哪种运行模式是使用Hadoop的最佳方式,真实Hadoop集群的运行均采用该模式?
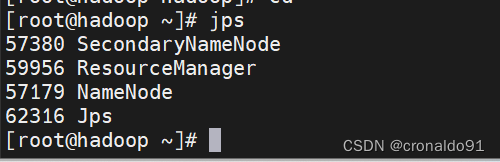
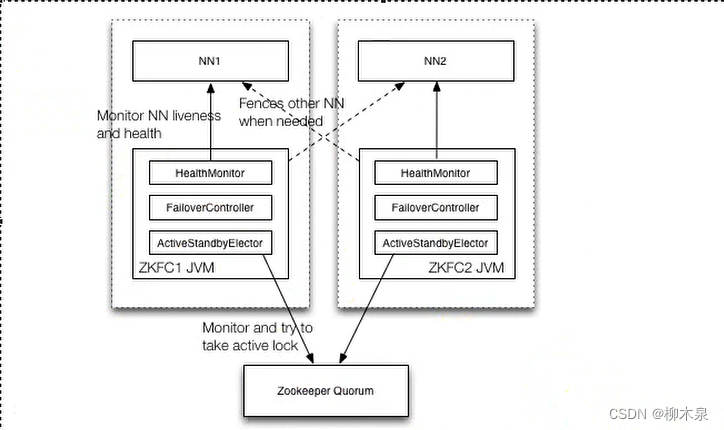
真实Hadoop集群的运行通常采用全分布模式(Fully Distributed Mode)。在全分布模式下,Hadoop集群会跨越多个物理或虚拟节点,每个节点扮演不同的角色,如NameNode、DataNode、ResourceManager和NodeManager等。这种模式能够提供最佳的扩展性、可靠性和性能,因为数据被分布在多个节点上,且计算任务可以在多个节点上并行执行。
全分布模式是使用Hadoop处理大规模数据集和实现大数据应用的最佳方式,因为它允许集群充分利用所有节点的资源,实现负载均衡,并且在节点发生故障时能够保持服务的连续性和数据的安全性。
以下哪些是Apache软件基金会下的分布式计算框架?
Apache软件基金会下有几个著名的分布式计算框架,包括:
1. **Apache Hadoop**:一个开源框架,允许分布式处理大规模数据集横跨计算机集群。
2. **Apache Spark**:一个快速和通用的大数据计算引擎,提供了丰富的APIs用于进行大规模数据处理。
3. **Apache Flink**:一个流处理框架,也支持批处理和数据流分析,旨在提供准确的结果和高性能。
4. **Apache Storm**:一个实时处理系统的框架,可以可靠地处理无限数据流。
5. **Apache Samza**:一个分布式流处理框架,与Apache Kafka紧密集成,用于处理实时数据。
这些框架各自有不同的特点和用例,但它们都旨在简化分布式计算和数据处理任务。
下列对Hadoop生态系统中各组件的理解,正确的有哪些?
