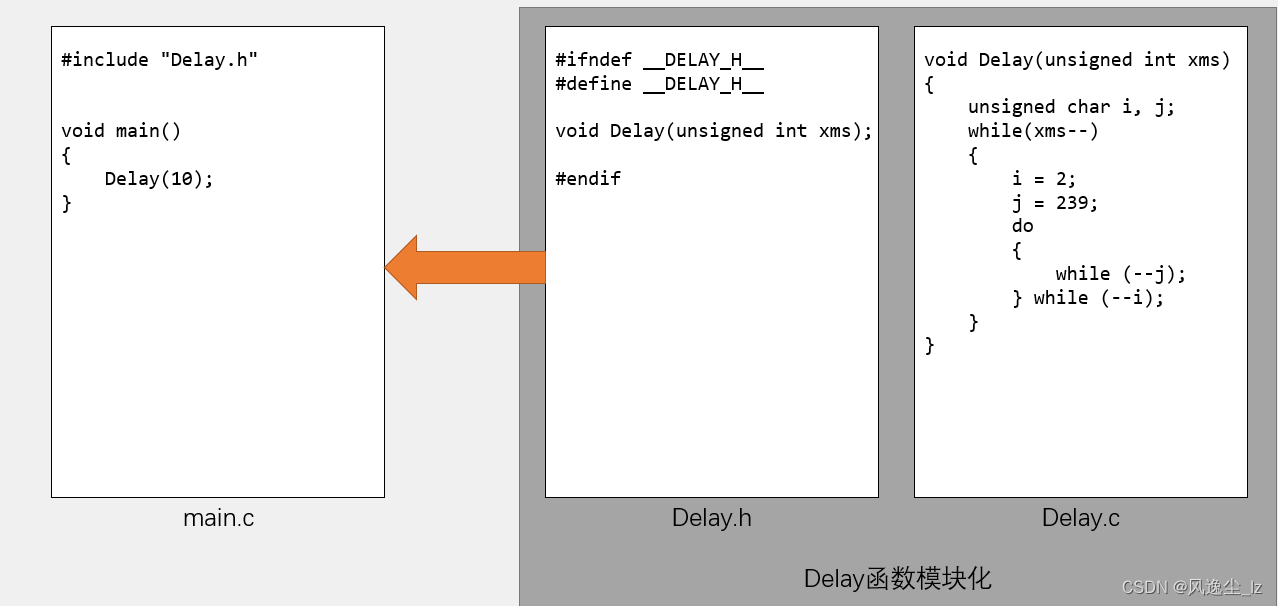
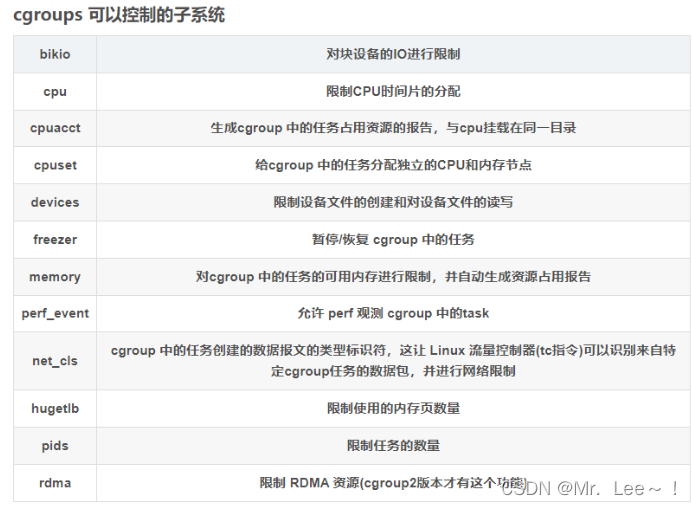
文心一言
在深度学习中,过拟合(Overfitting)是指模型在训练数据上表现很好,但在测试数据或新数据上表现较差的现象。换句话说,过拟合的模型对训练数据中的噪声或随机波动也进行了学习,导致其在面对新数据时泛化能力较差。
过拟合通常发生在以下情况:
- 模型复杂度过高:当模型的复杂度远高于数据的复杂度时,模型可能会“记住”训练数据中的每一个细节,包括噪声,而不是学习数据的内在规律和模式。
- 训练数据量不足:如果训练数据量不足以覆盖所有可能的情况,模型可能会过度拟合训练数据中的特定样本,而无法泛化到新的数据。
为了减轻过拟合问题,可以采取以下策略:
- 简化模型:降低模型的复杂度,使其与数据的复杂度相匹配。
- 增加数据量:通过获取更多的训练数据或进行数据增强(如旋转、缩放等)来丰富数据集。
- 正则化:通过引入正则化项(如L1、L2正则化)来约束模型的复杂度,防止其过度拟合训练数据。
- 早停法(Early Stopping):在验证误差开始上升时停止训练,避免模型继续拟合训练数据中的噪声。
- 集成方法:如Bagging和Boosting等,通过结合多个模型的预测结果来提高模型的泛化能力。
总之,过拟合是深度学习中需要关注的问题之一,通过合理调整模型复杂度、增加数据量以及采用正则化等方法,可以有效地减轻过拟合问题,提高模型的泛化能力
智谱清言
在深度学习中,过拟合(Overfitting)是指模型对训练数据学得“太好”,以至于它对训练数据中的噪声和异常值过于敏感,从而导致在新的、未见过的数据上表现不佳。简而言之,过拟合的模型过于复杂,它学习到了训练数据中的细节和特异性,而没有从中抽象出足够泛化的规律,这导致其泛化能力下降。
深度学习模型通常通过大量的参数和层次来捕捉数据中的复杂模式。当模型复杂度超过了数据中存在的实际规律和模式的数量时,模型就有可能捕捉到的是训练数据中的随机噪声,而不是潜在的数据分布的真实结构。因此,在训练过程中,如果模型对于训练集的误差非常小,但泛化到新的数据集上时误差增大,就表明模型可能出现了过拟合。
为了解决过拟合问题,研究者们采取了多种方法,如:
- 数据增强:通过增加训练数据的多样性来提高模型的泛化能力。
- 正则化:在损失函数中增加正则项,比如L1正则化或L2正则化,以限制模型复杂度。
- 交叉验证:使用交叉验证来评估模型的泛化能力,并调整模型参数。
- 简化模型:减少模型参数数量或层数,使模型更简单。
