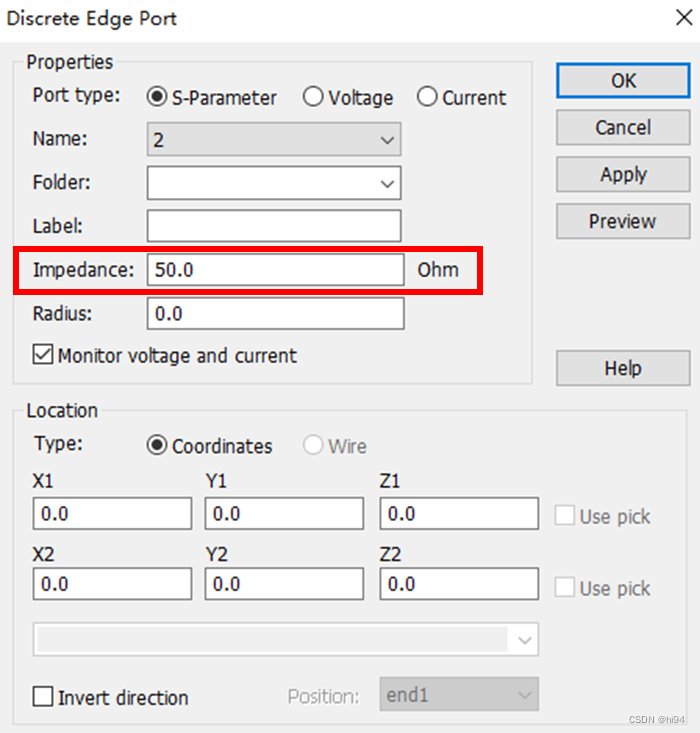
点开其中一个链接, http://desk.zol.com.cn/dongman/huoyingrenzhe/(前面为浏览器自动补全,在代码里需要自己补全)
可以看到图片的下载地址以及打开本图集下一张图片的链接
了解完网站的图片构造后动手写代码,我们筛选出图集的链接后,通过图集的链接找到第一张图片下载地址和第二张图片的链接,通过第二张的链接找到第二张的下载地址和第三张的链接,循环下去,直到本图集到底,接着开始第二个图集,直到所有图集下载完毕,代码如下,为了方便循环,我们集成下载图片功能为download函数,解析图片网址功能为parses_picture:
from bs4 import BeautifulSoup
import requests
def download(img_url, headers, n):
req = requests.get(img_url, headers=headers)
name = '%s' % n + '=' + img_url[-15:]
path = r'C:\Users\asus\Desktop\火影壁纸1'
file_name = path + '\\' + name
f = open(file_name, 'wb')
f.write(req.content)
f.close
def parses_picture(url, headers, n):
url = r'http://desk.zol.com.cn/' + url
img_req = requests.get(url, headers=headers)
img_req.encoding = 'gb2312'
html = img_req.text
bf = BeautifulSoup(html, 'lxml')
try:
img_url = bf.find('div', class_='photo').find('img').get('src')
download(img_url, headers, n)
url1 = bf.find('div', id='photo-next').a.get('href')
parses_picture(url1, headers, n)
except:
print(u'第%s图片集到头了' % n)
if __name__ == '__main__':
url = 'http://desk.zol.com.cn/dongman/huoyingrenzhe/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}
req = requests.get(url=url, headers=headers)
req = requests.get(url=url, headers=headers)
req.encoding = 'gb2312'
html = req.text
bf = BeautifulSoup(html, 'lxml')
targets_url = bf.find_all('li', class_='photo-list-padding')
n = 1
for each in targets_url:
url = each.a.get('href')
parses_picture(url, headers, n)
n = n + 1如果要抓取百度上面搜索关键词为Jecvay Notes的网页, 则代码如下
import urllib
import urllib.request
data={}
data['word']='Jecvay Notes'
url_values=urllib.parse.urlencode(data)
url="http://www.baidu.com/s?"
full_url=url+url_values
data=urllib.request.urlopen(full_url).read()
data=data.decode('UTF-8')
print(data)