文章目录
分析系统现状不足
现状:目前的异步是通过本地的线程池实现的
1) 无法集中限制(分布式),只能单机限制
解决方案:在一个集中的地方去管理下发任务
2) 任务由于是放在内存中执行的,可能会丢失
解决方案:把任务放在一个可以持久化存储的硬盘
3)优化:如果你的系统功能越来越多,长耗时任务越来越多,系统会越来越复杂
服务拆分(应用解耦):可以把长耗时,消耗很多的任务把它单独抽成一个程序,不要影响主业务
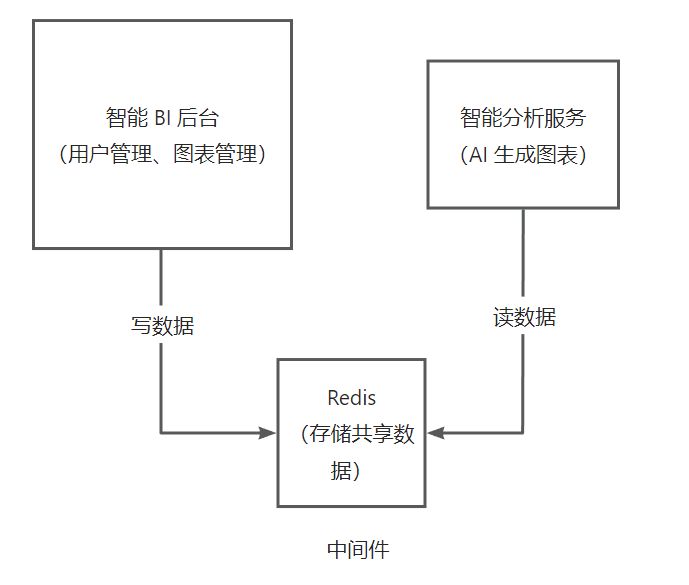
解决方案:可以有一个中间人,让中间人帮我们去连接两个系统(比如核心系统和智能生成业务)
中间件
连接多个系统,帮助多个系统紧密协作的技术(或者组件)
比如:Redis,消息队列,分布式存储Etcd
消息队列
什么是消息队列?
存储消息的队列。
存储:存数据
消息:某种数据结构。比如字符串,对象,二进制数据,JSON等等
队列:先进先出的数据结构
应用场景
在多个不同的系统,应用之间实现消息的传输(也可以存储),不需要考虑传输应用的编程语言,系统,框架等等
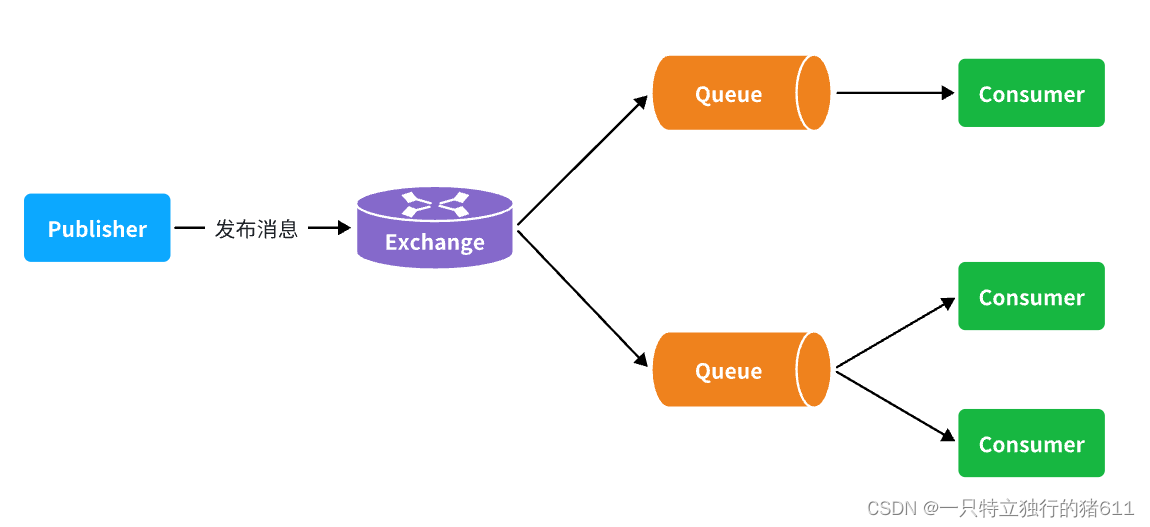
消息队列的模型
生产者,消费者,消息,消息队列
为什么不直接传输,而要用消息队列?
