目录
Filebeat/Fluentd:负责从各服务器节点上实时收集日志数据,Filebeat轻量级,适合大规模部署,Fluentd功能强大,支持丰富的插件和灵活的过滤规则。
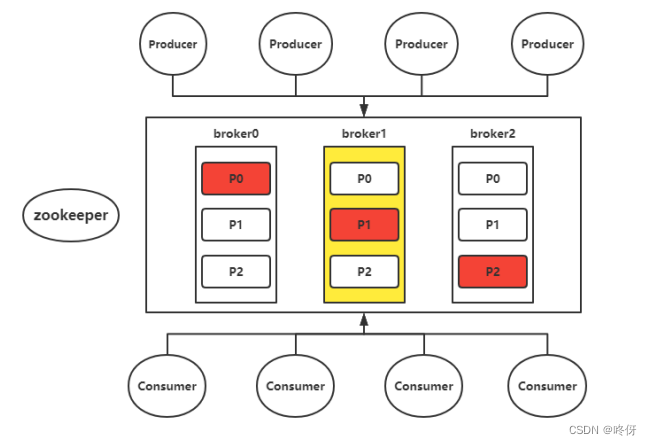
Kafka:作为一个分布式消息队列系统,承担起数据缓冲和中转的角色。日志数据先发送到Kafka集群,一方面可以缓解Logstash或Filebeat的压力,另一方面支持多消费者模型,允许数据被多个下游系统并行消费。此外,Kafka的高吞吐量和持久化特性使得系统在面临大量日志输入时仍能保持稳定。
Logstash:从Kafka集群中消费日志数据,进行必要的数据解析、过滤、转换等预处理操作,然后将结构化后的数据发送到Elasticsearch。
ZooKeeper:在某些场景下,ZooKeeper可以用于管理Kafka集群的元数据,例如Broker注册、Topic的分区分配等,确保Kafka集群的稳定性和一致性。同时,对于Logstash或Kafka Connect这类组件,也可以通过ZooKeeper获取集群配置信息。
Elasticsearch:存储经过处理的日志数据,提供全文搜索、聚合分析等功能,便于后期进行日志分析和故障排查。
Kibana:作为前端展示工具,基于Elasticsearch的数据创建可视化图表和仪表盘,为用户提供友好的日志分析界面。
综合起来,ELFK+Zookeeper+Kafka架构结合了日志收集、处理、存储和分析的全链条,极大地提高了日志管理的效率和用户体验。
在ELFK+Zookeeper+Kafka架构中,日志数据的流转路径通常是这样的: 应用程序日志 -> Filebeat -> Kafka -> (Logstash ->) Elasticsearch -> Kibana
环境准备
| IP地址 | 主机名 | 安装服务 |
| 192.168.83.30 | node1 | JDK-1.18.0 Elasticsearch-6.6.1 |
| 192.168.83.40 | node2 | JDK-1.18.0 Elasticsearch-6.6.1 |
| 192.168.83.50 | logstash | JDK-1.18.0 logstash-6.6.1 httpd |
| 192.168.83.60 | kibana | JDK-1.18.0 kibana-6.6.1 |
| 192.168.83.70 | filebeat | JDK-1.18.0 filebeat-6.6.1 |
| 192.168.83.80 | zk-ka1 | JDK-1.18.0 apache-zookeeper-3.5.7-bin kafka_2.13-2.7.1 |
| 192.168.83.90 | zk-ka2 | JDK-1.18.0 apache-zookeeper-3.5.7-bin kafka_2.13-2.7.1 |
| 192.168.83.100 | zk-ka3 | JDK-1.18.0 apache-zookeeper-3.5.7-bin kafka_2.13-2.7.1 |
一、部署jdk环境
在所有机器上使用脚本安装jdk环境
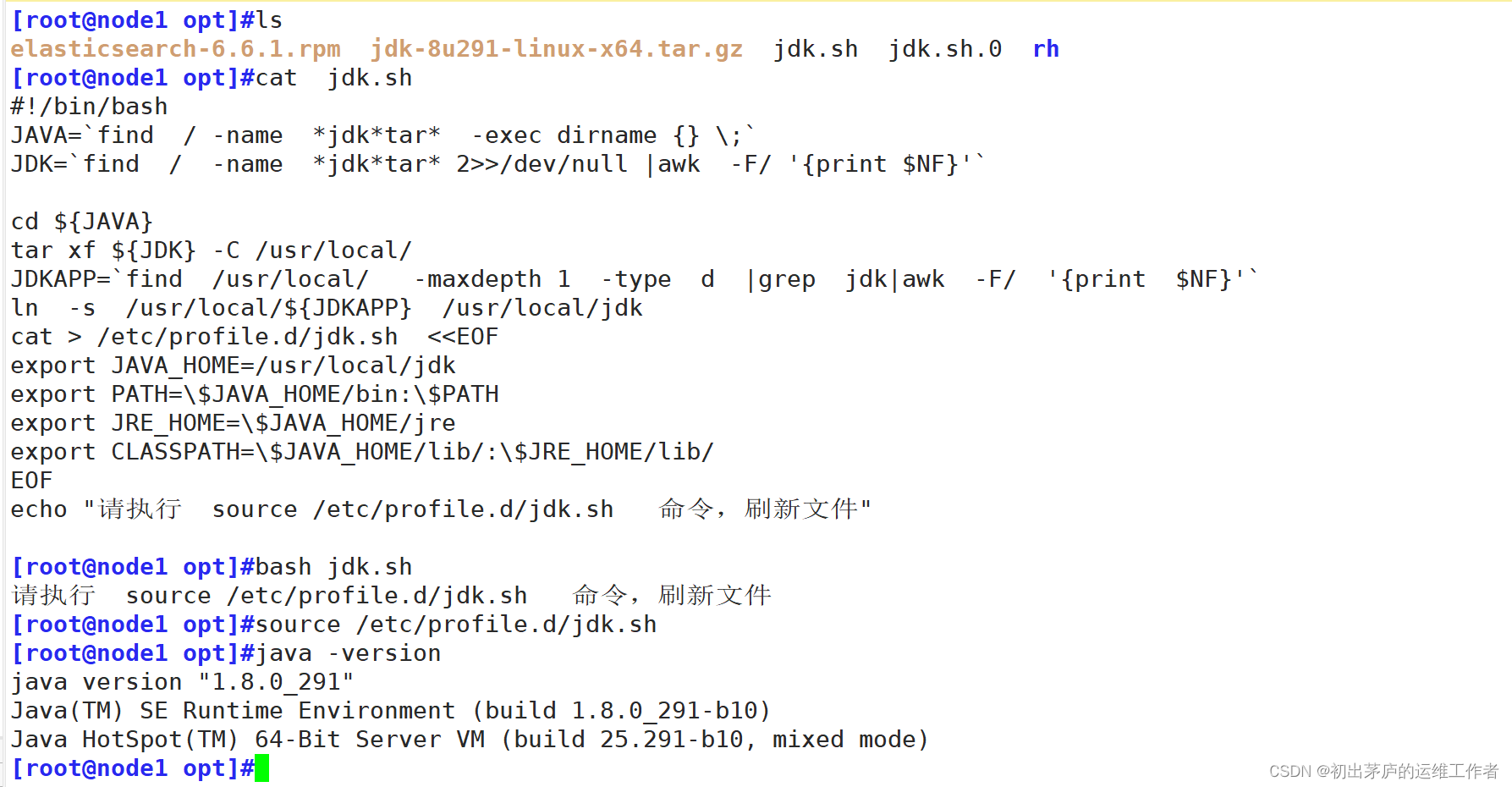
#!/bin/bash
JAVA=`find / -name *jdk*tar* -exec dirname {} \;`
#找到jdk的压缩包所在目录,并将设置为变量JAVA
JDK=`find / -name *jdk*tar* 2>>/dev/null |awk -F/ '{print $NF}'`
#找打jdk压缩包的名字,设置为变量JDK
cd ${JAVA}
tar xf ${JDK} -C /usr/local/
#切换到压缩包所在目录,并指定解压到/usr/local/目录下
JDKAPP=`find /usr/local/ -maxdepth 1 -type d |grep jdk|awk -F/ '{print $NF}'`
#找到解压后的目录名,并设置为变量名JDKAPP
ln -s /usr/local/${JDKAPP} /usr/local/jdk
#做软链接,便于shell环境识别命令
cat > /etc/profile.d/jdk.sh <<EOF
export JAVA_HOME=/usr/local/jdk
export PATH=\$JAVA_HOME/bin:\$PATH
export JRE_HOME=\$JAVA_HOME/jre
export CLASSPATH=\$JAVA_HOME/lib/:\$JRE_HOME/lib/
EOF
#修改环境变量
echo "请执行 source /etc/profile.d/jdk.sh 命令,刷新文件小结
'-----------------------------脚本安装JDK-----------------------------'
[root@node1 opt]#cat jdk.sh
#!/bin/bash
JAVA=`find / -name *jdk*tar* -exec dirname {} \;`
JDK=`find / -name *jdk*tar* 2>>/dev/null |awk -F/ '{print $NF}'`
cd ${JAVA}
tar xf ${JDK} -C /usr/local/
JDKAPP=`find /usr/local/ -maxdepth 1 -type d |grep jdk|awk -F/ '{print $NF}'`
ln -s /usr/local/${JDKAPP} /usr/local/jdk
cat > /etc/profile.d/jdk.sh <<EOF
export JAVA_HOME=/usr/local/jdk
export PATH=\$JAVA_HOME/bin:\$PATH
export JRE_HOME=\$JAVA_HOME/jre
export CLASSPATH=\$JAVA_HOME/lib/:\$JRE_HOME/lib/
EOF
echo "请执行 source /etc/profile.d/jdk.sh 命令,刷新文件"
[root@node1 opt]#bash jdk.sh
[root@node1 opt]#source /etc/profile.d/jdk.sh二、搭建Elasticsearch
环境准备
| IP地址 | 主机名 | 安装服务 |
| 192.168.83.30 | node1 | JDK-1.18.0 Elasticsearch-6.6.1 |
| 192.168.83.40 | node2 | JDK-1.18.0 Elasticsearch-6.6.1 |
修改配置文件
cluster.name: elk-cluster
#设置Elasticsearch集群的名称为 "elk-cluster"。
#这意味着所有带有相同cluster.name配置的Elasticsearch节点将会尝试加入同一个集群。
node.name: node1
#指定当前节点的名字为 "node1",进行区分,便于集群内部管理和监控集群中的各个节点。
'另一台服务器一般指定为node2。也可以设置IP地址'
path.data: /data/elk_data
#设置Elasticsearch数据存储路径,这是Elasticsearch存放索引数据的地方。
'需要自己手动创建,并修改属主与属组'
path.logs: /var/log/elasticsearch
#设置Elasticsearch日志文件的存放路径,Elasticsearch的所有日志都会写入到这个目录下的文件
bootstrap.memory_lock: false
#设置为 "false" 表示不锁定内存。
#若设为 true,Elasticsearch将尝试锁定全部分配给它的内存,防止在操作系统层面被交换到磁盘。
#在生产环境中,通常建议开启内存锁定以获得更好的性能和稳定性,但需要有足够的权限,并确保物理内存充足。
network.host: 0.0.0.0
#设置为 "0.0.0.0",表示Elasticsearch节点监听所有可用网络接口上的连接请求,对外提供服务。
http.port: 9200
#设置HTTP协议的服务端口为 "9200"
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
#设置Elasticsearch集群发现机制的初始节点列表,这里包含了 "node1" 和 "node2" 两个节点地址。
#集群中的节点通过互相ping这些地址来发现彼此并组建集群。
#在启动过程中,节点会尝试联系这个列表中的其他节点来参与集群。
启动服务

