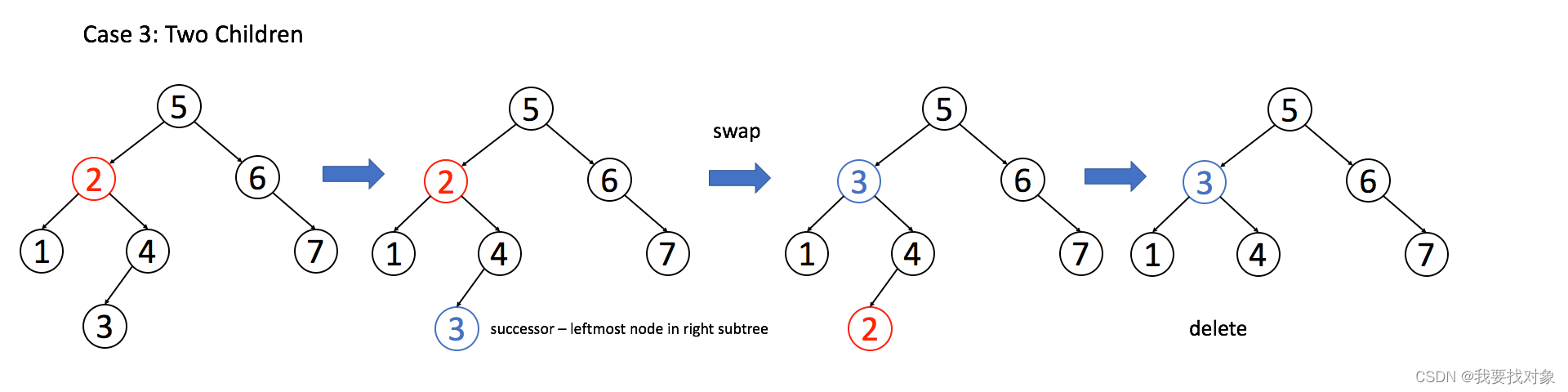
if (root.left != null && root.right != null) {
// 找到右子树的最小节点
TreeNode minNode = getMin(root.right);
// 把 root 改成 minNode
root.val = minNode.val;
// 转而去删除 minNode
root.right = deleteNode(root.right, minNode.val);
}
因此,完整代码如下:
TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val == key) {
// 这两个 if 把情况 1 和 2 都正确处理了
if (root.left == null) return root.right;
if (root.right == null) return root.left;
// 处理情况 3
// 获得右子树最小的节点
TreeNode minNode = getMin(root.right);
// 删除右子树最小的节点
root.right = deleteNode(root.right, minNode.val);
// 用右子树最小的节点替换 root 节点
minNode.left = root.left;
minNode.right = root.right;
root = minNode;
} else if (root.val > key) {
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
root.right = deleteNode(root.right, key);
}
return root;
}
TreeNode getMin(TreeNode node) {
// BST 最左边的就是最小的
while (node.left != null) node = node.left;
return node;
}
3.4 验证二叉搜索树的后序遍历序列
请实现一个函数来判断整数数组 postorder 是否为二叉搜索树的后序遍历结果。
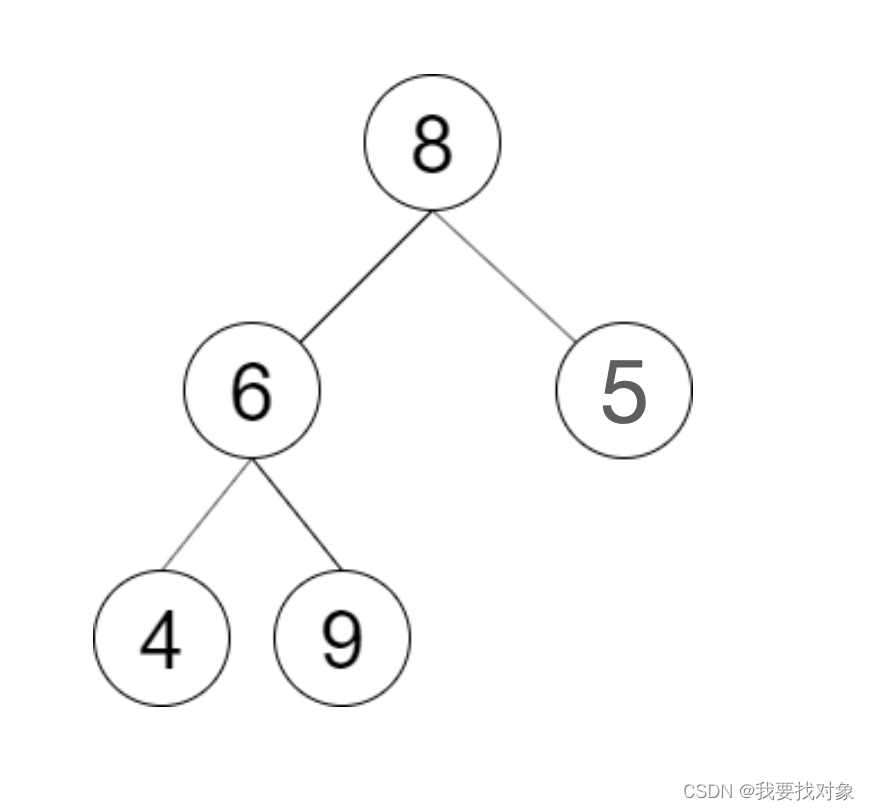
输入: postorder = [4,9,6,5,8]
输出: false
解释:从上图可以看出这不是一颗二叉搜索树
思路以及代码:
后序遍历结果的特点是:左边一部分是左子树,右边一部分是右子树,最后一个元素是根节点。
具体思路还是分治思想,先找到根节点,分别判断左右子树是否符合。
- 如何判断不是BST:
对于一个节点,如果寻找左子树后,再寻找右子树,还有除了左右子树的节点,说明不符合BST - 如何判断是BST:
假如按以下代码,遍历到最后节点的输入都是(i,i),也就是i==j,所以返回true,加入遍历到所有的叶子节点都是这样,那么就说明是BST
class Solution {
public boolean verifyPostorder(int[] postorder) {
return check(postorder, 0, postorder.length - 1);
}
// 定义:检查 postorder[i..j] 是否是一个合法的 BST
boolean check(int[] postorder, int i, int j) {
if (i >= j) {
return true;
}
// 根节点的值是后序遍历结果的最后一个元素
int root = postorder[j];
// postorder[i..left) 是左子树,应该都小于 root
int left = i;
while (left < j && postorder[left] < root) {
left++;
}
// postorder[left..j) 是右子树,应该都大于 root
int right = left;
while (right < j && postorder[right] > root) {
right++;
}
if (right != j) {
return false;
}
// 递归检查左子树 [i..left) 和右子树 [left..j) 也符合 BST 的性质
return check(postorder, i, left - 1) && check(postorder, left, j - 1);
}
}























![[生活][杂项] 上班党的注意事项](https://img-blog.csdnimg.cn/direct/f5e4e16630c245d3b4e36695b0e04a9d.jpeg)