生产者不用关心你的消费者要不要消费,什么时候才消费,我只需要把东西给消费队列,我的工作就算完成了,生产者和消费者实现了解耦,互不影响
为什么要用消息队列?
1)异步处理
生产者发送完消息之后,可以继续去忙别的,消费者想什么时候消费都可以,不会产生阻塞
2)削峰填谷
先把用户的请求放到消息队列中,消费者可以按照自己的需求,慢慢去取
原本:12 点时来了 10 万个请求,原本情况下,10万个请求都在系统内部立刻处理,很快系统压力过大就宕机了。
现在:把这 10万个请求放到消息队列中,处理系统以自己的恒定速率(比如每秒 1 个)慢慢执行,从而保护系统、稳定处理
消息队列的缺点?
增加成本(开发,维护,部署),消息丢失,顺序性,重复消费,数据一致性(分布式系统需要考虑)
分布式消息队列
分布式消息队列的优势?
1)数据持久化:可以把消息集中存储到硬盘里,服务器重启就不会丢失
2)可扩展性:可以根据需求,随时增加(或减少)节点,继续保持稳定的服务
3)应用解耦:可以连接各个不同的语言,框架开发的系统,让这些系统能够灵活传输读取数据
应用解耦的优点:
以前,把所有功能放到同一个项目中,调用多个子功能时,一个环节出错,系统就整体出错
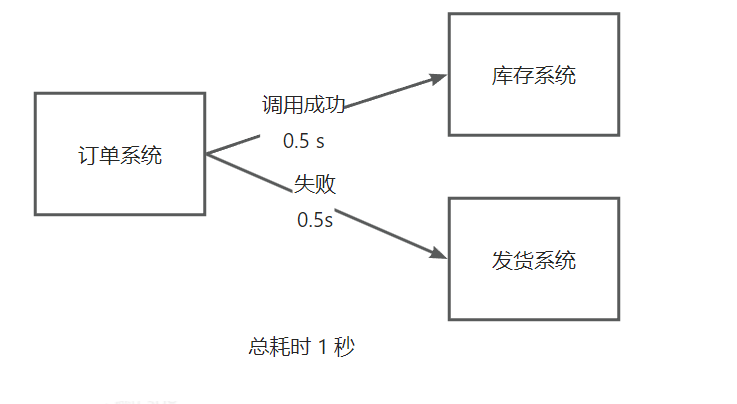
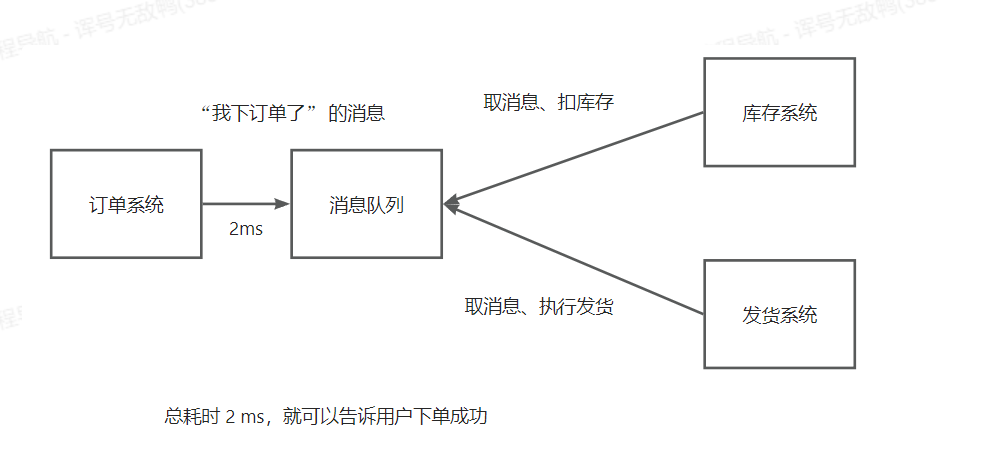
使用消息队列进行解耦:
- 一个系统挂了,不影响另一个系统
- 系统挂了并恢复后,仍然可以取出消息,继续执行业务
- 只要发送消息到队列,就可以立即返回,不用同步调用所有系统,性能更高
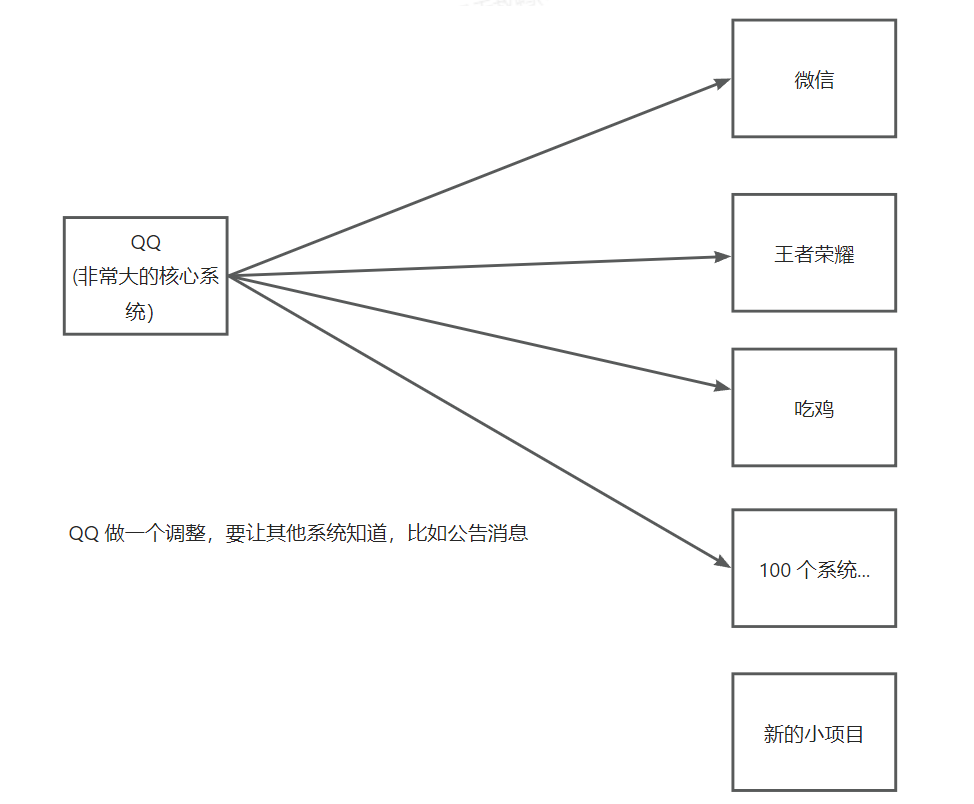