登录web界面查看信息
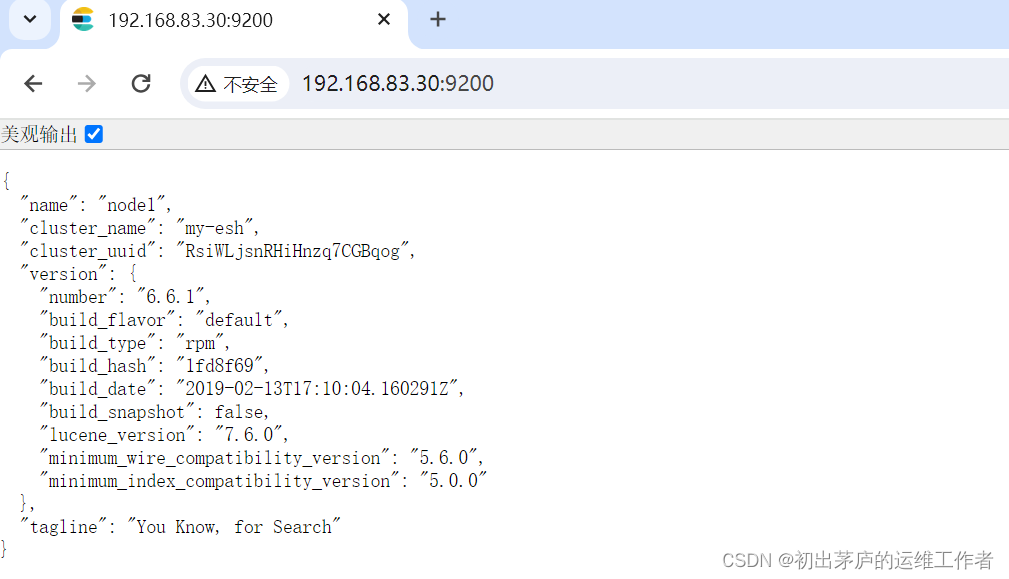
小结
'-----------------------------安装elasticsearch-----------------------------'
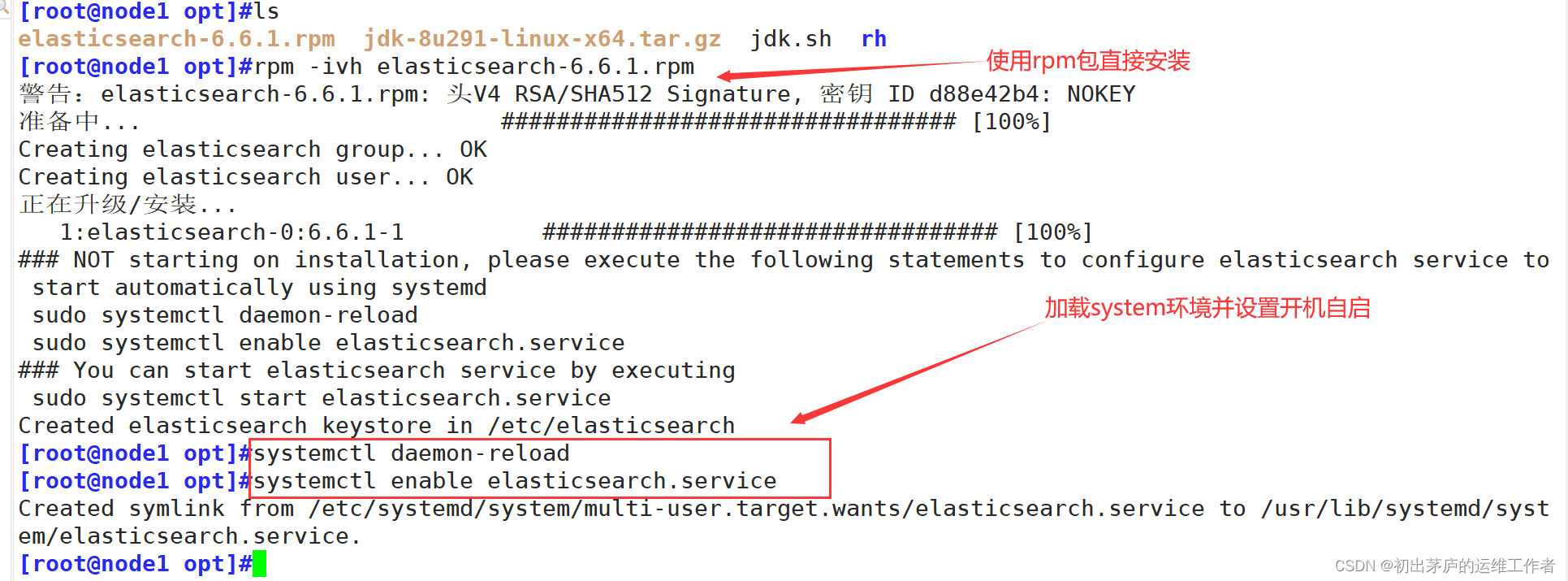
[root@node1 opt]#ls
elasticsearch-6.6.1.rpm jdk-8u291-linux-x64.tar.gz jdk.sh
[root@node1 opt]#rpm -ivh elasticsearch-6.6.1.rpm
[root@node1 opt]#systemctl daemon-reload
[root@node1 opt]#systemctl enable elasticsearch.service
'-----------------------------修改配置文件-----------------------------'
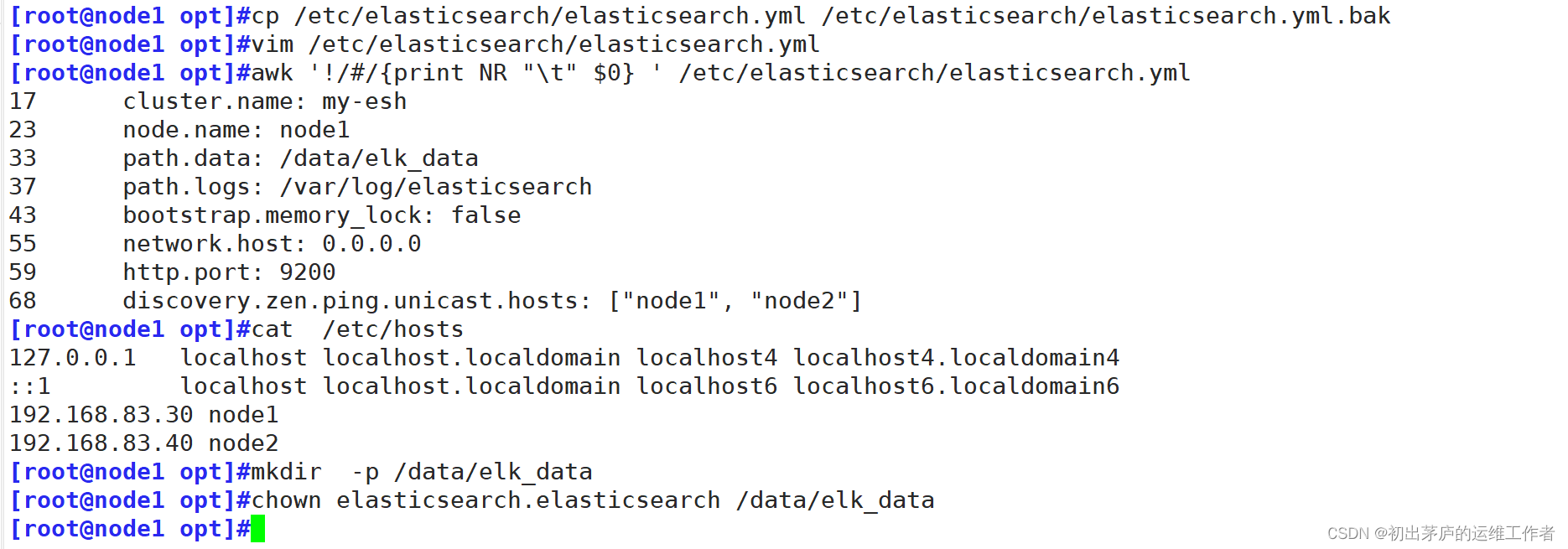
[root@node1 opt]#cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
[root@node1 opt]#vim /etc/elasticsearch/elasticsearch.yml
17 cluster.name: my-esh
23 node.name: node1
33 path.data: /data/elk_data
37 path.logs: /var/log/elasticsearch
43 bootstrap.memory_lock: false
55 network.host: 0.0.0.0
59 http.port: 9200
68 discovery.zen.ping.unicast.hosts: ["node1", "node2"]
[root@node1 opt]#cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.83.30 node1
192.168.83.40 node2
[root@node1 opt]#mkdir -p /data/elk_data
[root@node1 opt]#chown elasticsearch.elasticsearch /data/elk_data三、搭建logstash
| IP地址 | 主机名 | 安装服务 |
| 192.168.83.50 | logstash | JDK-1.18.0 logstash-6.6.1 httpd |
测试服务情况

