Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
![]()

目录
0. 摘要
这项研究探讨了文本条件扩散模型推理过程中交叉注意力的作用。我们发现,在少数推理步骤后,交叉注意力的输出会收敛到一个固定点。因此,收敛的时间点自然地将整个推理过程分为两个阶段:一个初始的语义规划阶段,在此阶段,模型依赖交叉注意力来规划文本导向的视觉语义;以及一个随后的增强保真度阶段,在此阶段,模型试图从之前规划的语义中生成图像。令人惊讶的是,在增强保真度阶段忽略文本条件不仅降低了计算复杂度,而且还保持了模型性能。这产生了一种简单且无需训练的方法,称为 T-GATE(temporally gating the cross-attention),用于高效生成,它在交叉注意力输出收敛后将其缓存,并在剩余的推理步骤中保持不变。我们在 MS-COCO 验证集上的实证研究证实了其有效性。
项目页面:https://github.com/HaozheLiu-ST/T-GATE

4. 交叉注意力的时间分析
4.1. 交叉注意力图的收敛性
在扩散模型中,交叉注意力机制在每个步骤中提供文本指导。然而,考虑到这些步骤中噪声输入的变化,这引发了思考:交叉注意力生成的特征图是否具有时间稳定性,还是随时间波动?
为了找到答案,我们随机收集了来自 MS-COCO 数据集的 1,000 个标题(caption),并使用预训练的 SD-2.1 模型和无分类器引导(CFG)生成图像。在推理过程中,我们计算了 C^t 和 C^(t+1) 之间的 L2 距离,其中 C^t 表示时间步 t 处的交叉注意力图。在所有输入标题、条件和深度之间平均 L2 距离,得到两个步骤之间的交叉注意力差异。
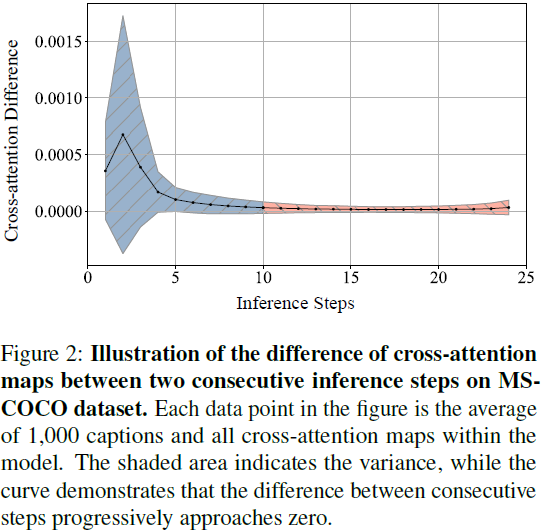
