第1关:Bagging
任务描述
本关任务:补充 python 代码,完成 BaggingClassifier 类中的 fit 和 predict 函数。请不要修改 Begin-End 段之外的代码。
import numpy as np
from collections import Counter
from sklearn.tree import DecisionTreeClassifier
class BaggingClassifier():
def __init__(self, n_model=10):
'''
初始化函数
'''
#分类器的数量,默认为10
self.n_model = n_model
#用于保存模型的列表,训练好分类器后将对象append进去即可
self.models = []
def fit(self, feature, label):
'''
训练模型
:param feature: 训练数据集所有特征组成的ndarray
:param label:训练数据集中所有标签组成的ndarray
:return: None
'''
#************* Begin ************#
for i in range(self.n_model):
m = len(feature)
index = np.random.choice(m, m)
sample_data = feature[index]
sample_lable = label[index]
model = DecisionTreeClassifier()
model = model.fit(sample_data, sample_lable)
self.models.append(model)
#************* End **************#
def predict(self, feature):
'''
:param feature:训练数据集所有特征组成的ndarray
:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])
'''
#************* Begin ************#
result = []
vote = []
for model in self.models:
r = model.predict(feature)
vote.append(r)
vote = np.array(vote)
for i in range(len(feature)):
v = sorted(Counter(vote[:, i]).items(), key=lambda x: x[1], reverse=True)
result.append(v[0][0])
return np.array(result)
#************* End **************#
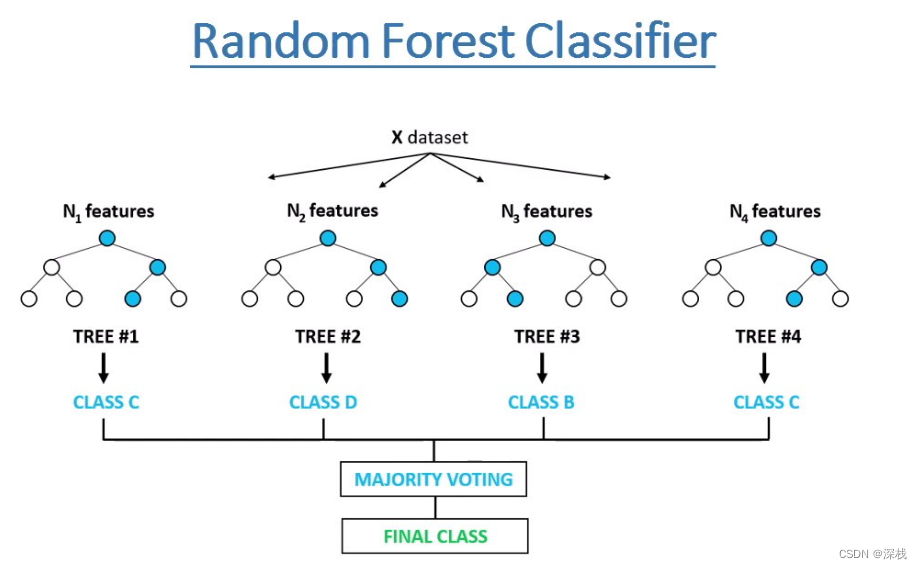
第2关:随机森林算法流程
任务描述
本关任务:补充 python 代码,完成 RandomForestClassifier 类中的 fit 和 predict 函数。请不要修改 Begin-End 段之外的代码。
import numpy as np
from collections import Counter
from sklearn.tree import DecisionTreeClassifier
class RandomForestClassifier():
def __init__(self, n_model=10):
'''
初始化函数
'''
#分类器的数量,默认为10
self.n_model = n_model
#用于保存模型的列表,训练好分类器后将对象append进去即可
self.models = []
#用于保存决策树训练时随机选取的列的索引
self.col_indexs = []
def fit(self, feature, label):
'''
训练模型
:param feature: 训练数据集所有特征组成的ndarray
:param label:训练数据集中所有标签组成的ndarray
:return: None
'''
#************* Begin ************#
for i in range(self.n_model):
m = len(feature)
index = np.random.choice(m, m)
col_index = np.random.permutation(len(feature[0]))[:int(np.log2(len(feature[0])))]
sample_data = feature[index]
sample_data = sample_data[:, col_index]
sample_lable = label[index]
model = DecisionTreeClassifier()
model = model.fit(sample_data, sample_lable)
self.models.append(model)
self.col_indexs.append(col_index)
#************* End **************#
def predict(self, feature):
'''
:param feature:训练数据集所有特征组成的ndarray
:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])
'''
#************* Begin ************#
result = []
vote = []
for i, model in enumerate(self.models):
f = feature[:, self.col_indexs[i]]
r = model.predict(f)
vote.append(r)
vote = np.array(vote)
for i in range(len(feature)):
v = sorted(Counter(vote[:, i]).items(), key=lambda x: x[1], reverse=True)
result.append(v[0][0])
return np.array(result)
#************* End **************#
第3关:手写数字识别
任务描述
本关任务:使用 sklearn 中的 RandomForestClassifier 类完成手写数字识别任务。请不要修改Begin-End段之外的代码。
from sklearn.ensemble import RandomForestClassifier
import numpy as np
def digit_predict(train_image, train_label, test_image):
'''
实现功能:训练模型并输出预测结果
:param train_image: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8]
:param train_label: 包含多条训练样本标签的标签集,类型为ndarray
:param test_image: 包含多条测试样本的测试集,类型为ndarry
:return: test_image对应的预测标签,类型为ndarray
'''
#************* Begin ************#
X = np.reshape(train_image, newshape=(-1, 64))
clf = RandomForestClassifier(n_estimators=500, max_depth=10)
clf.fit(X, y=train_label)
return clf.predict(test_image)
#************* End **************#