收到返回信息后在elasticsearch服务器上查看

小结
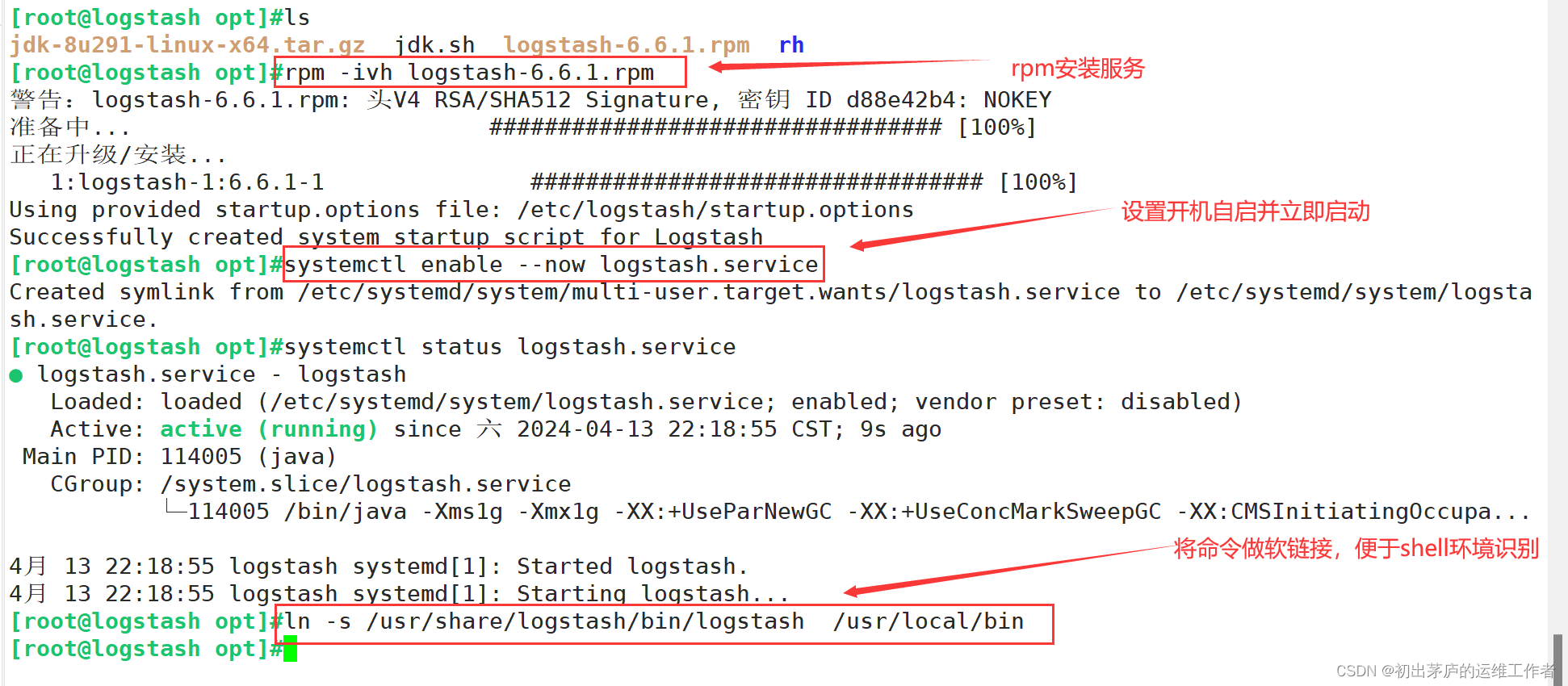
'-----------------------------安装logstash服务-----------------------------'
[root@logstash opt]#rpm -ivh logstash-6.6.1.rpm
[root@logstash opt]#systemctl enable --now logstash.service
[root@logstash opt]#ln -s /usr/share/logstash/bin/logstash /usr/local/bin
'-----------------------------测试logstash服务-----------------------------'
[root@logstash opt]#logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.83.30:9200"] } }'
www.baidu.com
...........四、搭建kibana服务
环境准备
| IP地址 | 主机名 | 安装服务 |
| 192.168.83.60 | kibana | JDK-1.18.0 kibana-6.6.1 |
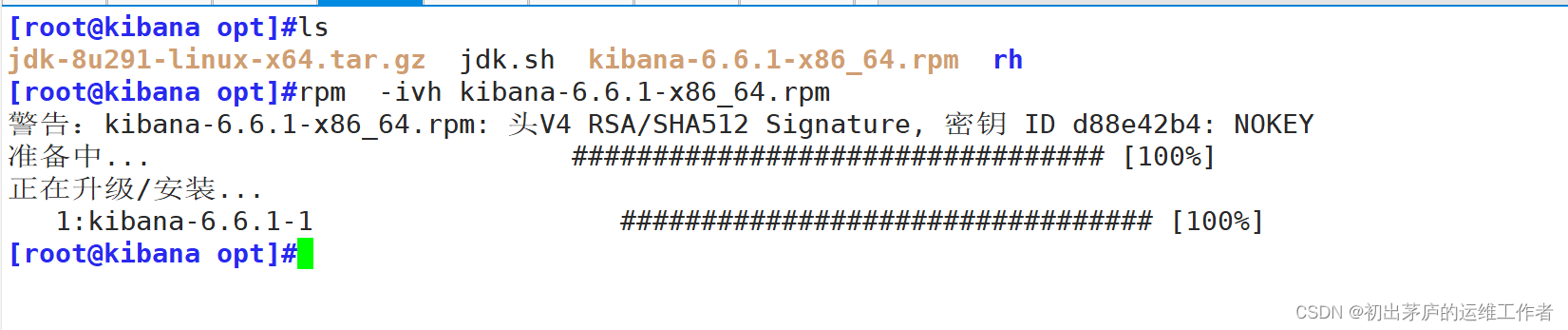
使用rpm包直接安装
修改配置文件
server.port: 5601
#此行配置了Kibana服务监听的端口号为5601
server.host: "0.0.0.0"
#该配置指示Kibana服务器绑定到所有可用的网络接口
elasticsearch.hosts: ["http://192.168.83.30:9200"]
#配置了Kibana连接的Elasticsearch集群地址和端口
kibana.index: ".kibana"
#Kibana使用此配置来指定在Elasticsearch中存储其自身配置和状态的索引名称验证kibana服务
在logstash服务器上开启httpd服务:systemctl start httpd
创建收集httpd服务日志信息的配置文件

#input字段
#Logstash使用两个file输入插件,分别配置了两个日志文件路径
'第一个file插件配置了Apache服务器的访问日志路径/etc/httpd/logs/access_log,
并将日志类型标记为"type"字段的"access"。'
'第二个file插件配置了Apache服务器的错误日志路径/etc/httpd/logs/error_log,并将日志类型标记为"type"字段的"error"'
'start_position => "beginning" 表示从日志文件的开始位置读取数据'
#这对于初次启动或重新配置Logstash时很有用,可以确保从头开始处理日志。
#output字段
'根据[type]字段的值,Logstash通过elasticsearch输出插件将处理后的数据发送到Elasticsearch集群'
'当[type]字段等于"access"时,数据将被发送到Elasticsearch,并按日期格式创建索引,
例如apache_access-2024.04.14,每天都会创建一个新的索引。'
'当[type]字段等于"error"时,数据同样被发送到相同的Elasticsearch集群
但是存储在按日期格式命名的另一个索引中,例如apache_error-2024.04.14'创建索引访问
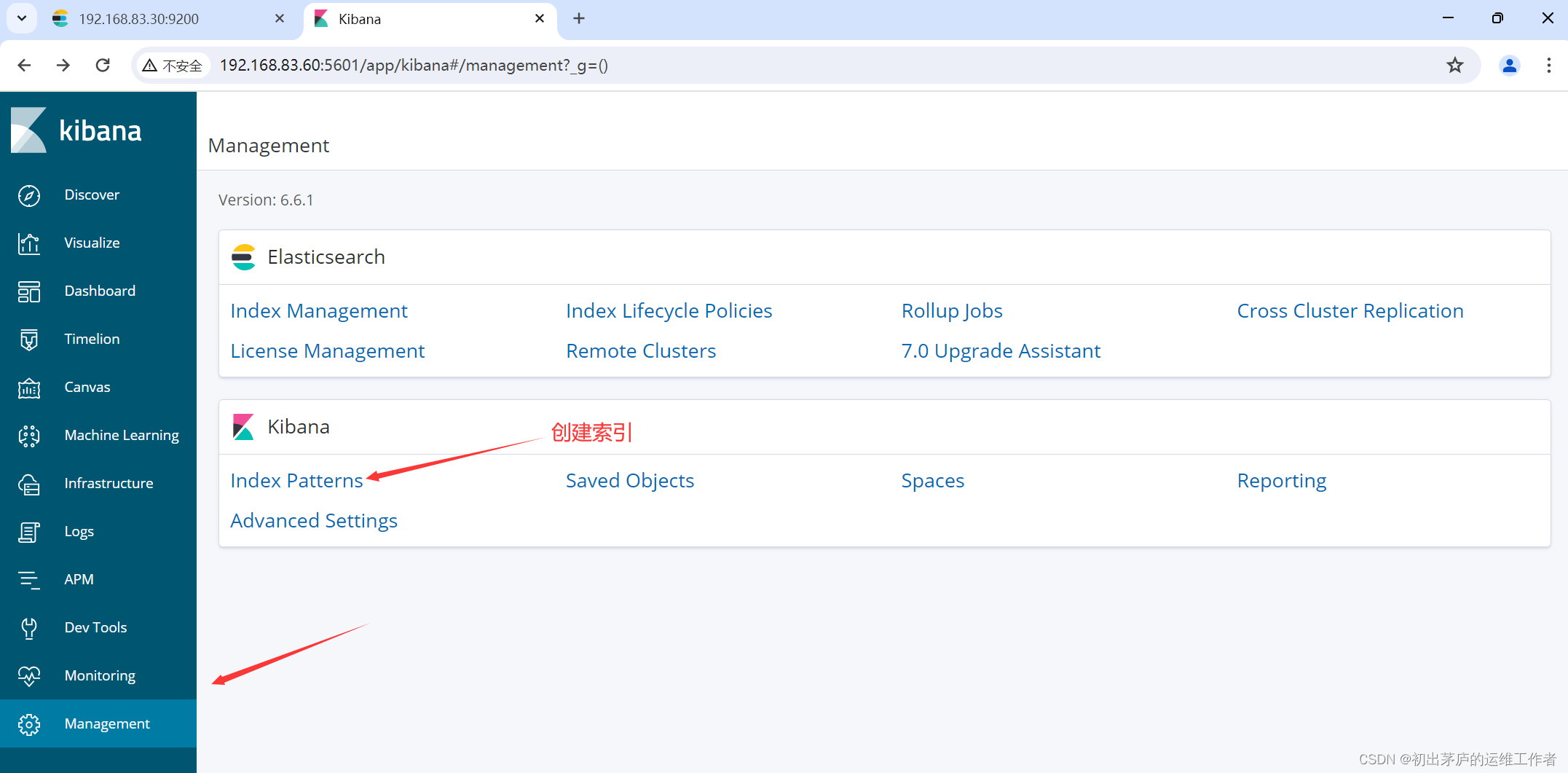
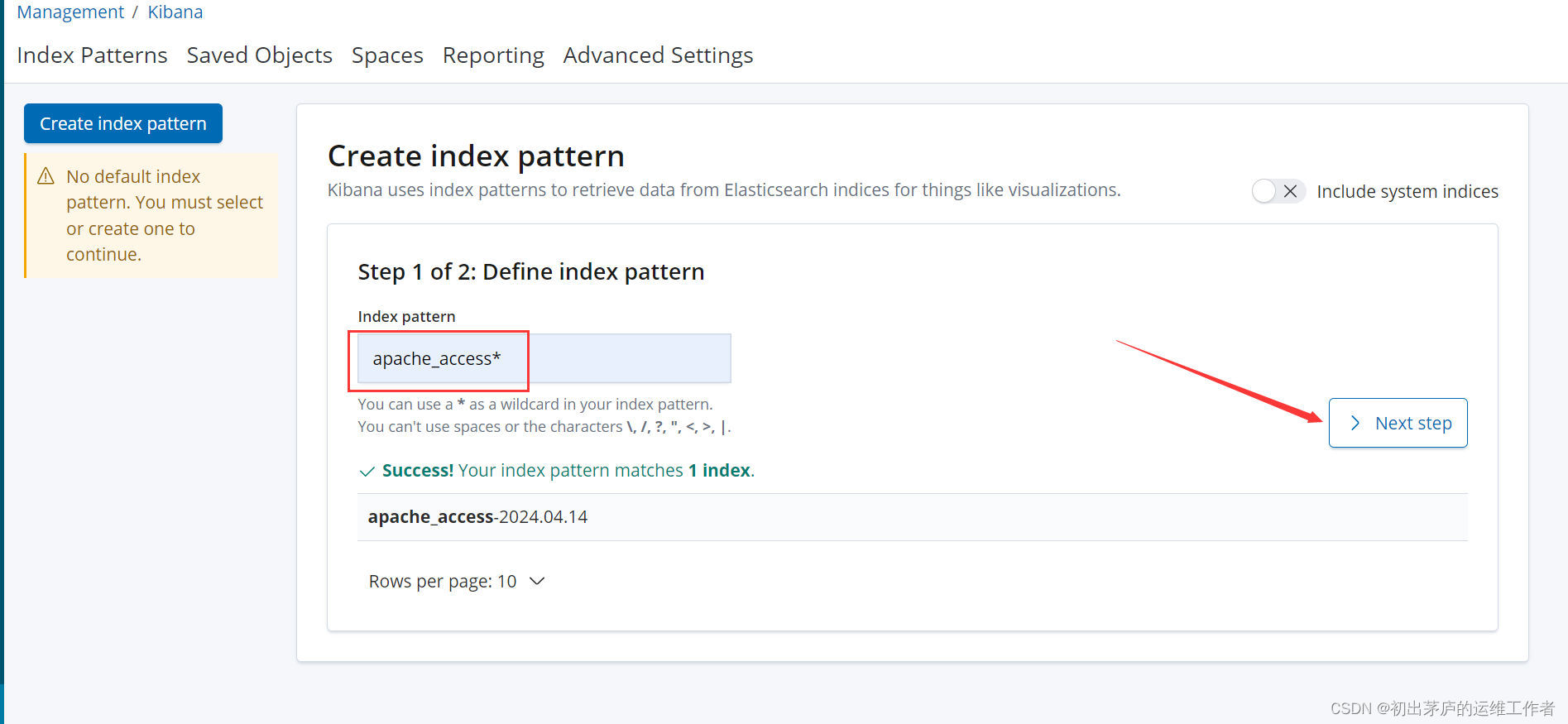