4)发布订阅:
如果一个非常大的系统要给其他子系统发送通知,最简单直接的方式是大系统直接依次调用子系统
问题:
- 每次发通知都要调用很多系统,很麻烦,有可能失败
- 新出现的项目无法得到通知
解决方案:大的核心系统始终往一个地方(消息队列)去发消息,其他的系统都去订阅这个消息队列(读取消息队列中的消息)
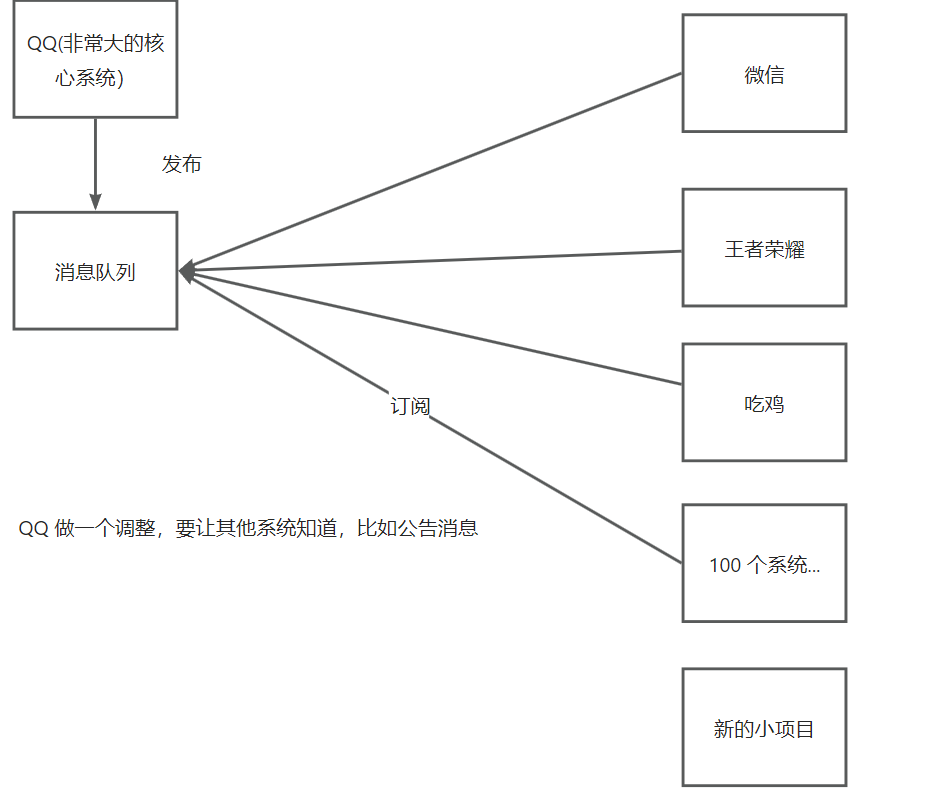 打个比喻,老板(发布者)要通知一件事情给员工(消费者),方式1 :给员工依次发通知;方式2 :建个群(消息队列)发通知。方式一不仅非常麻烦耗时,有时候网不好(服务器压力大时)还发不出去。方式2呢就是老板只需要把消息发送到群里(消息队列),员工打开查看即可。