在Hadoop生态系统中,有许多组件,每个组件都有其特定的用途和功能。以下是对一些核心组件的理解:
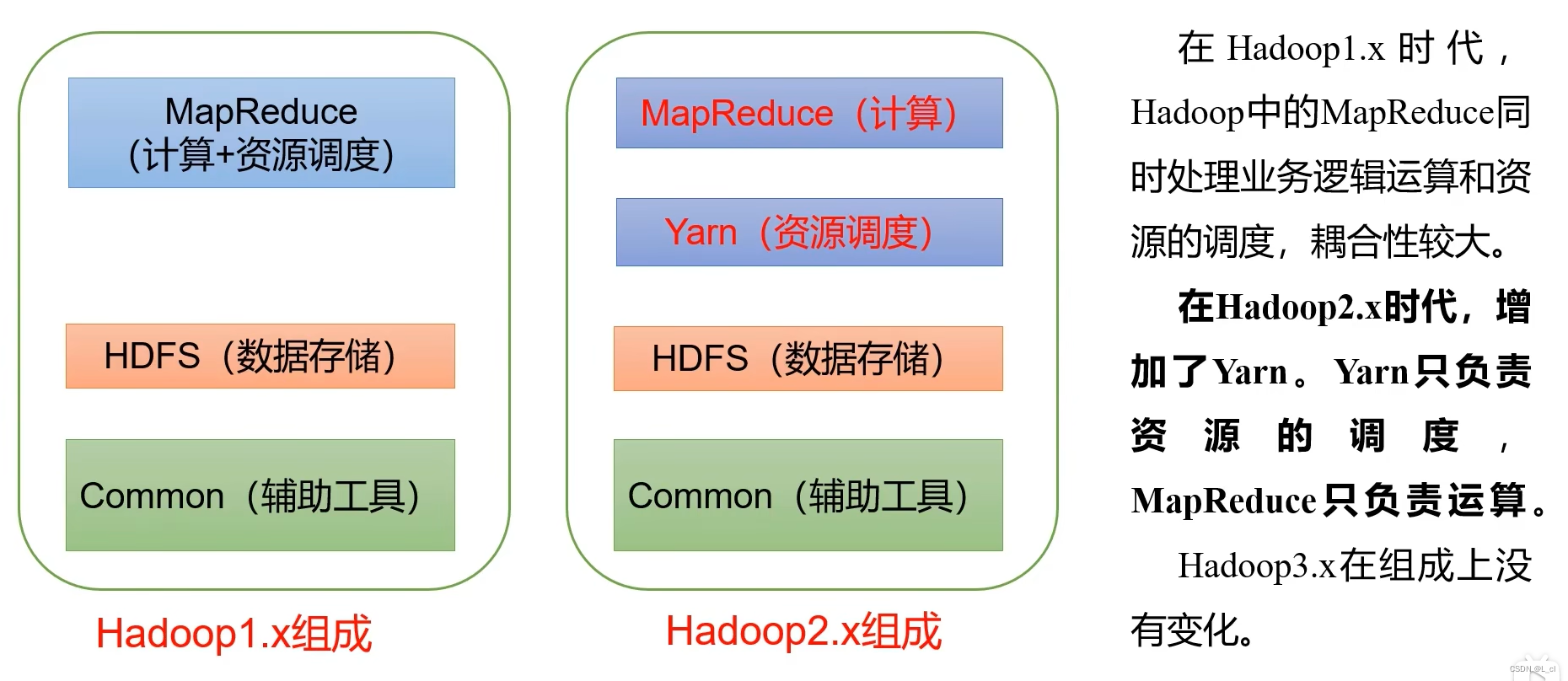
1. **Hadoop Common**:提供了Hadoop其他模块所需的公共工具和库,包括配置、日志、序列化机制等。
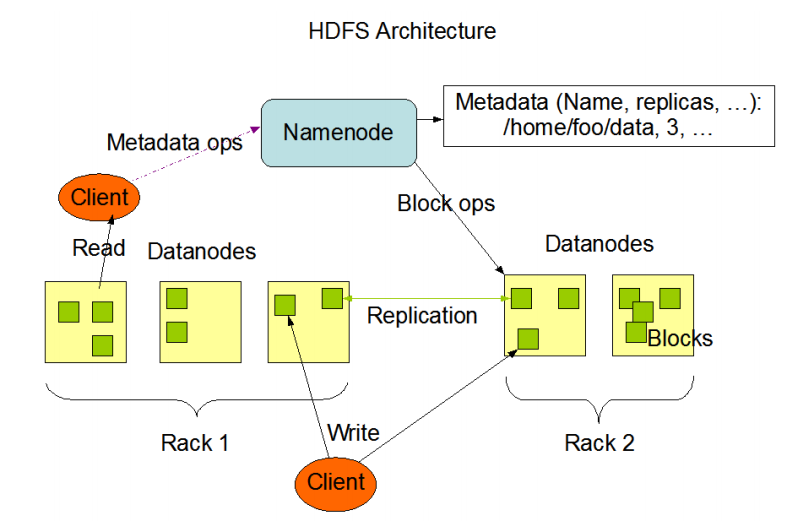
2. **Hadoop Distributed File System (HDFS)**:一个分布式文件系统,用于存储海量数据,提供高吞吐量的数据访问,并且能够可靠地存储跨多个节点的数据。
3. **Hadoop YARN (Yet Another Resource Negotiator)**:一个资源管理平台,负责管理计算资源,支持多种计算框架在同一个集群上运行。
4. **Hadoop MapReduce**:一个编程模型,用于大规模数据处理。它允许用户轻松地编写并行处理大数据集的程序。
5. **Apache Hive**:一个数据仓库基础设施,提供数据摘要和查询功能。它允许用户使用类似SQL的查询语言(HiveQL)来查询存储在HDFS中的数据。
6. **Apache HBase**:一个分布式、可扩展、面向列的存储系统,用于存储大量的稀疏数据集,适用于非结构化和半结构化数据。
7. **Apache Spark**:一个快速的分布式计算系统,它提供了比MapReduce更丰富的操作,包括流处理、复杂的数据集操作等。
8. **Apache Pig**:一个高级平台,用于创建复杂的 MapReduce 程序,它提供了一个简单的脚本语言(Pig Latin)用于数据分析。
9. **Apache Sqoop**:用于在Hadoop和结构化数据存储(如关系数据库)之间传输数据的工具。
10. **Apache Flume**:一个分布式、可靠且可用的服务,用于有效地收集、聚合和移动大量日志数据。
11. **Apache Oozie**:一个工作流调度系统,用于运行Hadoop作业。
12. **Apache ZooKeeper**:一个提供分布式系统协调服务的小型服务器,用于维护配置信息、命名服务、分布式同步等。
以上对Hadoop生态系统中各组件的理解都是正确的。每个组件都有其特定的角色,共同构成了一个强大的大数据处理平台。