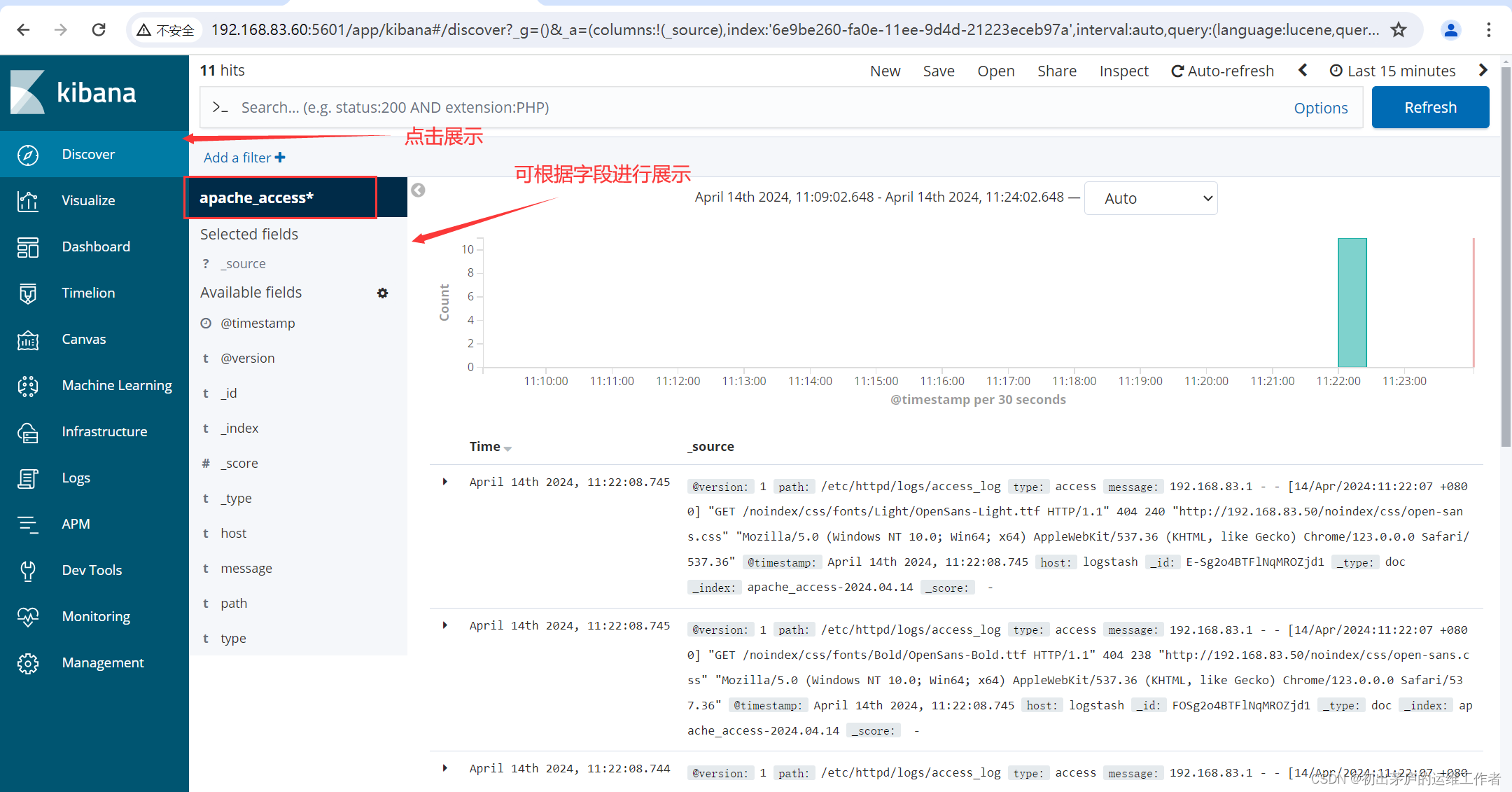
小结
'-----------------------------安装kibana服务-----------------------------'
[root@kibana opt]#rpm -ivh kibana-6.6.1-x86_64.rpm
警告:kibana-6.6.1-x86_64.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:kibana-6.6.1-1 ################################# [100%]
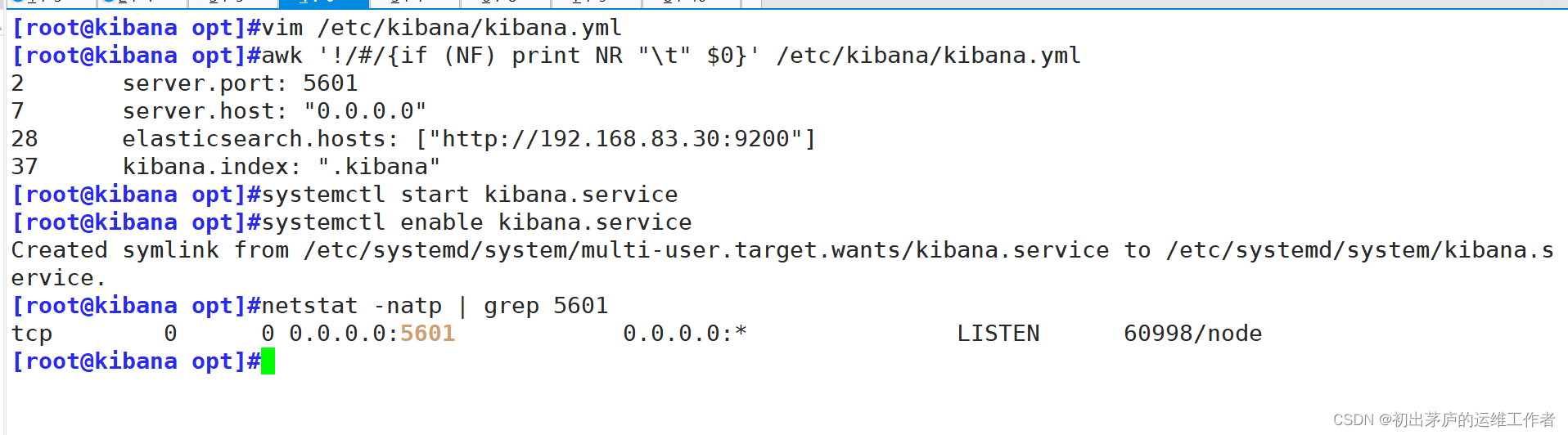
[root@kibana opt]#vim /etc/kibana/kibana.yml
第2行 server.port: 5601
第7行 server.host: "0.0.0.0"
第28行 elasticsearch.hosts: ["http://192.168.83.30:9200"]
第37行 kibana.index: ".kibana"
[root@kibana opt]#systemctl enable --now kibana.service
[root@kibana opt]#netstat -natp | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 60998/node
#浏览192.168.83.50:5601进行访问测试五、搭建filebeat服务
| IP地址 | 主机名 | 安装服务 |
| 192.168.83.70 | filebeat | JDK-1.18.0 filebeat-6.6.1 |