- 早停法(Early Stopping):在训练过程中,当验证集上的性能不再提高时停止训练,以防止模型在训练集上过度训练。
防止过拟合的关键在于找到模型复杂度和数据复杂度之间的平衡点,使模型能够足够复杂以捕捉数据的本质特征,同时又不至于过于复杂以至于捕获了噪声和无关的变量。
豆包
在深度学习中,过拟合是指模型在训练数据上表现得非常好,但在新的数据上表现不佳的情况。
当模型过于复杂或训练时间过长时,它可能开始学习训练数据中的噪声和随机特征,而不是真正的模式和规律。这导致模型对训练数据过度拟合,无法泛化到新的数据。
过拟合的主要表现包括:
- 高训练准确率:模型在训练数据上的准确率非常高。
- 低测试准确率:但在新的数据上准确率较低。
- 对新数据的不适应性:无法很好地处理未曾见过的数据。
为了避免过拟合,可以采取以下措施:
- 增加数据量:提供更多的训练数据。
- 正则化:如 L1、L2 正则化。
- Dropout:在训练过程中随机禁用神经元。
- 早停法:根据验证集准确率提前停止训练。
这些方法有助于减少过拟合的风险,提高模型的泛化能力。
讯飞星火
在深度学习中,过拟合指的是模型在训练数据上表现很好,但在新的、未见过的数据上表现较差的现象。
过拟合通常发生在模型过于复杂,以至于它学习了训练数据中的噪声和细节,而不是数据的潜在规律。这导致模型无法很好地泛化到新数据上。具体来说,过拟合的表现包括:
- 模型复杂度过高:如果模型的复杂度超过了数据的复杂度,模型可能会学习到数据中的随机波动而不是真正的信号。
- 数据量有限:在有限的数据上训练复杂模型容易导致过拟合,因为模型可能会过度关注训练集中的个别样本。
- 噪声存在:如果训练数据中含有噪声,模型可能会错误地将噪声当作信号来学习。
- 训练集和测试集分布不一致:如果两者之间的分布有偏差,模型可能在训练集上表现良好,但在测试集上表现不佳。
解决过拟合的方法包括:
- 增加数据量:通过获取更多的训练数据,可以减少模型对个别样本的学习,提高泛化能力。
- 简化模型:选择合适复杂度的模型,避免模型过于复杂而学习到不必要的细节。
- 正则化:通过添加正则化项来惩罚模型的复杂度,促使模型学习更一般的特征。
- Dropout:在训练过程中随机丢弃一些神经元,强迫模型不过分依赖于任何一个特征。
- 早停(Early Stopping):在验证集的性能不再提升时停止训练,以防止模型过度学习训练数据。
- 数据增强:通过对训练数据进行变换(如旋转、缩放等),生成更多的训练样本,增加数据的多样性。
- 集成学习:使用多个模型的预测结果的组合,可以提高泛化能力。
总之,过拟合是深度学习中的一个常见问题,但通过上述方法可以有效地缓解这一问题,提高模型在新数据上的表现。