以下关于Hadoop生态系统中各组件的功能,叙述正确的是哪些?
以下关于Hadoop生态系统中各组件功能的叙述是正确的:
1. **Hadoop Common**:提供了Hadoop其他模块所需的公共工具和库,包括配置、日志、序列化机制等。
2. **Hadoop Distributed File System (HDFS)**:一个分布式文件系统,用于存储海量数据,提供高吞吐量的数据访问,并且能够可靠地存储跨多个节点的数据。
3. **Hadoop YARN (Yet Another Resource Negotiator)**:一个资源管理平台,负责管理计算资源,支持多种计算框架在同一个集群上运行。
4. **Hadoop MapReduce**:一个编程模型,用于大规模数据处理。它允许用户轻松地编写并行处理大数据集的程序。
5. **Apache Hive**:一个数据仓库基础设施,提供数据摘要和查询功能。它允许用户使用类似SQL的查询语言(HiveQL)来查询存储在HDFS中的数据。
6. **Apache HBase**:一个分布式、可扩展、面向列的存储系统,用于存储大量的稀疏数据集,适用于非结构化和半结构化数据。
7. **Apache Spark**:一个快速的分布式计算系统,它提供了比MapReduce更丰富的操作,包括流处理、复杂的数据集操作等。
8. **Apache Pig**:一个高级平台,用于创建复杂的 MapReduce 程序,它提供了一个简单的脚本语言(Pig Latin)用于数据分析。
9. **Apache Sqoop**:用于在Hadoop和结构化数据存储(如关系数据库)之间传输数据的工具。
10. **Apache Flume**:一个分布式、可靠且可用的服务,用于有效地收集、聚合和移动大量日志数据。
11. **Apache Oozie**:一个工作流调度系统,用于运行Hadoop作业。
12. **Apache ZooKeeper**:一个提供分布式系统协调服务的小型服务器,用于维护配置信息、命名服务、分布式同步等。
这些组件共同构成了Hadoop生态系统,每个组件都在大数据处理中扮演着重要的角色。
启动和管理Hadoop守护进程,只需要在主节点上执行命令即可,全分布模式下,执行start-yarn.sh命令后会在YARN从节点上启动以下哪些进程?