修改配置文件
21 - type: log
#定义了一个名为"log"类型的输入处理器,这是一种用于从日志文件中收集数据的模块
24 enabled: true
#启用该模块
27 paths:
28 - /var/log/*.log
29 - /var/log/messages
#指定了需要监控的日志文件路径
46 fields:
47 server_name: fb
48 log_type: log
49 server_id: 192.168.83.70
#这些字段会被附加到从日志文件中提取的每条事件上。
152 #output.elasticsearch:
153 # Array of hosts to connect to.
154 # hosts: ["localhost:9200"]
#将输出到elasticsearch模块的信息注释掉
165 output.logstash:
167 hosts: ["192.168.83.50:5044"]
#将信息输出到logstash服务器上,并指定服务器地址与端口号
在logstash服务器上添加接收filebeat服务器传输的信息的配置文件

input {
beats {
port => "5044"
}
}
#定义logstash的5044端口,接收来自beats工具的所有数据
output {
elasticsearch {
hosts => ["192.168.83.30:9200"]
index => "%{[fields][server_name]}-%{+YYYY.MM.dd}"
}
}
#将接收的数据传输到elasticsearch服务器上
#并将索引名称定义为filebeat配置文件中,事件字段fields中server_name的值,并以时间结尾
在另一个终端上查看端口号是否开启

确认logstash服务器的5044端口还在监听状态后,在filebeat服务器上启动filebeat服务并加载配置文件
filebeat -e -c /etc/filebeat/filebeat.yml

登录kibana服务web界面

小结
'-----------------------------安装启动filebeat服务-----------------------------'
[root@filebeat opt]#rpm -ivh filebeat-6.6.1-x86_64.rpm
[root@filebeat opt]#cp /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml_bak
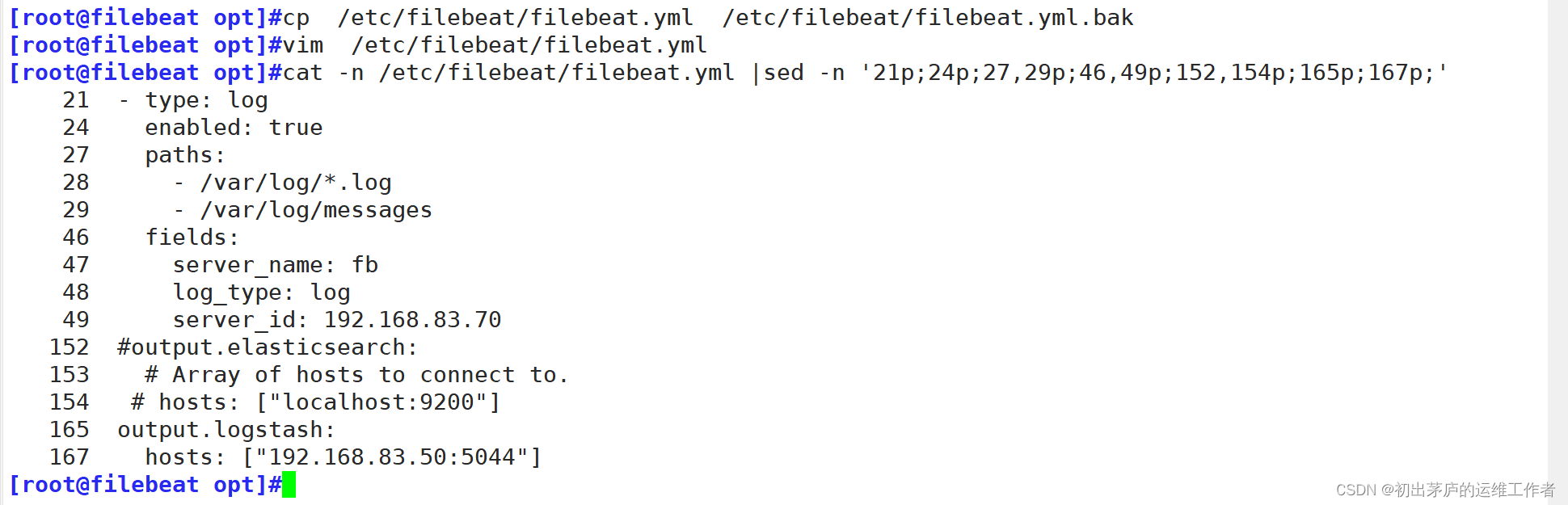
[root@filebeat opt]#vim /etc/filebeat/filebeat.yml
21 - type: log
24 enabled: true
27 paths:
28 - /var/log/*.log
29 - /var/log/messages
46 fields:
47 server_name: fb
48 log_type: log
49 server_id: 192.168.83.70
152 #output.elasticsearch:
153 # Array of hosts to connect to.
154 # hosts: ["localhost:9200"]
165 output.logstash:
167 hosts: ["192.168.83.50:5044"]
[root@filebeat opt]#filebeat -e -c /etc/filebeat/filebeat.yml
.......
'-----------------------------添加logstash服务配置文件-----------------------------'
[root@logstash ~]#vim /etc/logstash/conf.d/fb.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.83.30:9200"]
index => "%{[fields][server_name]}-%{+YYYY.MM.dd}"
}
}
[root@logstash ~]#logstash -f /etc/logstash/conf.d/fb.conf
............
六、搭建zookeeper与kafka服务
| IP地址 | 主机名 | 安装服务 |
| 192.168.83.80 | zk-ka1 | JDK-1.18.0 apache-zookeeper-3.5.7-bin kafka_2.13-2.7.1 |
| 192.168.83.90 | zk-ka2 | JDK-1.18.0 apache-zookeeper-3.5.7-bin kafka_2.13-2.7.1 |
| 192.168.83.100 | zk-ka3 | JDK-1.18.0 apache-zookeeper-3.5.7-bin kafka_2.13-2.7.1 |
在三台机器上安装zookeeper服务与Kafka服务
修改zookeeper服务配置文件
三台服务器配置文件相同
tickTime=2000
#基本时间单元,所有超时和心跳时间间隔都以tickTime的倍数来表示。这里设置为2000毫秒,即2秒
initLimit=10
#初始化连接时的最大时间限制,单位为tickTime。
#当follower启动并试图连接leader时,follower在10*2秒(即20秒)内必须完成与leader初始同步
syncLimit=5
#leader与follower之间发送消息的同步确认的最大时间限制,同样单位为tickTime。
#这意味着follower必须在5*2秒(即10秒)内响应leader的心跳或同步请求。
dataDir=/usr/local/zookeeper-3.5.7/data
#ZooKeeper存放持久化数据的目录,如事务日志、快照等。需要手动创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs
#ZooKeeper专门存放事务日志的目录,分离数据和日志存储可以优化磁盘I/O性能。需要手动创建
clientPort=2181
#ZooKeeper服务监听客户端连接的端口号,客户端通过这个端口与ZooKeeper集群进行通信。
server.1=192.168.83.70:3188:3288
server.2=192.168.83.80:3188:3288
server.3=192.168.83.90:3188:3288
#这三行配置描述了ZooKeeper集群中的三个服务器节点。格式为server.id=hostname:port1:port2
#其中:
#id(1、2、3)是集群中服务器的唯一标识。
#hostname(192.168.83.70、192.168.83.80、192.168.83.90)是服务器的IP地址。
#port1(3188)是集群内部通信的端口,用于follower和observer与其他服务器通信。
#port2(3288)是选举leader时服务器之间通信的端口。修改kafka服务配置文件
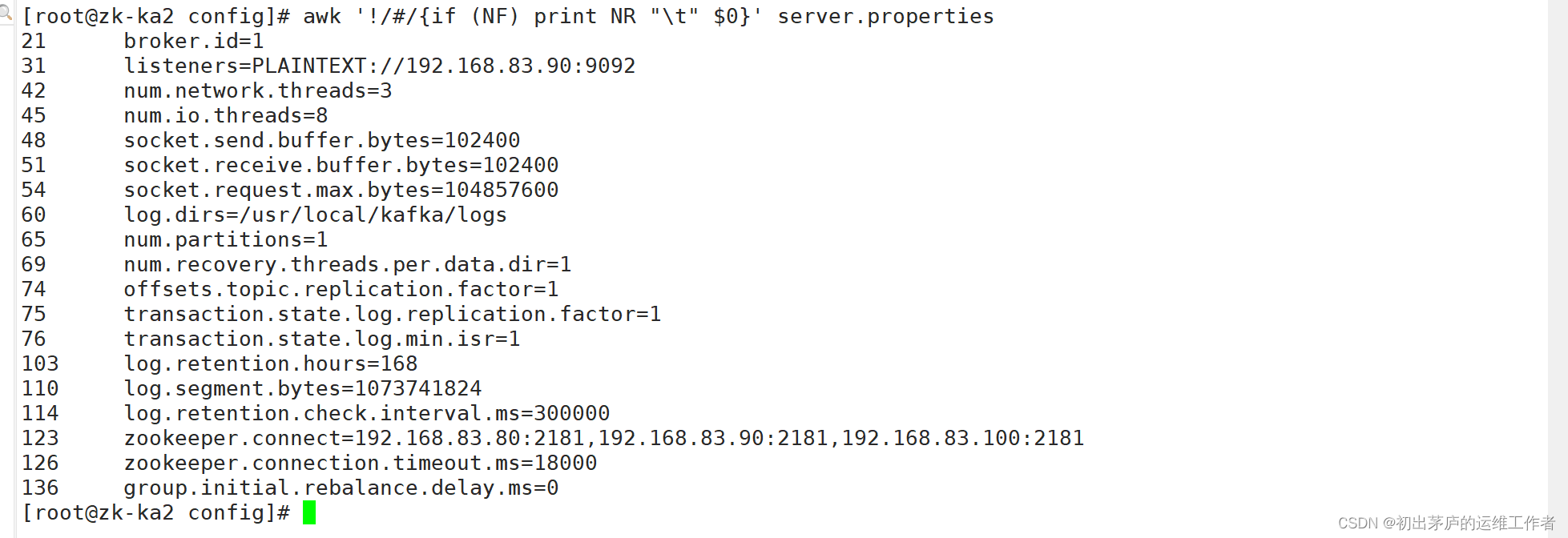