打个比喻,老板(发布者)要通知一件事情给员工(消费者),方式1 :给员工依次发通知;方式2 :建个群(消息队列)发通知。方式一不仅非常麻烦耗时,有时候网不好(服务器压力大时)还发不出去。方式2呢就是老板只需要把消息发送到群里(消息队列),员工打开查看即可。
消息队列应用场景
- 耗时的场景(异步)
- 高并发场景(异步,削峰填谷)
- 分布式系统协作(跨团队,跨业务协作,应用解耦)
- 强稳定性的业务(比如金融业务,持久化,可靠性,削峰填谷)
主流分布式消息队列选型
主流技术
- activemq
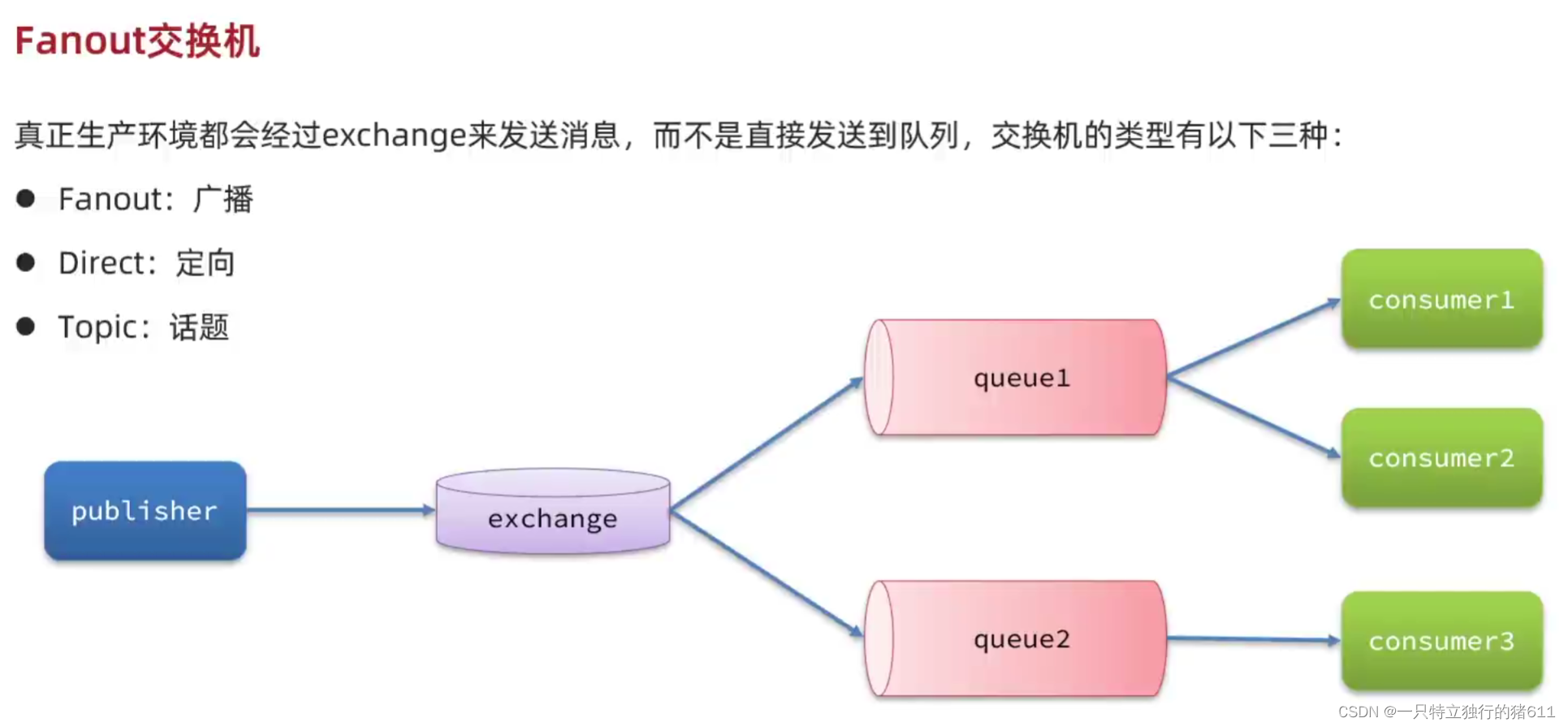
- rabbitmq
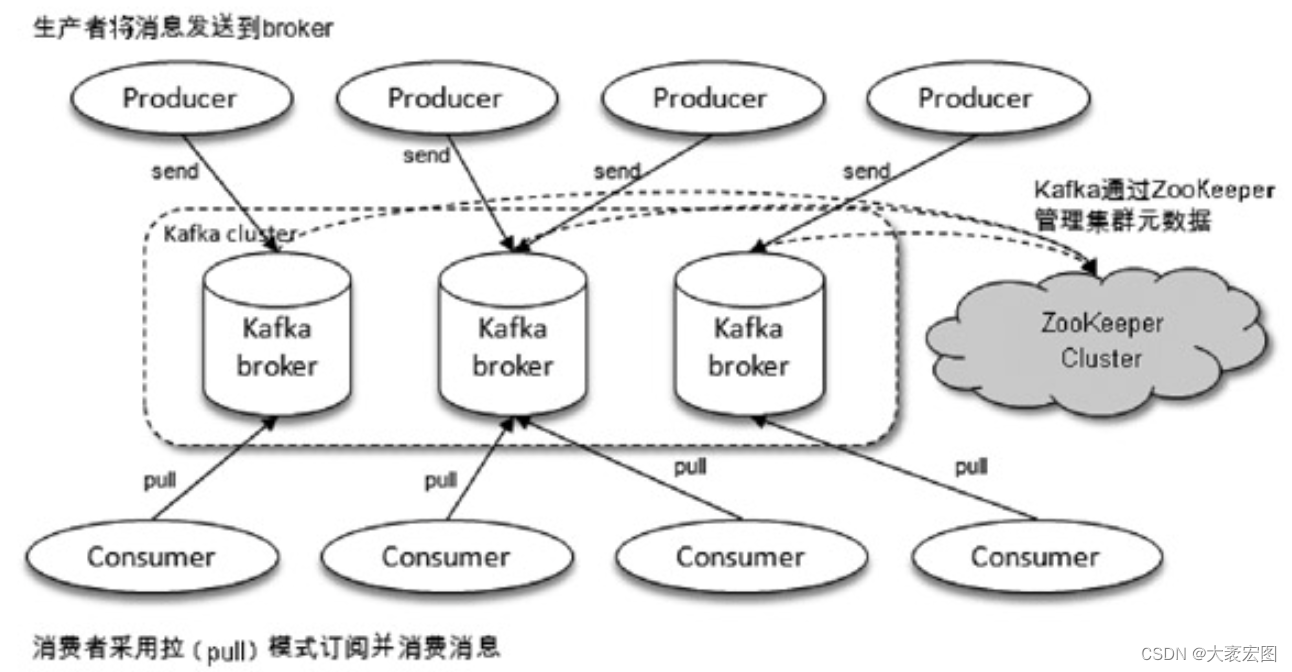
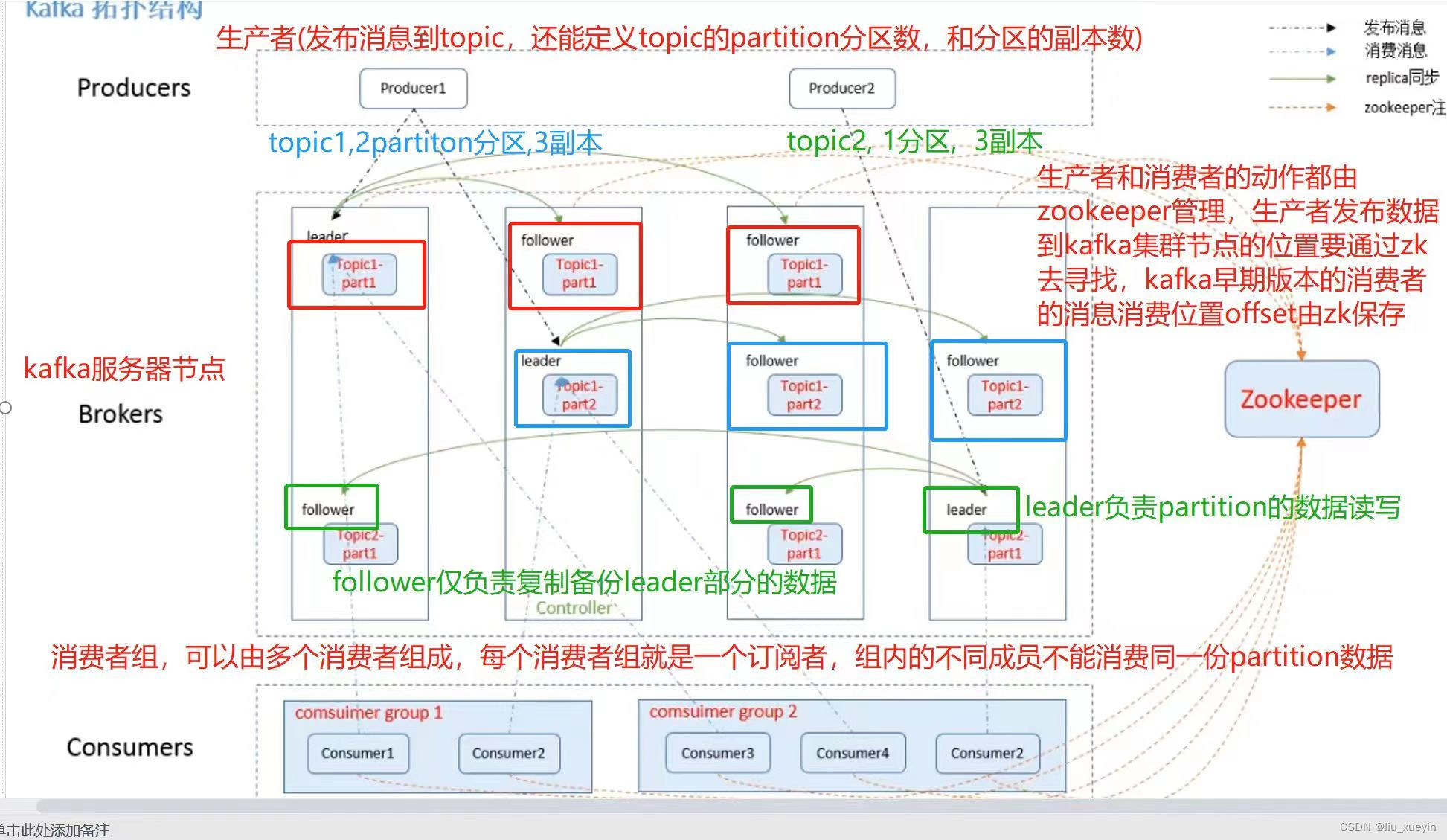