在全分布模式下,执行`start-yarn.sh`命令后,会在YARN的从节点上启动以下进程:
1. **NodeManager**:这是YARN中从节点的守护进程,负责与ResourceManager通信,管理容器生命周期,监控容器的资源使用情况(如内存、CPU等),并报告给ResourceManager。
请注意,`start-yarn.sh`脚本主要在主节点上启动ResourceManager进程,并触发从节点上的NodeManager进程的启动。但是,实际启动NodeManager的过程可能依赖于集群的配置,比如使用SSH或特定于发行版的脚本。此外,`start-yarn.sh`脚本还会启动一个辅助服务,即WebAppProxy服务,但这通常是在主节点上。
在执行`start-yarn.sh`之前,通常需要确保Hadoop的配置文件已经正确设置,并且集群中的所有节点都能够相互通信。此外,还需要确保HDFS已经启动并运行,因为YARN作业可能需要访问HDFS上的数据。
启动和管理Hadoop守护进程,只需要在主节点上执行命令即可,全分布模式下,start-dfs.sh命令会在HDFS主节点上启动以下哪些进程?
在全分布模式下,执行`start-dfs.sh`命令后,会在HDFS的主节点上启动以下进程:
1. **NameNode**:这是HDFS的核心组件,负责管理文件系统的命名空间,即维护文件系统树及整个文件系统的元数据。
2. **Secondary NameNode**:虽然它的名称带有"NameNode",但实际上它不是NameNode的一个备份,而是辅助NameNode工作,定期合并编辑日志(edits log)和文件系统镜像(fsimage),以防止编辑日志过大。
请注意,`start-dfs.sh`脚本还会在从节点上启动DataNode进程,这些进程负责管理存储在本地文件系统上的数据块,并与NameNode通信,执行数据块的读写操作。
在执行`start-dfs.sh`之前,需要确保Hadoop的配置文件已经正确设置,包括`hdfs-site.xml`、`core-site.xml`等,并且集群中的所有节点都能够相互通信。此外,还需要确保HDFS的数据目录已经创建并且有适当的权限设置。
哪个Hadoop配置文件指定了运行DataNode和NodeManager进程的从节点主机名列表,而在全分布模式下必须修改该文件,将所有从节点主机名添加进去,且要求每一个主机名占一行?
在Hadoop中,没有特定的配置文件直接指定运行DataNode和NodeManager进程的从节点主机名列表。相反,Hadoop通过其他机制来自动识别和管理集群中的节点。
在Hadoop 2及以后的版本中,通常不需要手动列出所有从节点的主机名。DataNode和NodeManager会在启动时自动注册到NameNode和ResourceManager,因此,从节点的主机名列表通常不需要在配置文件中明确指定。
然而,在Hadoop 1.x版本中,或者在特定配置的集群中,可能会有一个名为`slaves`的文件(在Hadoop 2.x及以后版本中,这个文件被称为`workers`),位于Hadoop配置目录下(通常是`$HADOOP_HOME/etc/hadoop`)。在这个文件中,每一行代表一个从节点的主机名或IP地址。但是,这种做法在现代的Hadoop版本中已经不常用了,因为YARN和HDFS都能够动态管理节点。
在全分布模式下,通常只需要确保所有节点都能够相互通信,并且配置好SSH无密码登录,然后使用`start-dfs.sh`和`start-yarn.sh`脚本来启动集群。这些脚本会自动在每个节点上启动相应的守护进程。如果需要排除某些节点或者有特定的节点管理需求,可能需要修改集群的配置文件或者使用其他管理工具。
配置SSH免密码登录并不是部署Hadoop集群的必需步骤,配置它仅是为了方便集群测试,达到所有节点之间都能免密码登录,配置SSH的关键步骤包括:(1)检查SSH是否安装,若没安装则安装;(2)修改sshd配置文件并重启sshd服务;(3)在家目录生成公钥和私钥,并将公钥内容追加到authorized_key授权密钥中;(4)从主节点共享公钥到从节点上。请问正确的操作顺序是什么?
