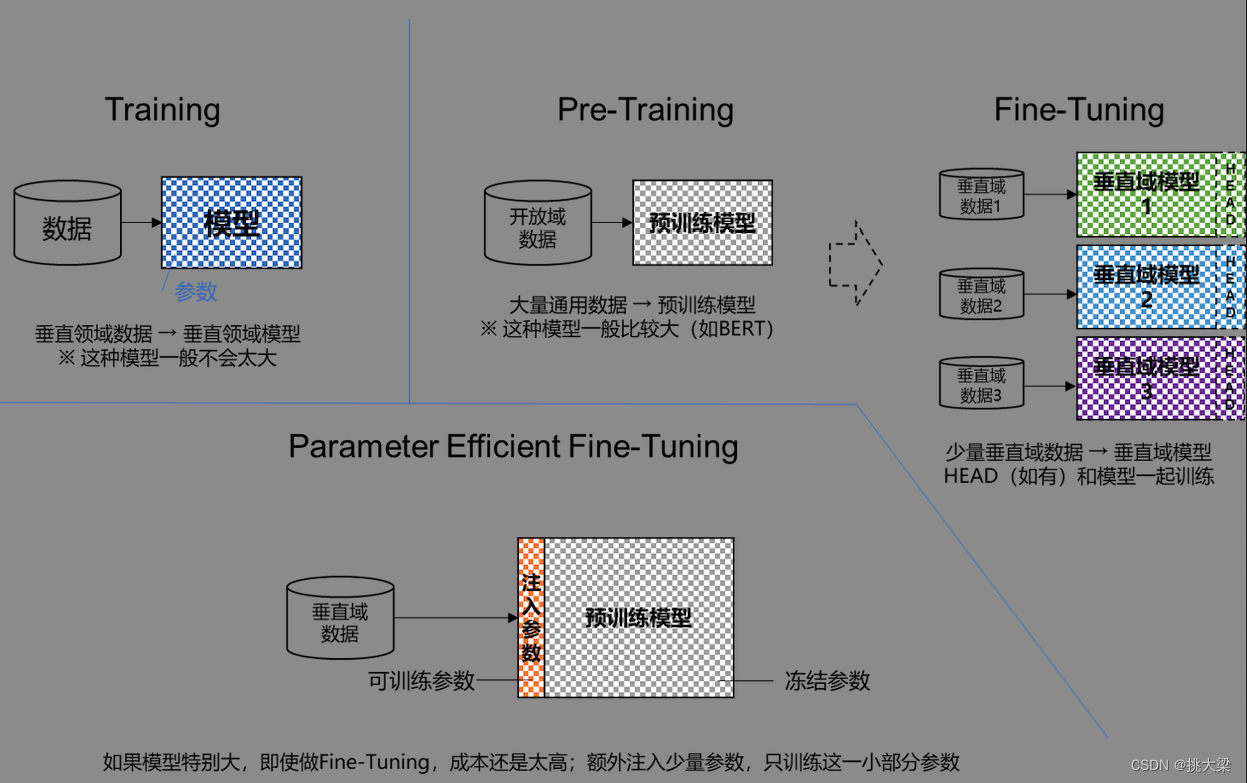
1. 训练/预训练/微调/轻量化微调
训练: 在给定的数据集上进行全量的训练
预训练:第三方已经在较大的、通用的数据集上进行了预训练
微调:在预训练的基础上,使用自己的特定数据集上进行训练,对训练参数进行微调
轻量化微调:在训练资源有限的条件下,对模型少量参数进行微调。
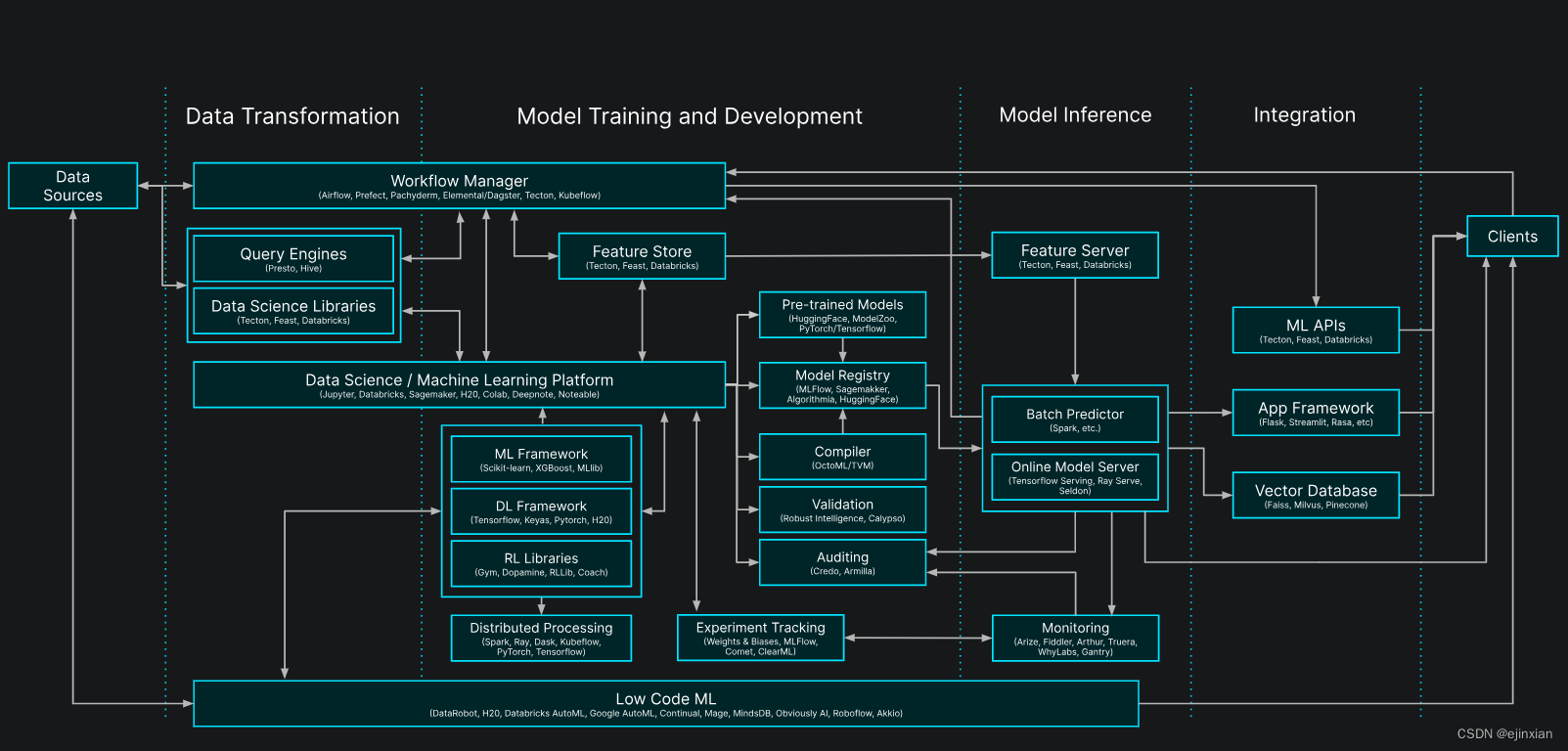
2. transformer结构
Transformer 是组成 LLM 的基本单元。
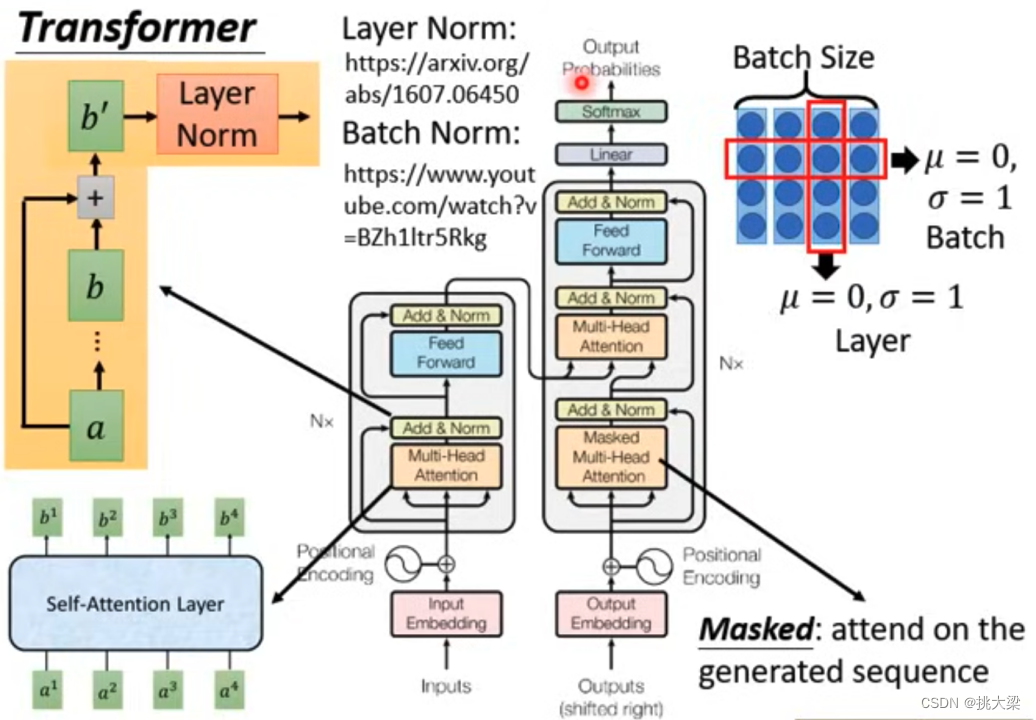
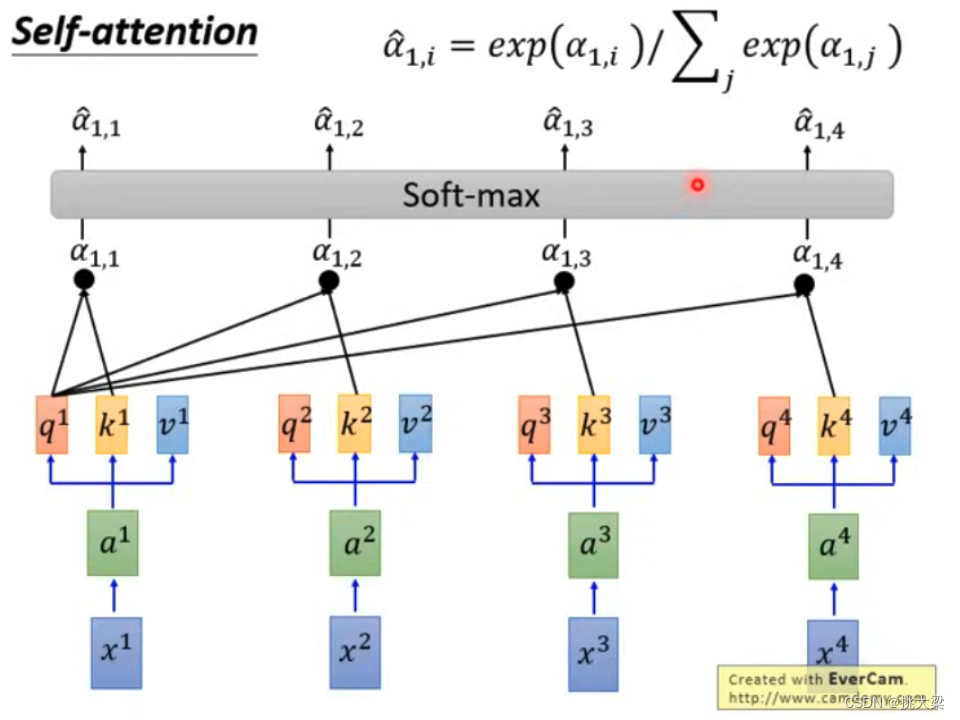
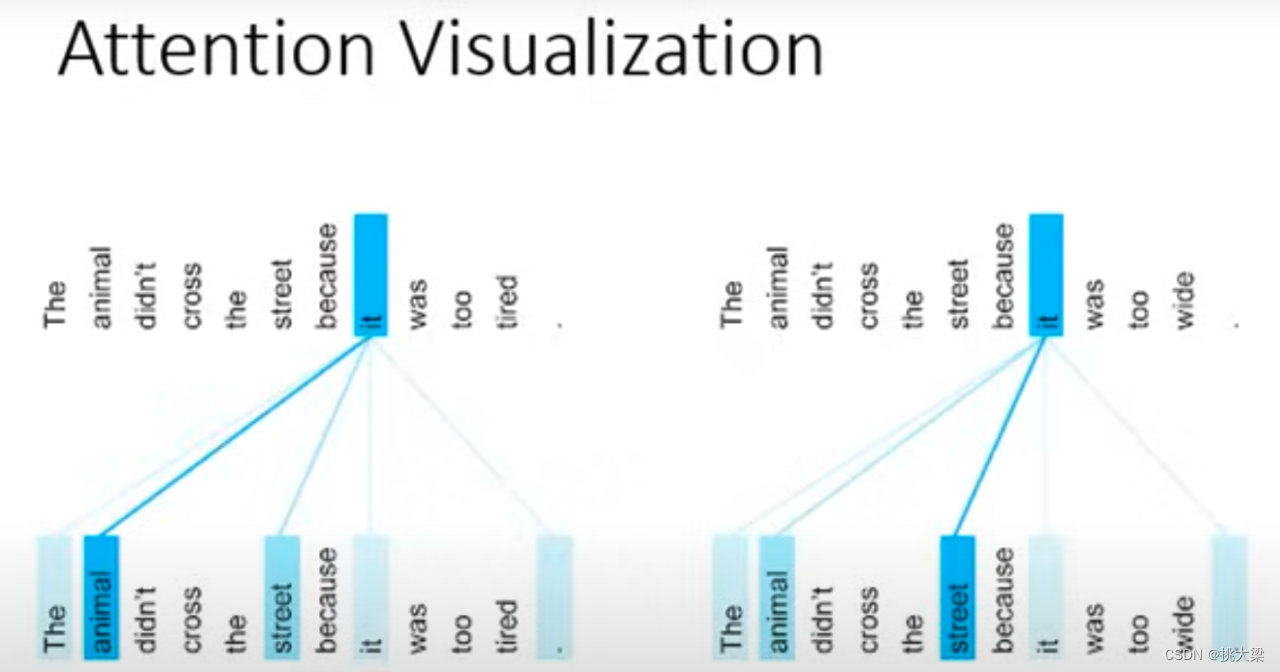
Self-Attention 的计算
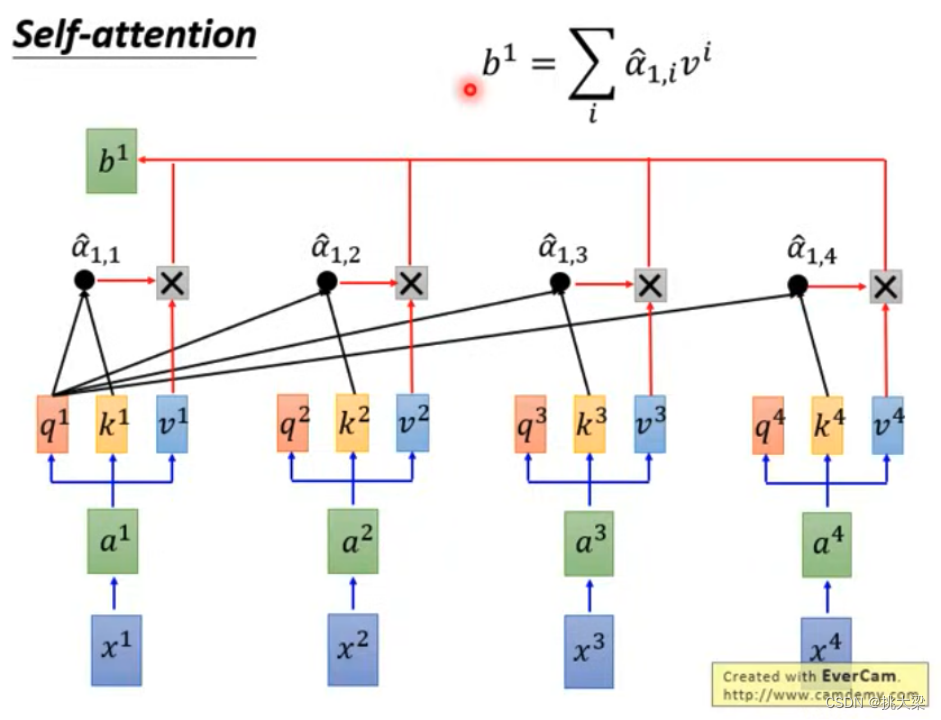
自注意力机制演示
3. 轻量化微调

3.1. Prompt Tuning
- 在输入序列前,额外加入一组伪Embedding向量
- 只训练这组伪Embedding,从而达到参数微调的效果

3.2. P-Tuning
- 用一个生成器生成上述伪Embedding向量
- 只训练这组伪Embedding

3.3. Prefix-Tuning