图 2 说明了在各种推理步骤中交叉注意力差异的变化情况。一个明显的趋势出现了,显示出这些差异朝着零逐渐收敛。收敛总是在 5 到 10 个推理步骤内出现。因此,交叉注意力图会收敛到一个固定点,并且不再为图像生成提供动态指导。这一发现从交叉注意力的角度支持了 CFG 的有效性,证明了尽管条件和初始噪声不同,无条件和有条件 batch 可以朝着单一且一致的结果收敛(Castillo等人,2023年)。这一现象表明,交叉注意力在推理过程中的影响并不是均匀的,启发了下一节对交叉注意力的时间分析。
4.2. 交叉注意力在推理中的作用
分析工具。现有的分析(Ma等人,2023年)显示,扩散模型的连续推理步骤具有相似的去噪行为。因此,受到行为解释的启发(Bau等人,2020年;刘等人,2023年),我们通过在特定阶段有效地 “移除” 交叉注意力并观察生成质量的差异来衡量交叉注意力的影响。在实践中,这种移除通过用空文本的占位符(“Ø”)替换原始文本嵌入来近似实现。我们将标准的去噪轨迹形式化为一个序列:
![]()
我们简化了时间步长 t 和指导比例 w。从序列 S 生成的图像用 x 表示。然后,我们通过在指定的推理间隔内将条件文本嵌入 c 替换为空文本嵌入 ∅ 来修改这个标准序列,基于标量 m,得到两个新序列:
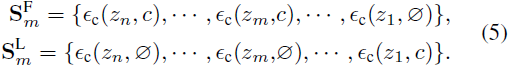
在这里,m 作为一个门控步(gate step),将轨迹分为两个阶段。在序列 S^F_m 中,从 m+1 到 n 步,空文本嵌入 ∅ 替代了原始文本嵌入 c。相反,在序列 S^L_m 中,从 1 到 m 步使用空文本嵌入 ∅ 而不是原始文本嵌入 c。我们分别用 x^F_m 和 x^L_m 表示从这两个轨迹生成的图像。为了确定在不同阶段的交叉注意力的影响,我们比较了 x、x^F_m 和 x^L_m 之间生成质量的差异。如果在 x 和 x_F^m 之间的生成质量有显著差异,这表明在那个阶段交叉注意力的重要性。相反,如果没有实质性的变化,那么包括交叉注意力可能就不是必要的。
我们使用 SD-2.1 作为基础模型,并使用 DPM 求解器进行噪声调度。所有实验中的推理步骤设定为 25。用于可视化的文本提示是 “太空中骑马的宇航员的高质量照片。”