正确的操作顺序是:
1. **检查SSH是否安装,若没安装则安装**:首先,您需要确保所有节点上都安装了SSH服务。可以使用包管理工具(如`yum`、`apt-get`等)来安装SSH。
2. **在家目录生成公钥和私钥**:在主节点上,使用`ssh-keygen`命令生成公钥和私钥。默认情况下,这些密钥会被保存在`~/.ssh`目录下。
3. **修改sshd配置文件并重启sshd服务**:编辑`/etc/ssh/sshd_config`文件,确保以下选项设置正确:
- `RSAAuthentication` yes
- `PubkeyAuthentication` yes
- `AuthorizedKeysFile` .ssh/authorized_keys
修改完配置文件后,重启SSH服务以应用更改。对于不同的Linux发行版,重启命令可能不同,常见的命令有`service sshd restart`或`systemctl restart sshd`。
4. **将公钥内容追加到authorized_key授权密钥中**:使用`cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys`命令将生成的公钥内容追加到`~/.ssh/authorized_keys`文件中。
5. **从主节点共享公钥到从节点上**:使用`ssh-copy-id`命令将主节点的公钥复制到所有从节点的`~/.ssh/authorized_keys`文件中。这样,主节点就可以免密码登录到所有从节点。
完成以上步骤后,您应该能够在主节点上免密码SSH到所有从节点。这是Hadoop集群部署中的一个可选步骤,但在实际的生产环境中,为了安全起见,通常会配置SSH密钥登录,而不是完全禁用密码登录。
为了使用户无需记住IP地址串,从而协助用户便捷的通过主机名访问各个Hadoop节点,需要添加域名映射,具体要修改以下哪个配置文件?
为了使用户能够通过主机名便捷地访问各个Hadoop节点,您需要在集群中的每个节点上修改`/etc/hosts`文件,将该文件中添加域名映射。这样,您可以将每个节点的IP地址与易于记忆的主机名关联起来。
例如,您的`/etc/hosts`文件可能包含以下内容:
```
127.0.0.1 localhost
192.168.1.100 hadoop-master
192.168.1.101 hadoop-slave1
192.168.1.102 hadoop-slave2
...
127.0.0.1 localhost
192.168.1.100 hadoop-master
192.168.1.101 hadoop-slave1
192.168.1.102 hadoop-slave2
...
```
在这个例子中,`hadoop-master`、`hadoop-slave1`和`hadoop-slave2`是分配给各个节点的主机名,而`192.168.1.100`、`192.168.1.101`和`192.168.1.102`是这些节点的IP地址。
请注意,修改`/etc/hosts`文件是一种简单的域名解析方法,适用于小型或内部网络。在大型或更复杂的环境中,您可能需要一个完整的DNS服务器来管理主机名和IP地址的映射。
Hadoop集群采用
输入答案
架构。
主从架构
Google引爆大数据时代的三篇论文是哪些?
Google 引爆大数据时代的三篇论文分别是:
1. **Google File System (GFS)**: 这篇论文介绍了 Google 文件系统(GFS),一个可扩展的分布式文件系统,用于大型的、分布式数据密集型应用。GFS 设计用于运行在廉价的普通硬件上,并提供容错能力。它对后来的分布式文件系统设计产生了深远的影响,包括 Hadoop 的 HDFS(Hadoop Distributed File System)。
2. **MapReduce: Simplified Data Processing on Large Clusters**: 这篇论文介绍了 MapReduce 编程模型,它简化了大规模数据集的处理。MapReduce 允许开发者编写处理数据的应用程序,而无需关心并行处理、容错、数据分布等复杂问题。MapReduce 模型被广泛采用,并成为了大数据处理的标准之一。
3. **Bigtable: A Distributed Storage System for Structured Data**: 这篇论文介绍了 Bigtable,一个分布式存储系统,用于管理结构化数据。Bigtable 设计用于扩展到非常大的数据集,跨越数千台机器,并且支持对非关系型数据进行高效的随机读写访问。Bigtable 对后来的 NoSQL 数据库和分布式存储系统产生了重要影响。
这三篇论文共同奠定了大数据处理的基础,并对现代分布式计算和存储系统的发展产生了深远的影响。
下列不属于Apache中和Hadoop相关的项目有哪些?
