先总结一句unicode是一个标准,与具体的编码形式无关。utf-8, utf-16, utf-32都是具体的编码形式。 因此本文作为两部分叙述,首先是标准,后面是编码形式
1 unicode标准
unicode标准定义了一系列的code points 包含的范围是 [ 0 , 17 ∗ 2 16 ) [0, 17*2^{16}) [0,17∗216),用16进制表示为[0, 0x10FFFF],其中并不是所有的code points都是有效的,有一些被保留出来作为他用;还有一些目前未定义,留作后面定义(unicode标准不断在更新,新的符号不断被增加进来)。
unicode将所有范围分作了17个平面,分别是平面0~平面16,每个平面2^16个code points。
第0个平面是[0, 0xFFFF]
第1个平面[0x1_0000, 0x1_FFFF]
…
第16个平面[0x10_0000,0x10_FFFF]
其中最重要的是第0平面,第0空间范围其实是2个字节。
第0平面的[0xD800~0xDFFF],或者[11011000_00000000, 11011111_11111111]
共有2024个编码,叫做代理区。这部分区间都是没有编码的,是作为代理空间使用,后面也不会往这个区间定义字符。至于什么是代理空间? 后面编码UTF-16时会叙述。
所有unicode字符定义,见https://www.unicode.org/charts/
2.1编码 UTF-32
通过上面unicode标准,容易发现所有的code points其实不会超过3个字节,,因此理论上用3个字节,可以完全编码所有的code points。但是这个3字节在计算机系统下不太美妙,在运算时可能需要额外的操作。就像所有的数字类型有单字节,双字节,4字节,8字节,但却没有见过3字节,5字节一样。因此干脆就用4个字节表示所有的code points,这就是UTF-32。
2.2 编码 UTF-16
UTF-16其实并不是用2个字节表示所有的code points,而是说小于0XFFFF的code points用两个字节表示,而大于0XFFFF的code points,用4个字节表示。这其实是一种可变长度的编码形式。对于这种编码,需要遍历所有的字符才能知道字符串长度。
那问题来了,怎么样才能知道哪些字符是2字节,哪些字符是4字节呢?这就可以用到刚刚的unicode标准中0平面的代理空间。因此代理空间范围不表示code points,如果一个双字节在代理空间,就表示这个双字节要和下一个双字节组成4字节,表示一个大于0xFFFF的code points。
如果双字节开头等于110111,表示这是32位编码的低16位,该16bits其余的10bits,记为 x l o w x_{low} xlow
如果双字节开头等于110110,表示这是32位编码的高16位,该16bits其余的10bits,记为 x h i g h x_{high} xhigh
那么这个4字节数表示的coee points值为
codepoints= x h i g h x_{high} xhigh * (1 << 10) + x l o w x_{low} xlow+0x10000
通过这个公式,也可知道utf-16能编码的最大的code poins是0x10FFFF
下面通过一个例子,验证上述计算方法,与Python计算的UTF-16编码是否一致
import struct
cp = 0x1f600
b1 = struct.pack(">I", cp)
s1 = b1.decode("utf-32_be")
print(s1)
u1 = s1.encode("utf-16_be")
print("utf-16 encode: ", ["%02x" % x for x in u1])
r1 = cp - 0x10000
b1 = r1 % (1 << 10)
b2 = r1 // (1 << 10)
bs1 = b1 + 0b110111_00_0000_0000
bs2 = b2 + 0b110110_00_0000_0000
bs = struct.pack(">HH", bs2, bs1)
print("my utf-16 encode:", ["%02x" % x for x in bs])
结果如下
😀
utf-16 encode: [‘d8’, ‘3d’, ‘de’, ‘00’]
my utf-16 encode: [‘d8’, ‘3d’, ‘de’, ‘00’]
2.3 编码UTF-8
UTF-8编码采用了类似UTF-16的方法,规则如下
(截取的wiki上的UTF-8词条)
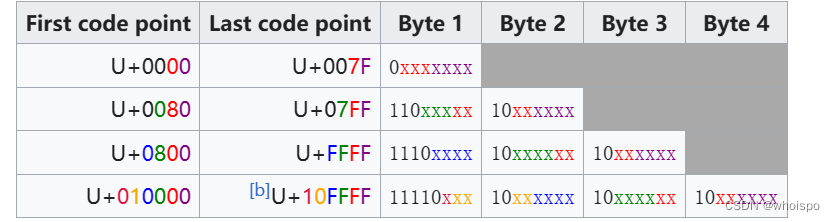
注意UTF-8在计算方法上 与UTF-16不一样的地方。也就是UTF-8的有效位上,并不全用来进行编码。比如两字节的UTF-8的有效位,有11位,但是从0x0000~0x007F并不进行编码(我也不知道为什么就这样浪费了)。
下面一个简单的例子,用来验证从UTF-8编码中获取code points值
import struct
test_cp = 0x1F600
t32 = struct.pack(">I", test_cp)
test_cp_s = t32.decode('utf-32_be')
print(test_cp_s)
u8 = test_cp_s.encode("utf-8")
# print([x for x in u8])
v4 = u8[0] % (1 << 3)
v3 = u8[1] % (1 << 6)
v2 = u8[2] % (1 << 6)
v1 = u8[3] % (1 << 6)
v = v4 * (1 < 18) + v3 * (1 << 12) + v2 * (1 << 6) + v1
print(hex(v))
print(test_cp)
结果显示两者一致
下面一个例子,验证如果将code points小于0x80的字符,编码到两字节UTF-8中,这样的2字节解析成unicode字符时,会出错。
import struct
cps = [0x62, 0xb1] # 'a', '±'
for cp in cps:
try:
b1 = struct.pack(">I", cp)
s1 = b1.decode("utf-32_be")
print("decode character: ", s1)
r1 = cp
v1 = r1 % (1 << 6)
r1 = r1 // (1 << 6)
v2 = r1 % (1 << 5)
vb2 = 0b110 * (1 << 5) + v2
vb1 = 0b10 * (1 << 6) + v1
vb = bytearray([vb2, vb1])
s2 = vb.decode('utf-8')
print("my decode result: ", s2)
except UnicodeDecodeError as e:
print(e)
结果是:
decode character: b
‘utf-8’ codec can’t decode byte 0xc1 in position 0: invalid start byte
decode character: ±
my decode result: ±




















![[转载] 在IIS上启用https的免费ssl证书使用教程](https://img-blog.csdnimg.cn/direct/7db86ec5f78844e4a164d7edd1bda0f0.png)
![【Hadoop】- YARN架构[7]](https://img-blog.csdnimg.cn/direct/b7d090c5cc6e45cda6ca900fb418c324.png)