三台服务器的kafka配置文件中只有broker.id、listeners字段值不同
broker.id=0
#定义当前Kafka Broker的唯一标识ID。在集群中,每个Broker的ID都应是唯一的。
#其它两台服务器设置为1,2
listeners=PLAINTEXT://192.168.83.70:9092
#指定Broker监听客户端连接的地址和端口,这里是使用PLAINTEXT协议
#三台服务器分别监听本机的IP地址
num.network.threads=3
#设置网络IO线程数量,用于处理网络请求,比如接收生产者的消息和响应消费者的请求。
num.io.threads=8
#设置磁盘IO线程数量,用于处理磁盘读写操作,如写入日志文件和从磁盘读取消息。
socket.send.buffer.bytes=102400 和 socket.receive.buffer.bytes=102400
#分别设置Socket发送和接收缓冲区的大小(单位为字节),影响TCP层的数据传输效率。
socket.request.max.bytes=104857600
#设置单个请求允许的最大字节数,超过这个大小的请求会被拒绝。
log.dirs=/usr/local/kafka/logs
#设置Kafka日志数据的存储目录,即Kafka消息持久化的路径。
num.partitions=1
#默认每个主题的分区数量,这里设定为每个主题初始化时只有一个分区。
num.recovery.threads.per.data.dir=1
#指定每个数据目录(日志目录)下用于恢复数据的线程数量。
offsets.topic.replication.factor=1 和 transaction.state.log.replication.factor=1
#这两个配置分别指定了Kafka内部主题(__consumer_offsets)和事务状态日志的复制因子,
#这里均为1,表示没有数据复制,所有数据仅在一个Broker上存储。
transaction.state.log.min.isr=1
#设置事务状态日志的最小ISR大小,这里为1,意味着只要有一个副本是同步的,就满足要求。
log.retention.hours=168
#设置日志保留时间,这里是168小时(7天),超过这个时间的数据将被删除。
log.segment.bytes=1073741824
#每个日志分段的大小,当达到这个阈值时,Kafka会创建新的日志分段。
log.retention.check.interval.ms=300000
#日志清理检查间隔,每隔300000毫秒(5分钟)检查一次日志是否需要删除。
zookeeper.connect=192.168.83.70:2181,192.168.83.80:2181,192.168.83.90:2181
#设置连接ZooKeeper集群的地址和端口,此处配置了一个由三个节点构成的ZooKeeper集群。
zookeeper.connection.timeout.ms=18000
#ZooKeeper连接超时时间,设置为18000毫秒(18秒)。
group.initial.rebalance.delay.ms=0
#消费者组在启动时的初始再平衡延迟时间,设置为0表示消费者在加入组时立即开始再平衡。创建zookeeper启动脚本,三台服务器脚本文件相同

#!/bin/bash
声明该脚本使用bash shell进行解释执行。
#chkconfig:2345 20 90
这行注释是针对Red Hat家族(如CentOS、Fedora等)Linux发行版的chkconfig工具的指令,
#用于在不同运行级别(2、3、4、5)下设置服务的启动优先级(20,较高)和停止优先级(90,较低)。
#description:Zookeeper Service Control Script
描述脚本的功能,即ZooKeeper服务的控制脚本。
ZK_HOME='/usr/local/zookeeper-3.5.7'
#定义ZooKeeper的安装目录,便于在脚本中引用。
脚本主体部分使用case $1 in结构,根据传入的第一个参数($1)执行相应的操作:
start:启动ZooKeeper服务,执行$ZK_HOME/bin/zkServer.sh start命令。
stop:停止ZooKeeper服务,执行$ZK_HOME/bin/zkServer.sh stop命令。
restart:重启ZooKeeper服务,执行$ZK_HOME/bin/zkServer.sh restart命令。
status:查看ZooKeeper服务的状态,执行$ZK_HOME/bin/zkServer.sh status命令。
*:如果传入的参数不在上述情况中,脚本将打印正确的使用方式。
chmod +x /etc/init.d/zookeeper #添加执行权限
chkconfig --add zookeeper #设置开机自动进行管理启动服务