Apache中有很多与Hadoop相关的项目,它们共同构成了Hadoop生态系统。但是也有一些项目与Hadoop无直接关联。以下是一些不属于Apache中和Hadoop相关的项目:
1. **Apache HTTP Server**:这是Apache软件基金会的一个项目,是一个开源的Web服务器软件,与Hadoop无直接关系。
2. **Apache Tomcat**:一个开源的Java Servlet容器,用于部署和运行Java Web应用程序,与Hadoop无直接关系。
3. **Apache Cassandra**:一个开源的分布式NoSQL数据库管理系统,虽然它与Hadoop一样用于处理大规模数据,但它是一个独立的项目,与Hadoop无直接关系。
4. **Apache Kafka**:一个开源的流处理平台,用于构建实时的数据管道和流式应用程序,虽然它可以与Hadoop生态系统中的项目(如Apache Storm和Apache Spark)集成,但它本身是一个独立的项目。
5. **Apache Solr**:一个开源的搜索平台,用于构建搜索应用程序,它与Hadoop无直接关系,但可以与Hadoop生态系统中的其他项目(如Apache Lucene)一起使用。
6. **Apache Maven**:一个项目管理和构建自动化工具,用于Java项目,与Hadoop无直接关系。
这些项目都是Apache软件基金会的成员,但它们并不是Hadoop生态系统的一部分。它们各自服务于不同的目的和用例。
启动和管理Hadoop守护进程,只需要在主节点上执行命令即可,全分布模式下,执行start-dfs.sh和start-yarn.sh命令后会在从节点上启动以下哪些进程?
在全分布模式下,执行`start-dfs.sh`和`start-yarn.sh`命令后,会在从节点上启动以下进程:
1. **DataNode**:`start-dfs.sh`命令会在从节点上启动DataNode进程。DataNode负责管理存储在本地文件系统上的数据块,并与NameNode通信,执行数据块的读写操作。
2. **NodeManager**:`start-yarn.sh`命令会在从节点上启动NodeManager进程。NodeManager负责与ResourceManager通信,管理容器生命周期,监控容器的资源使用情况(如内存、CPU等),并报告给ResourceManager。
这些进程的启动是由`start-dfs.sh`和`start-yarn.sh`脚本自动完成的,它们会通过SSH或其他机制在从节点上执行相应的启动命令。在全分布模式下,主节点上会启动NameNode和ResourceManager进程,而从节点上则会启动DataNode和NodeManager进程。这样,整个集群就可以协同工作,处理大数据集的计算和存储任务。
由于Hadoop配置文件繁多,配置过程复杂,而又要求所有配置文件每个节点都“机手一份”,所以推荐的快捷方法是在主节点上配置好,然后利用哪个命令将配置好的文件同步到所有从节点上?
在Hadoop集群中,配置文件同步的一个常见方法是使用`rsync`命令。`rsync`是一个用于远程同步文件的工具,它可以高效地将文件从一个位置复制到另一个位置,同时保持文件权限和所有权信息。
以下是一个使用`rsync`命令将配置文件从主节点同步到所有从节点的示例:
```sh
rsync -avz /path/to/hadoop/conf/ user@slave1:/path/to/hadoop/conf/
rsync -avz /path/to/hadoop/conf/ user@slave2:/path/to/hadoop/conf/
rsync -avz /path/to/hadoop/conf/ user@slave1:/path/to/hadoop/conf/
rsync -avz /path/to/hadoop/conf/ user@slave2:/path/to/hadoop/conf/
# ... 对其他从节点执行相同的命令
# ... 对其他从节点执行相同的命令
```
在这个命令中:
- `-a` 表示归档模式,保持符号链接、权限、时间戳、组和所有权信息。
- `-v` 表示详细输出,显示复制过程的详细信息。
- `-z` 表示压缩数据,在网络传输过程中减少数据量。
`user`是远程机器上的用户名,`slave1`、`slave2`等是远程机器的地址(可以是IP地址或主机名),`/path/to/hadoop/conf/`是Hadoop配置文件所在的本地路径和目标路径。
请确保您已经配置了无密码SSH登录,以便`rsync`命令可以无需密码地在节点之间同步文件。
此外,您也可以使用其他同步工具或脚本来实现配置文件的分发,比如`scp`、`pssh`或编写自定义的Shell脚本。重要的是确保所有节点上的配置文件保持一致,以便集群能够正确运行。
配置Java环境变量时,可以通过修改以下哪个配置文件完成?