- 伪造前面的Hidden Sates
- 只训练伪造的这个Prefix

3.4. LoRA
- 在Transformer的参数矩阵上加一个低秩矩阵(A x B)
- 只训AB
- 理论上可以把上述方法应用于Transformer中的任意参数矩阵,包括Embedding矩阵
- 通常应用于Query, Value两个参数矩阵

3.5. QLoRA
什么是模型量化


QLoRA 引入了许多创新来在不牺牲性能的情况下节省显存:
- 4位 NormalFloat(NF4),一种对于正态分布权重而言信息理论上最优的新数据类型
- 双重量化,通过量化量化常数来减少平均内存占用
- 分页优化器,用于管理内存峰值
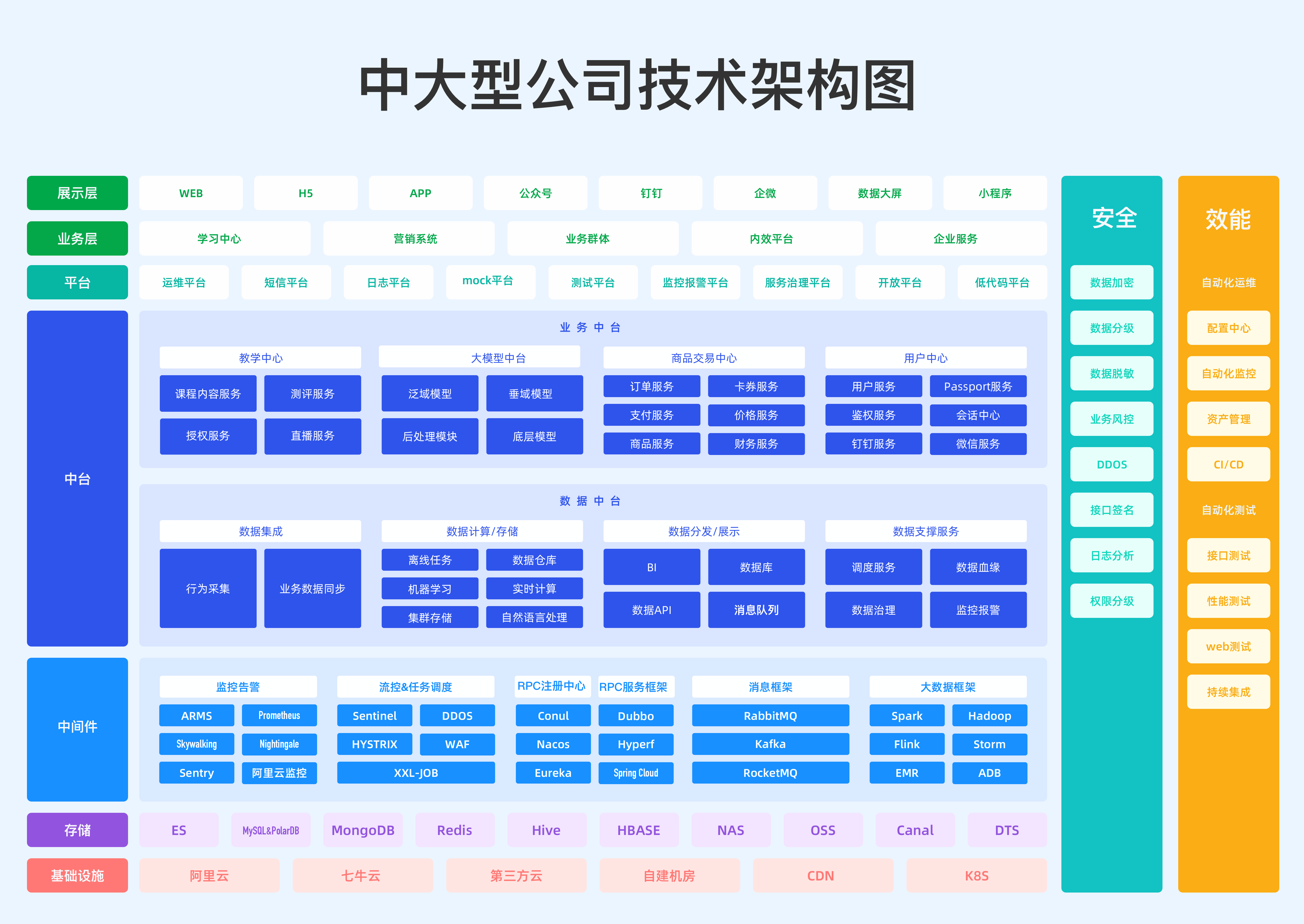
4. 多轮会话的拼接
4.1. ChatGLM2拼接方式
user: 你好
assistant: 有什么可以帮您
user: 你喜欢什么颜色
assistant: 喜欢黑色
user: 为什么
assistant: 因为黑色幽默
按照轮次,上述对话将被拆分成3个单独的样本
- 每个样本以之前的历史为输入
- 当前轮的回复为输出
样本1
输入:
[Round 0]\n
问: 你好\n
答:
输出:
有什么可以帮您
样本2
输入:
[Round 0]\n
问: 你好\n
答: 有什么可以帮您\n
[Round 1]\n