创建kafka启动脚本,三台服务器脚本文件相同,并依次启动
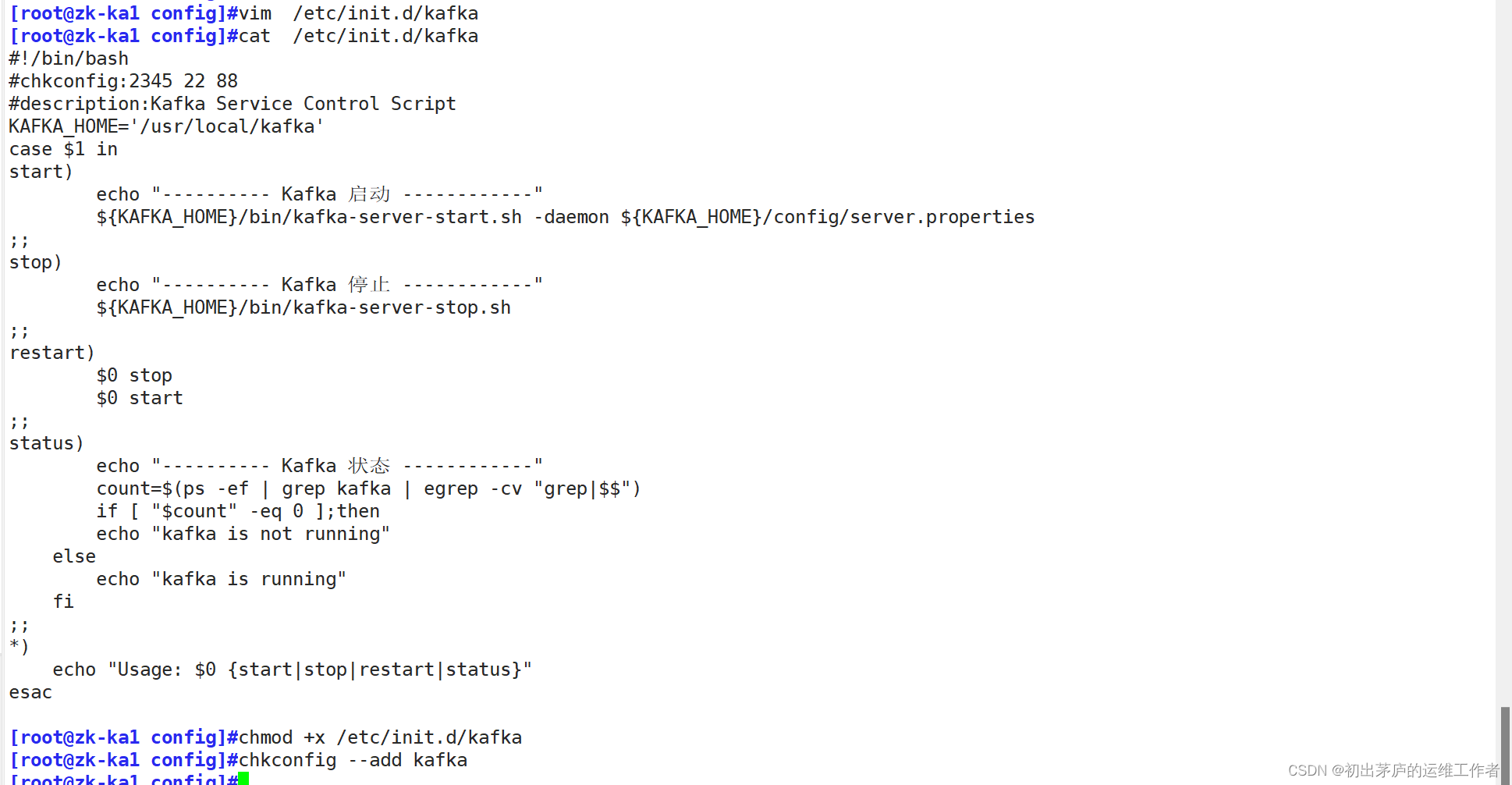
#!/bin/bash:定义脚本使用的解释器为Bash Shell。
#chkconfig:2345 22 88
#这是针对Red Hat系列Linux(如CentOS、Fedora等)的 chkconfig 工具的注释行,
#用来设置服务在运行级别2、3、4、5下的启动优先级(22)和关闭优先级(88)。
#description:Kafka Service Control Script
#描述脚本功能,即用于控制Apache Kafka服务的启动、停止、重启和查看状态。
KAFKA_HOME='/usr/local/kafka'
#定义Kafka的安装目录。
case $1 in
#根据用户传入的第一个参数($1)执行不同的操作。
start
#启动Kafka服务,
#通过${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties命令执行。
#-daemon选项表示以守护进程方式运行Kafka服务器,server.properties是Kafka的配置文件。
stop
#停止Kafka服务,执行${KAFKA_HOME}/bin/kafka-server-stop.sh命令。
restart
#先调用 $0 stop 停止服务,然后调用$0start重新启动服务。
status
#检查Kafka服务是否正在运行。
#通过ps -ef | grep kafka | egrep -cv "grep|$$"命令统计Kafka进程的数量,
#如果不为0,则说明Kafka正在运行;否则,Kafka未运行。
*
#如果传入的参数不在上述情况中,脚本将打印正确的使用方式
小结
'-----------------------------安装zookeeper服务--------------------------------'
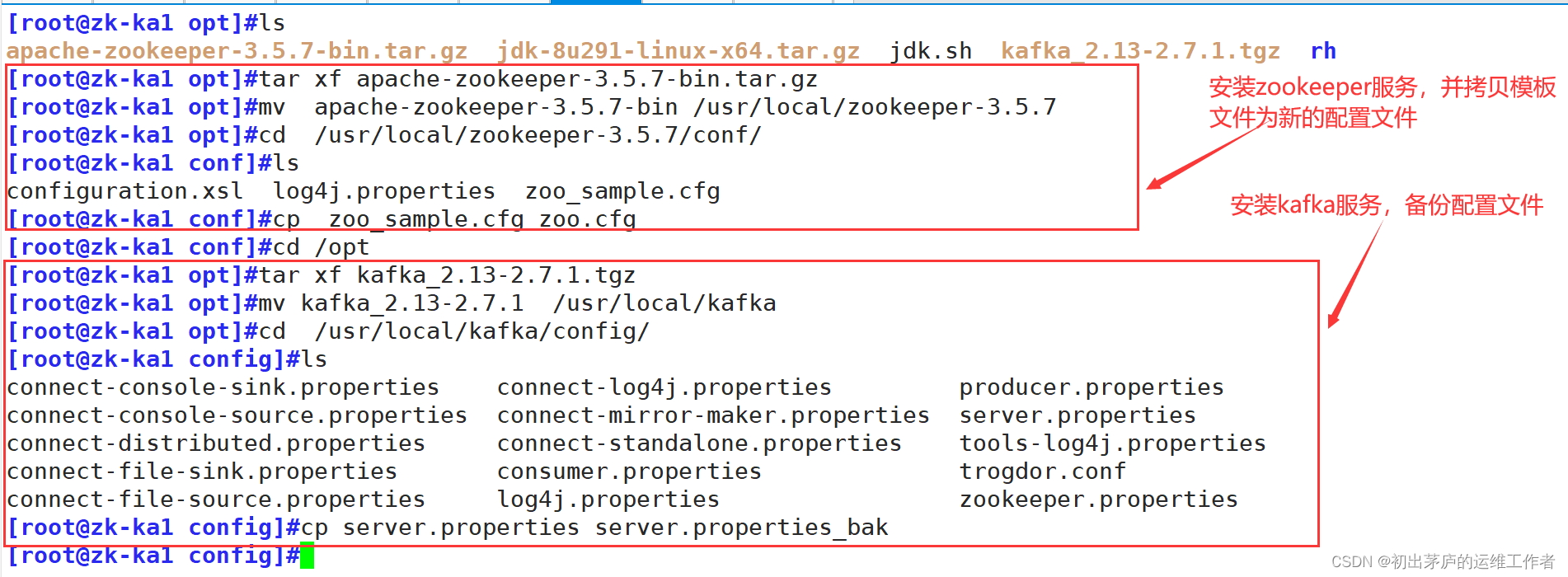
[root@kibana opt]#tar xf apache-zookeeper-3.5.7-bin.tar.gz
[root@kibana opt]#mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
[root@kibana opt]#cd /usr/local/zookeeper-3.5.7/conf/
[root@kibana opt]#cp zoo_sample.cfg zoo.cfg
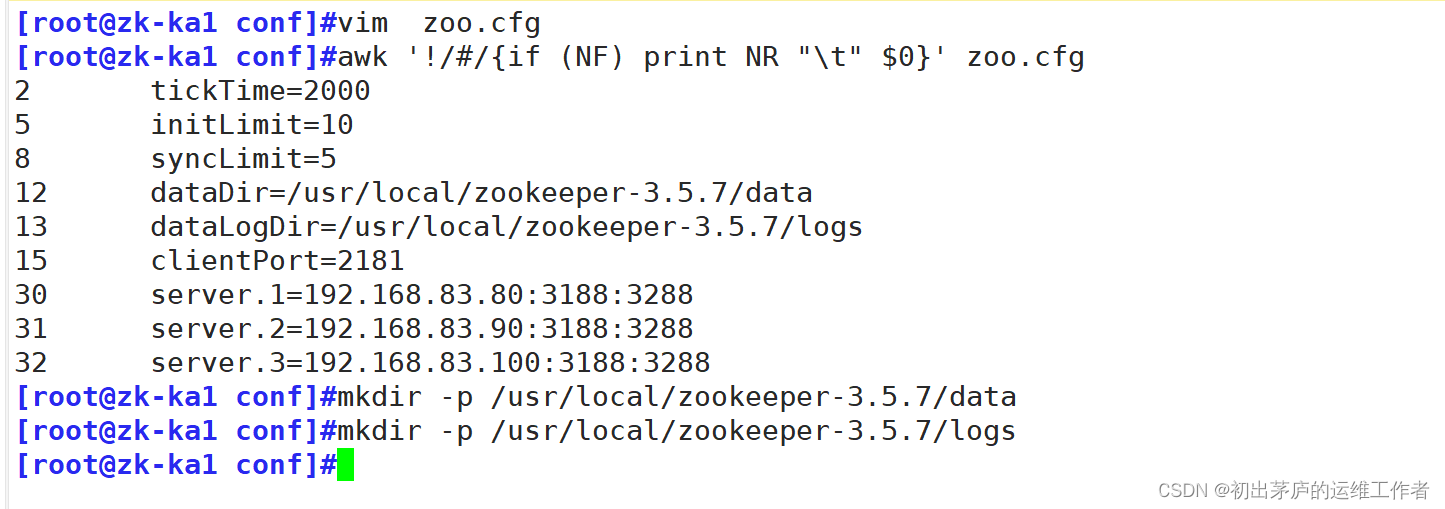
[root@kibana opt]#vim zoo.cfg
2 tickTime=2000
5 initLimit=10
8 syncLimit=5
12 dataDir=/usr/local/zookeeper-3.5.7/data
13 dataLogDir=/usr/local/zookeeper-3.5.7/logs
15 clientPort=2181
30 server.1=192.168.83.80:3188:3288
31 server.2=192.168.83.90:3188:3288
32 server.3=192.168.83.100:3188:3288
[root@kibana opt]#mkdif -p /usr/local/zookeeper-3.5.7/data
[root@kibana opt]#mkdif -p /usr/local/zookeeper-3.5.7/logs
'---------------------------创建zookeeper服务启动脚本------------------------------'
[root@kibana opt]#vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
[root@kibana opt]#chmod +x /etc/init.d/zookeeper
[root@kibana opt]#chkconfig --add zookeeper
[root@kibana opt]#service zookeeper start
'-----------------------------安装zookeeper服务--------------------------------'
[root@kibana opt]#tar xf kafka_2.13-2.7.1.tgz
[root@kibana opt]#mv kafka_2.13-2.7.1 /usr/local/kafka
[root@kibana opt]#cd /usr/local/kafka/config/
[root@kibana opt]#cp server.properties server.properties_bak
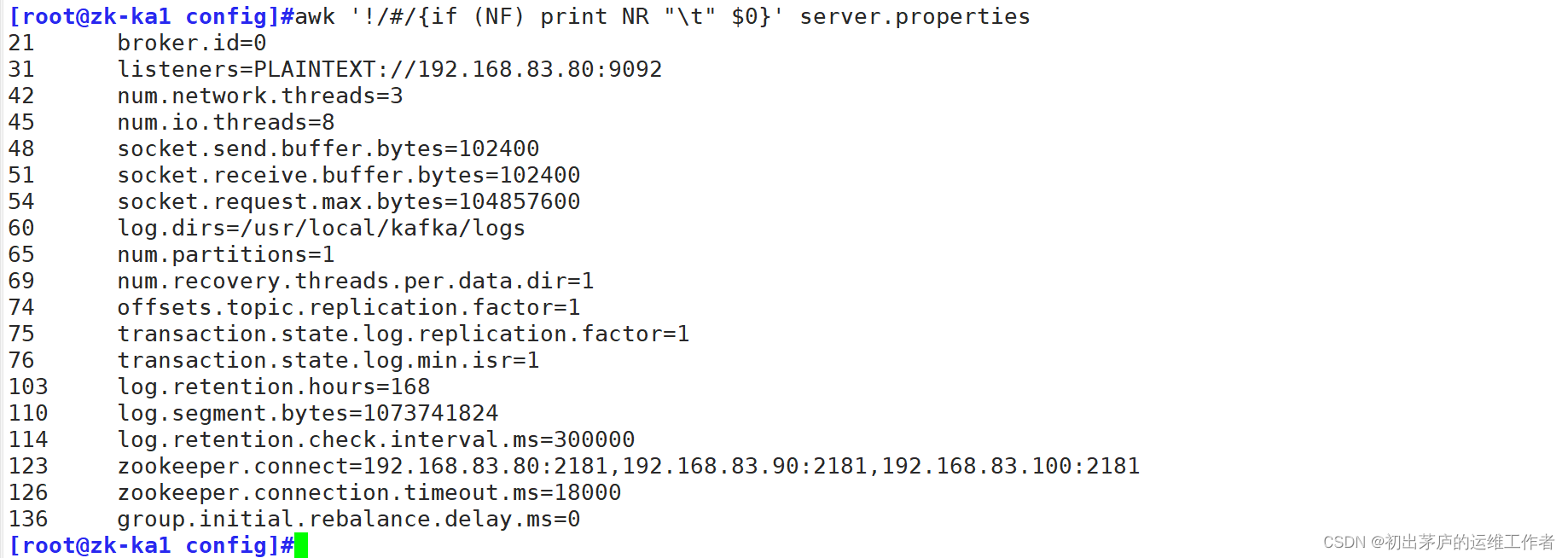
[root@kibana opt]#vim server.properties
21 broker.id=0 #每台服务器的唯一标识不一样
31 listeners=PLAINTEXT://192.168.83.80:9092 #监听本机的IP地址的9092的端口号
42 num.network.threads=3
45 num.io.threads=8
48 socket.send.buffer.bytes=102400
51 socket.receive.buffer.bytes=102400
54 socket.request.max.bytes=104857600
60 log.dirs=/usr/local/kafka/logs
65 num.partitions=1
69 num.recovery.threads.per.data.dir=1
74 offsets.topic.replication.factor=1
75 transaction.state.log.replication.factor=1
76 transaction.state.log.min.isr=1
103 log.retention.hours=168
110 log.segment.bytes=1073741824
114 log.retention.check.interval.ms=300000
123 zookeeper.connect=192.168.83.80:2181,192.168.83.90:2181,192.168.83.100:2181
126 zookeeper.connection.timeout.ms=18000
136 group.initial.rebalance.delay.ms=0
'---------------------------创建kafka服务启动脚本------------------------------'
[root@kibana opt]#vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
[root@kibana opt]#chmod +x /etc/init.d/kafka
[root@kibana opt]#chkconfig --add kafka
[root@kibana opt]#service kafka start
七、部署ELFK+zookeeper+kafka
(一)修改filebeat服务器配置文件
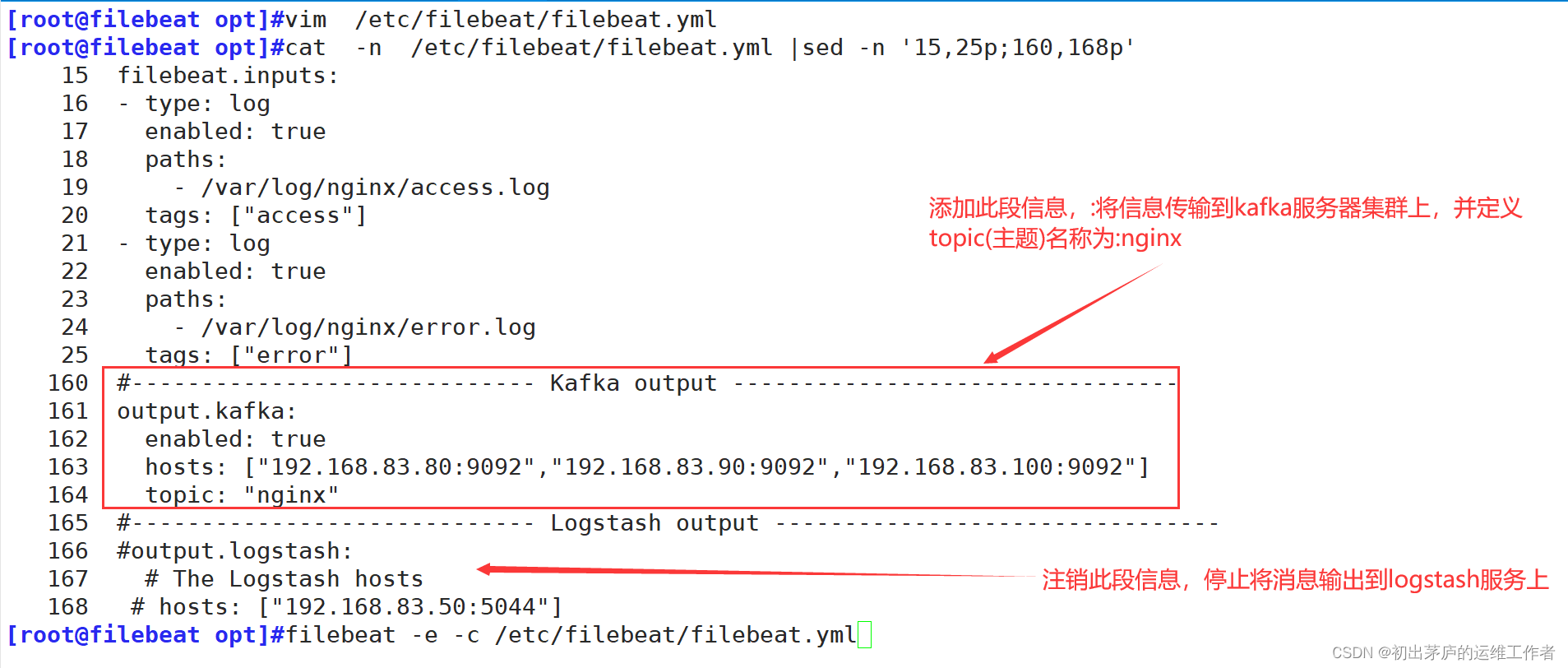
filebeat.inputs
#定义了Filebeat应该监控哪些日志文件,并接收日志信息。
- type: log
#定义输入类型为日志文件。
enabled: true
#启用此输入源
paths:
#指定日志文件的路径列表,指定/var/log/nginx/access_log,表示监控nginx服务器的访问日志
tags: ["access"]
#给收集到的数据打上标签,这里打上了"access"标签,可以在后续处理和分析时用于筛选或分类
'第二段信息含义与第一段一致'输入:filebeat -e -c /etc/filebeat/filebeat.yml 加载配置文件
(二)在logstash服务器上添加配置文件
input 字段:
kafka {
#表示从Kafka集群中读取数据:
bootstrap_servers => "192.168.10.17:9092,192.168.10.21:9092,192.168.10.22:9092"
#指定了Kafka集群中Broker服务器的地址列表,Logstash将尝试连接这些地址以获取消息。
topics => "nginx"
#指定了要订阅的主题名称,这里是"nginx"。
type
#设置了输入数据的类型为"nginx_kafka"
codec => "json"
#配置了数据编码解码器为"json",这意味着Logstash将自动解析从Kafka接收到的消息内容为JSON格式。
auto_offset_reset => "earliest"
#设置为"earliest",从最初的消息开始读取。
decorate_events => true
#表示Logstash将在传递给Elasticsearch的数据中添加Kafka相关的元数据信息。
output字段:
根据数据中的tags字段进行逻辑判断,分别将数据输出到不同的Elasticsearch索引:
#若tags字段包含"access",则将数据写入名为"nginx_access-%{+YYYY.MM.dd}"的索引
#若tags字段包含"error",则将数据写入名为"nginx_error-%{+YYYY.MM.dd}"的索引在elasticsearch服务器上查看所有索引