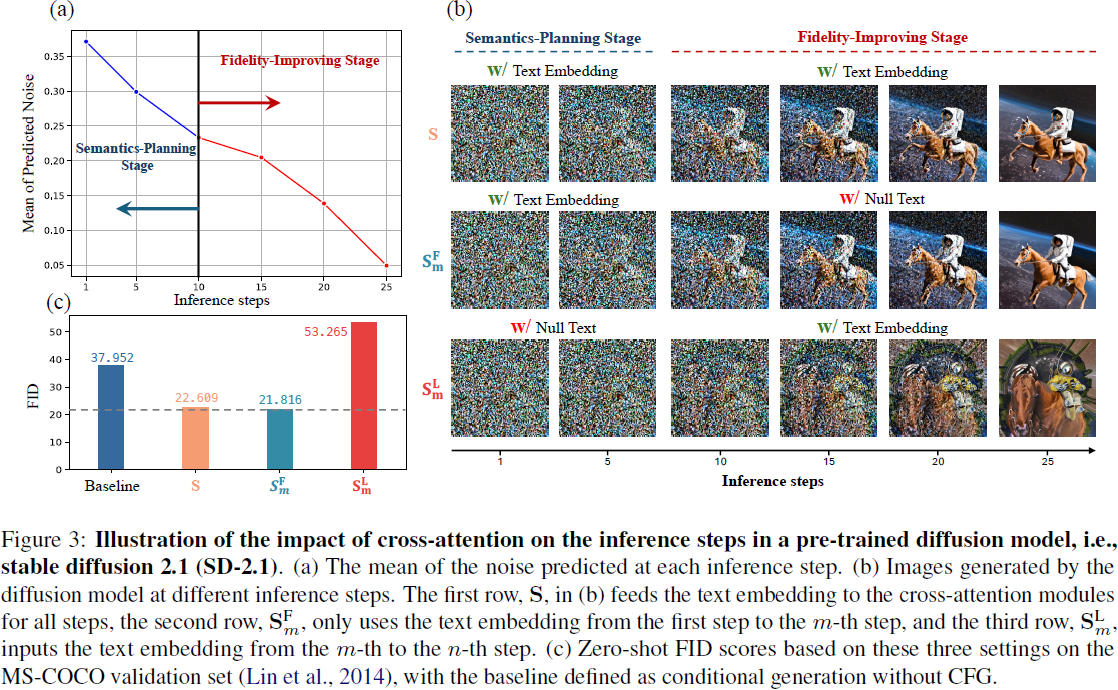
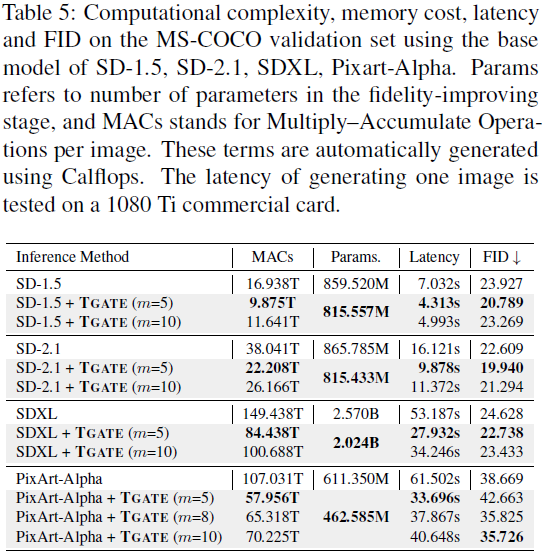
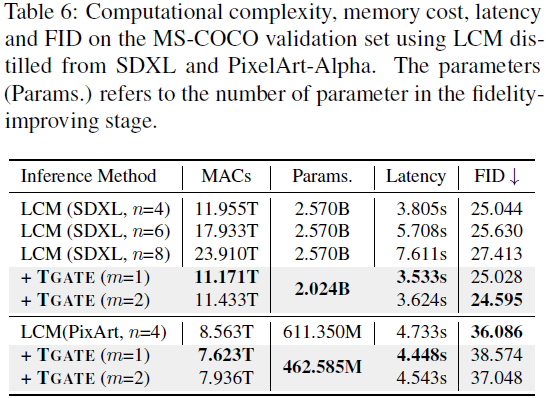
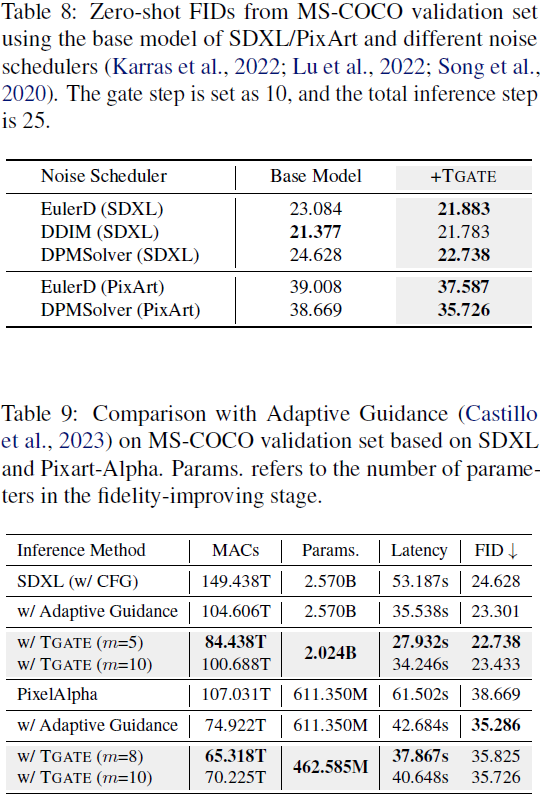
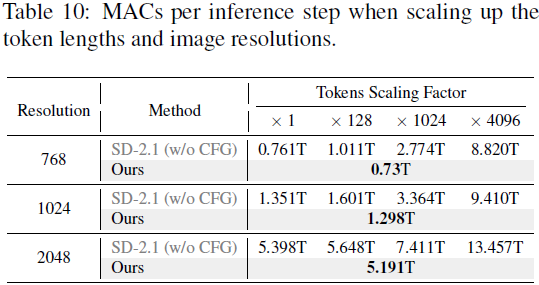
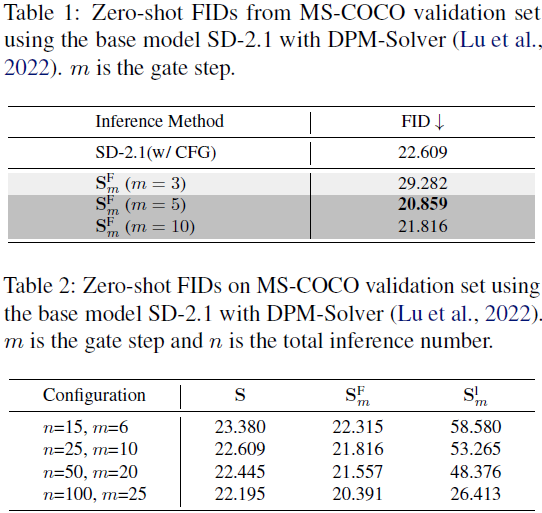
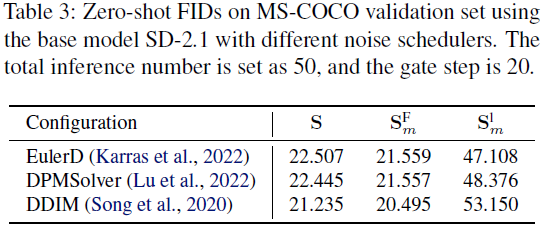
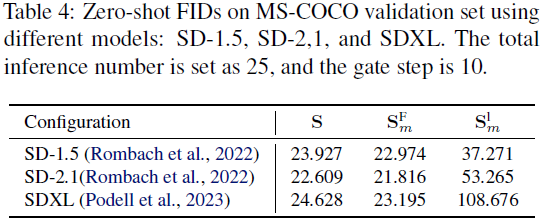
结果与讨论。我们在图 3(a) 中提供了预测噪声均值的轨迹,经验性地显示了在 25 个推理步骤后去噪过程的收敛。因此,在这个间隔内分析交叉注意力的影响是足够的。正如图 3(b) 所示,我们将门控步骤 m 设为 10,得到了三条轨迹:S、S^F_m 和 S^L_m。可视化结果表明,忽略了 10 步后的交叉注意力不会影响最终结果。然而,绕过交叉注意力的初始步骤则会导致显著的差异。正如图 3(c) 所示,这种消除会导致在 MS-COCO 验证集中生成质量(FID)显著下降,甚至比不使用 CFG 生成图像的弱基线更糟糕。我们对 {3,5,10} 不同门控步骤进行了进一步的实验。如表 1 所示,当门控步骤大于五步时,忽略交叉注意力的模型可以获得更好的 FID。为了进一步验证我们研究结果的泛化性,我们在不同条件下进行了实验,包括总推理次数范围、噪声调度器和基础模型。如表 2、3 和 4 所示,我们报告了在 MS-COCO 验证集上的 S、S^F_m 和 S^L_m 的 FID。实验结果一致表明 S^F_m 的 FID 稍微优于基线 S,并且明显优于 S^L_m。这些研究强调了这些结果具有广泛适用性的潜力。