问: 你喜欢什么颜色\n
答:
输出:
喜欢黑色
样本3
输入:
[Round 0]\n
问: 你好\n
答: 有什么可以帮您\n
[Round 1]\n
问: 你喜欢什么颜色\n
答: 喜欢黑色\n
[Round 2]\n
问: 为什么\n
答:
输出:
因为黑色幽默
4.2. ChatGLM3拼接方式
因为CausalLM是一直从左往右预测的,我们可以直接在多轮对话中标识出多段输出。具体如下:
角色special token用于标识分隔出多轮对话,同时也可以防范注入攻击
- <|system|> #系统提示词,指明模型可使用的工具等信息
- <|user|> #用户输入,用户的指令
- <|assistant|> #模型回复,或模型思考要做的事情
- <|observation|> #工具调用、代码执行结果
注意:这里<|role|>这种是一个token,而不是一串文本,所以不能通过tokenizer.encode('<role>')来得到
角色后跟随的是metadata,对于function calling来说,metadata是调用的函数和相应参数;对其他角色的对话,metadata为空
- 多轮对话finetune时根据角色添加loss_mask
- 在一遍计算中为多轮回复计算loss
<|system|>Answer the following questions as best as you can.
You have access to the following tools:\n[…]
<|user|>\n北京的天气怎么样?
<|assistant|>\n我需要调用天气预报工具来获取北京的天气信息。
<|assistant|>get_weather\n```python\ntool_call(location=“北京”)```
<|observation|>\n{“temperature_c”: 12, “description”: “haze”}
<|assistant|>\n根据天气工具的信息,北京的天气是:温度 12 摄氏度,有雾。
<|user|>\n这样的天气适合外出活动吗?
<|assistant|>\n北京现在有雾,气温较低,建议您考虑一下是否适合外出进行锻炼
<|user|>
高亮部分为需要计算loss的token。注意<|assistant|>后的内容和角色token都需要算loss。
4.3. ChatGLM3的数据加载
实际应用中,我们只需要将上述数据,与ChatGLM 3的标准数据格式对齐,就可调用其原生的数据加载器,自动完成数据拼接
{
"tools": [
"search_hotels: 根据筛选条件查询酒店的函数\nparameters: {\"name\":\"酒店名称\",\"price_range_lower\":\"价格下限\",\"price_range_upper\":\"价格上限\",\"rating_range_lower\":\"评分下限\",\"rating_range_upper\":\"评分上限\",\"facilities\": \"酒店提供的设施\"}\noutput: 酒店信息dict组成的list"
],
"conversations": [
{
"role": "user",
"content": "请帮我找一家最低价格是300-400元,提供无烟房的经济型酒店。"
},
{
"role": "assistant",
"content": "我需要使用search_hotels工具来查询酒店"
},
{
"role": "tool",
"name": "search_hotels",
"parameters": {
"facilities": [
"无烟房"
],
"price_range_lower": 300,
"price_range_upper": 400,
"type": "经济型"
},
"observation": [
{
"name": "飘HOME连锁酒店(北京王府井店)",
"type": "经济型",
"address": "北京东城区东安门大街43号",
"subway": "灯市口地铁站A口",
"phone": "010-57305888",
"facilities": [
"酒店各处提供wifi",
"宽带上网",
"吹风机",
"24小时热水",
"暖气",
"无烟房",
"早餐服务",
"行李寄存",
"叫醒服务"
],
"price": 303.0,
"rating": 4.3,
"hotel_id": 152
}
]
},
{
"role": "assistant",
"content": "推荐您去飘HOME连锁酒店(北京王府井店)。"
}
]
}
重点
- 在tools字段中描述function和parameters的定义
- 在conversations字段中组织对话轮次
- 以user和assistant标识出用户输入与系统回复
- 在function call的角色以tool标识,并填入function名称和参数
- 以observation标识出function的返回结果
![[算法前沿]--059-<span style='color:red;'>大</span>语言<span style='color:red;'>模型</span><span style='color:red;'>Fine</span>-<span style='color:red;'>tuning</span>踩坑经验<span style='color:red;'>之</span>谈](https://img-blog.csdnimg.cn/direct/5123885ed326474993eb479f79e9c65c.png)