在Linux系统中,配置Java环境变量通常涉及到修改以下几个配置文件之一:
1. **`~/.bashrc`**:这是针对当前用户的环境变量配置文件。在用户的家目录下,编辑`.bashrc`文件,可以添加Java环境变量的设置,这些设置将在用户打开新的终端会话时生效。
2. **`~/.bash_profile`**:这也是一个针对当前用户的环境变量配置文件。在某些Linux发行版中(如Red Hat和CentOS),`.bash_profile`会被用来设置用户的环境变量。
3. **`/etc/environment`**:这是一个系统级别的环境变量配置文件,对所有用户生效。在这个文件中设置环境变量会影响整个系统的环境。
4. **`/etc/profile`**:这个文件是全局性的环境变量配置文件,作用于所有用户。在`/etc/profile`中设置的环境变量会对所有用户生效。
5. **`/etc/profile.d/*.sh`**:在`/etc/profile.d/`目录下的shell脚本也会在用户登录时被加载,并用于设置环境变量。您可以在这个目录下创建一个新的shell脚本(例如`java.sh`),然后在该脚本中设置Java环境变量。
例如,在`~/.bashrc`文件中,您可以添加以下行来设置Java环境变量:
```sh
export JAVA_HOME=/path/to/java
export PATH=$JAVA_HOME/bin:$PATH
```
export JAVA_HOME=/path/to/java
export PATH=$JAVA_HOME/bin:$PATH
保存文件并关闭编辑器后,您需要执行以下命令来使更改生效:
```sh
source ~/.bashrc
source ~/.bashrc
```
或者,如果是在`/etc/environment`或`/etc/profile`中修改,可能需要重启系统或注销当前会话。
请注意,具体的文件和命令可能会因不同的Linux发行版和用户的个人配置而有所不同。
Linux下查看IP地址的命令是哪个?
在Linux下查看IP地址的命令通常是`ip addr`或者`ifconfig`。以下是这两个命令的基本使用方法:
1. **`ip addr`**:
- 打开终端。
- 输入命令 `ip addr` 或 `ip addr show`。
- 按下回车键。
- 查看输出信息,其中包含每个网络接口的IP地址信息。
2. **`ifconfig`**:
- 打开终端。
- 输入命令 `ifconfig`。
- 按下回车键。
- 查看输出信息,其中包含每个网络接口的IP地址信息。
`ip addr`命令是较新的用来查看和操作网络接口的命令,而`ifconfig`是较旧的命令,可能在一些较新的Linux发行版中不再默认安装。如果您的系统上没有`ifconfig`命令,您可以通过安装相应的包来获取它。例如,在基于Debian的系统上,您可以使用以下命令安装`ifconfig`:
```sh
sudo apt-get install net-tools
sudo apt-get install net-tools
```
在基于Red Hat的系统上,您可以使用以下命令安装`ifconfig`:
```sh
sudo yum install net-tools
sudo yum install net-tools
```
安装完成后,您就可以使用`ifconfig`命令来查看IP地址
配置静态IP地址时,下列哪个参数选项指的是静态IP地址?
在配置静态IP地址时,通常使用的参数选项是 `static`。这个参数告诉网络配置系统您想要手动设置IP地址,而不是通过DHCP自动获取。在不同的配置文件或命令中,您可能会看到如下用法:
- 在`ifconfig`命令中(尽管在现代Linux系统中,`ifconfig`已经被`ip`命令取代),您可以使用`ifconfig`接口`static`来手动设置IP地址。
- 在网络接口配置文件(如`/etc/network/interfaces`在Debian/Ubuntu系统中,或`/etc/sysconfig/network-scripts/ifcfg-<interface>`在Red Hat/Fedora/CentOS系统中),您可能会看到`BOOTPROTO=static`这样的行,表示接口应该使用静态IP地址。
例如,在Red Hat/Fedora/CentOS系统中,`ifcfg-<interface>`文件中的配置可能如下所示:
```sh
TYPE=Ethernet
BOOTPROTO=static
IPADDR=192.168.1.100
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=8.8.8.8
DNS2=8.8.4.4
```
TYPE=Ethernet
BOOTPROTO=static
IPADDR=192.168.1.100
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=8.8.8.8
DNS2=8.8.4.4
在这里,`BOOTPROTO=static`指示网络接口使用静态IP地址配置。其他参数如`IPADDR`、`NETMASK`、`GATEWAY`和`DNS*`分别指定了IP地址、子网掩码、默认网关和DNS服务器地址。