我们总结我们的分析如下:
- 交叉注意力在推理过程早期收敛,可以表征为语义规划和提高保真度两个阶段。在这两个阶段中,交叉注意力的影响并不均匀。
- 语义规划阶段的交叉注意力对生成与文本条件一致的语义具有重要意义。
- 提高保真度阶段主要是提高图像质量,而不需要交叉注意力。在这个阶段的空文本嵌入可以略微提高 FID 分数。(为什么?)
根据以上观察,我们提出了一种方法,名为 T-GATE,可以去除交叉注意力,同时节省计算资源并提高 FID 分数。
5. T-GATE
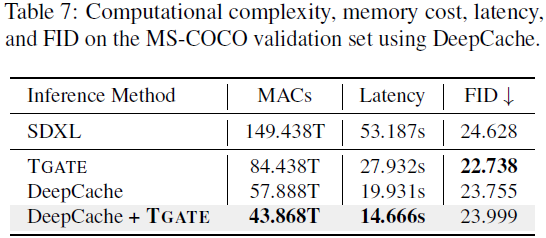
我们的实验研究表明,在最后的推理步骤中计算交叉注意力是多余的。然而,不重新训练模型就删除/替换交叉注意力是不容易的。受 DeepCache(Ma 等人,2023年)的启发,我们提出了一种名为 T-GATE 的有效且无需训练的方法。该方法缓存了来自语义规划阶段的注意力结果,并在提高保真度阶段重复使用这些结果。
缓存交叉注意力图。假设 m 是阶段转换的门控步骤。在第 m 步和第 i 个交叉注意力模块中,可以从基于 CFG 的推理中访问两个交叉注意力图,C^(m,i)_c 和 C^(m,i)_∅。我们计算这两个图的平均值作为锚点,并将其存储在先进先出的特征缓存 F 中。遍历所有交叉注意力块后,F 可以写为:
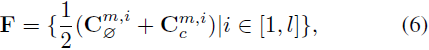
其中,L 代表交叉注意力模块的总数,在 SD-2.1 中 L = 16。
复用缓存的交叉注意力图。在每个忠实度提高阶段的步骤中,在前向传递期间遇到交叉注意力操作时,将其从计算图中省略。相反,缓存的 F.pop(0) 被馈送到后续的计算中。请注意,这种方法不会导致每个步骤中的预测相同,因为 U-Net(Ronneberger等人,2015年)中的残差连接(Hochreiter,1991年;Srivastava等人,2015年;He等人,2016年)允许模型绕过交叉注意力。
6. 实验