在kibana服务器上建立索引并查看信息

'-----------------------------修改filebeat服务配置文件--------------------------------'
[root@filebeat opt]#vim /etc/filebeat/filebeat.yml
15 filebeat.inputs:
16 - type: log
17 enabled: true
18 paths:
19 - /var/log/nginx/access.log
20 tags: ["access"]
21 - type: log
22 enabled: true
23 paths:
24 - /var/log/nginx/error.log
25 tags: ["error"]
160 #----------------------------- Kafka output --------------------------------
161 output.kafka:
162 enabled: true
163 hosts: ["192.168.83.80:9092","192.168.83.90:9092","192.168.83.100:9092"]
164 topic: "nginx"
165 #----------------------------- Logstash output --------------------------------
166 #output.logstash:
167 # The Logstash hosts
168 # hosts: ["192.168.83.50:5044"]
[root@filebeat opt]#filebeat -e -c /etc/filebeat/filebeat.yml
'-----------------------------添加logstash服务配置文件--------------------------------'
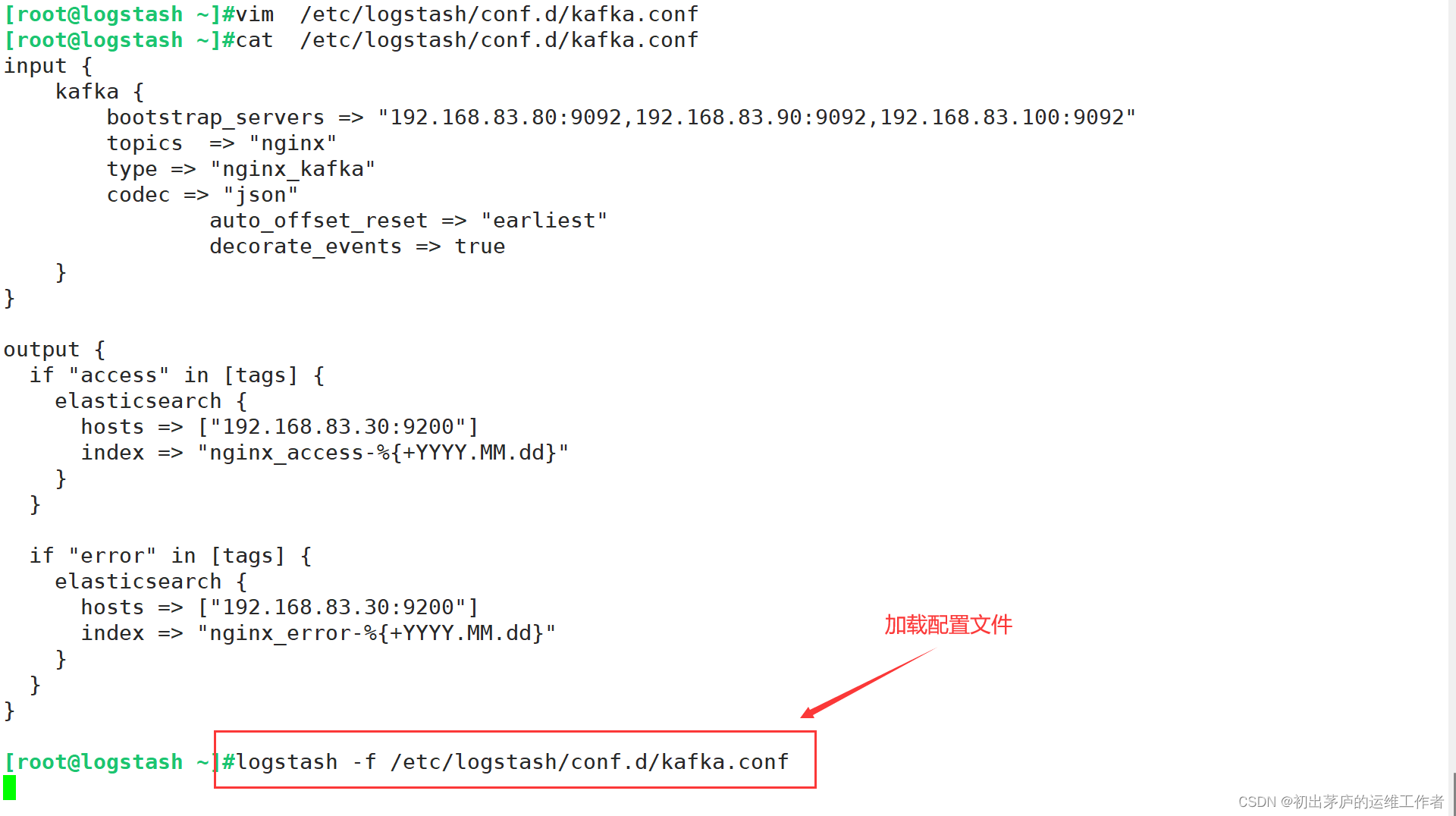
[root@logstash ~]#vim /etc/logstash/conf.d/kafka.conf
input {
kafka {
bootstrap_servers => "192.168.83.80:9092,192.168.83.90:9092,192.168.83.100:9092"
topics => "nginx"
type => "nginx_kafka"
codec => "json"
auto_offset_reset => "earliest"
decorate_events => true
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.83.30:9200"]
index => "nginx_access-%{+YYYY.MM.dd}"
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.83.30:9200"]
index => "nginx_error-%{+YYYY.MM.dd}"
}
}
}
[root@logstash ~]#logstash -f /etc/logstash/conf.d/kafka.conf
#登录kibana服务web界面创建索引进行查看