- kafka
- rocketmq
- zeromq
- pulsar(云原生)
- Apache InLong(Tube)
技术对比
技术选型指标:
- 吞吐量:IO,高并发
- 时效性:类似延迟,消息的发送,到达时间
- 可用性:系统可用的比率
- 可靠性:消息不丢失,功能正常完成
| 技术名称 | 吞吐量 | 时效性 | 可用性 | 可靠性 | 优势 | 应用场景 |
|---|---|---|---|---|---|---|
| activemq | 万级 | 高 | 高 | 高 | 简单易学 | 中小型企业、项目 |
| rabbitmq | 万级 | 极高(微秒) | 高 | 高 | 生态好(基本什么语言都支持)、时效性高、易学 | 适合绝大多数分布式的应用,这也是先学他的原因 |
| kafka | 十万级 | 高(毫秒以内) | 极高 | 极高 | 吞吐量大、可靠性、可用性,强大的数据流处理能力 | 适用于 大规模处理数据的场景,比如构建日志收集系统、实时数据流传输、事件流收集传输 |
| rocketmq | 十万级 | 高(ms) | 极高 | 极高 | 吞吐量大、可靠性、可用性,可扩展性 | 适用于 金融 、电商等对可靠性要求较高的场景,适合 大规模 的消息处理。 |
| pulsar | 十万级 | 高(ms) | 极高 | 极高 | 可靠性、可用性很高,基于发布订阅模型,新兴(技术架构先进) | 适合大规模、高并发的分布式系统(云原生)。适合实时分析、事件流处理、IoT 数据处理等。 |
由此看来RabbitMQ不仅应用广泛,而且易于学习,下期分享RabbitMQ入门实战