管道(channel)
前言
go语言对管道作用的解释是这样的:通过消息实现内存共享,channel就是为此而生的,
与c++实现并发编程中利用共享内存进行多线程/进程通信不同,go语言通道的思想就是
协程与协程之间并不创建实质上的共享,而是基于管道的通信,实现多个协程之间共享内存。
在Go语言中,我们会通过关键字chan来声明一个管道,同时我们也要指定其存储的数
据是什么类型,例如下面我们可以尝试创建一个简单的管道:
var ch chan int
当然这只是一个管道的声明,此时管道还没有初始化,其值为nil
管道的创建
创建管道只有一个方法,使用内置函数make,对于管道而言,main函数接收两个参数
第一个是管道的类型,第二个是可选参数为管道的缓冲大小。例子:
intCh:=make(chan int)
strCh:=make(chan string,1)
我们在使用完一个管道之后记得关闭该管道,使用close函数来关闭该管道,函数签名为:
func close(c<-chan Type)
示例:
func main(){
intCh:=make(chan int)
close(intCh))
}
有时候我们也可以用defer来优雅的关闭
管道的读写
对于一个管道而言,Go使用了两种很形象的操作符来表示读写操作:
<-:表示管道的读操作<-:表示管道的写操作
<-很生动的表示了数据的流动方向,我们来看一个int类型的管道读写的例子:
package main
import "fmt"
func main() {
var ch chan int
ch = make(chan int, 1)
defer close(ch)
ch <- 1
a := <-ch
fmt.Println(a)
}
输出结果:
1
管道里面数据的流动方式与队列相似,都是先进先出,协程对管道的操作是同步的,在某一
时刻只有一个协程可以写管道,同时也只有一个协程读管道中的数据。
无缓冲管道
对于无缓冲管道而言,因为我们所设置的缓冲区容量为0,所以缓冲区里面不会存放任何数据,
由于缓冲区不能缓存任何数据,所以向管道里面写入数据时必须立刻就有其他协程来读取数据,
否则就会阻塞,读也是同理,这也解释了下面这个代码为什么会出现死锁:
package main
import "fmt"
func main() {
var ch chan int
ch = make(chan int)
defer close(ch)
ch <- 1
a := <-ch
fmt.Println(a)
}
我们在使用无缓冲管道时,为了保证读写操作的一致,一般会采取再使用一个协程来进行数据
的读/写
package main
import "fmt"
func main() {
var ch chan int
ch = make(chan int)
defer close(ch)
go func() {
ch <- 1
}()
n := <-ch
fmt.Println(n)
}
输出结果:
1
有缓存管道
有缓冲管道的基本使用
当我们使用有缓存管道时,会为管道设置缓冲区大小,当管道有了缓冲区,就像是一个阻塞
队列一样,当队列已满/为空时,协程都会阻塞,。无缓冲管道在发送数据时,必须立刻有人
接收, 否则就会一直阻塞。对于有缓冲管道则不必如此,对于有缓冲管道写入数据时会先将
数据放入缓冲区,当缓冲区满了才会阻塞等待协程来读取管道中的数据,同理我们在读数据的
时候,会先从缓冲区中读取数据,直到缓冲区没数据了,才会阻塞的等待协程来向管道中写入
数据。所以上面的无缓冲死锁代码稍作修改在这里就可以运行:
func main() {
// 创建有缓冲管道
ch := make(chan int, 1)
defer close(ch)
// 写入数据
ch <- 123
// 读取数据
n := <-ch
fmt.Println(n)
}
不过这种同步读写的方式是很危险的,一但缓冲区满/空了,可能就会永远堵塞。因为可能
没有其他协程来写入/读取数据,比如下面这个例子:
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 5)
chW := make(chan struct{})
chR := make(chan struct{})
defer func() {
close(ch)
close(chW)
close(chR)
}()
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("write", i)
}
chW <- struct{}{}
}()
go func() {
for i := 0; i < 10; i++ {
time.Sleep(time.Second * 10)
fmt.Println("read", <-ch)
}
chR <- struct{}{}
}()
fmt.Println("Write done", <-chW)
fmt.Println("Read done", <-chR)
}
这里我们创建了三个管道,一个有缓冲管道来进行协程间的通信,两个无缓冲管道来实现协程
之间的同步,负责读的协程每次读取之前都会等待1毫秒,负责写的协程一口气做多也只能写入
5个数据,因为管道缓冲区最大只有5,在没有协程来读取之前,只能阻塞等待,所以其输出为:
write 0
write 1
write 2
write 3
write 4
read 0
write 5
read 1
write 6
read 2
write 7
read 3
write 8
read 4
write 9
Write done {}
read 5
read 6
read 7
read 8
read 9
Read done {}
可以看到负责写的协程刚开始就一口气发送了5个数据,缓冲区满了以后就开始阻塞等待读协
程来读取,后面就是每当读协程1毫秒读取一个数据,缓冲区有空位了,写协程就写入一个数
据,直到所有数据发送完毕,写协程执行结束,随后当读协程将缓冲区所有数据读取完毕后,
读协程也执行结束,最后主协程退出。
补充
- len函数与cap函数的使用
我们可以通过内置函数len来获取管道缓冲区中数据的个数或者通过cap函数来访问管道
缓冲区的大小
示例:
package main
import "fmt"
func main() {
ch := make(chan int, 5)
defer close(ch)
for i := 0; i < 4; i++ {
ch <- i
}
fmt.Println(len(ch))
fmt.Println(cap(ch))
}
输出为:
4
5
- 基于管道的阻塞.实现父子协程的同步
package main
import (
"fmt"
"sync"
"time"
)
var chR = make(chan struct{})
func main() {
var wait sync.WaitGroup
wait.Add(1)
defer func() {
close(chR)
}()
go func() {
chR <- struct{}{}
fmt.Println(1)
wait.Done()
}()
time.Sleep(time.Second * 10)
fmt.Println(2)
fmt.Println(<-chR)
wait.Wait()
}
输出为
2
1
{}
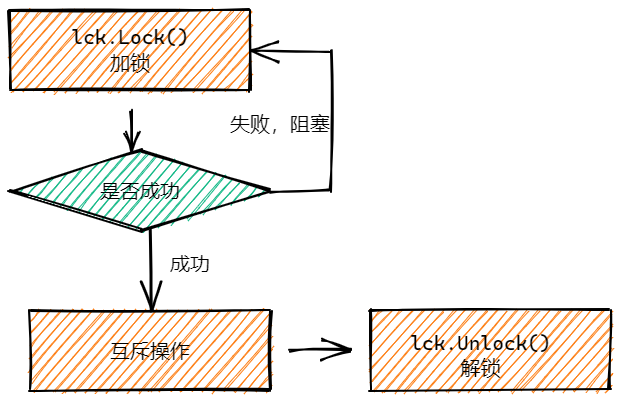
- 我们还可以基于有缓冲管道实现一个简单的互斥锁
package main
import (
"fmt"
"sync"
)
func main() {
var wait sync.WaitGroup
wait.Add(2)
var count = 0
mutex := make(chan struct{}, 1)
done := make(chan bool, 2)
go func() {
mutex <- struct{}{} // 加锁
for i := 0; i < 10; i++ {
count++
}
<-mutex // 解锁
done <- true
}()
go func() {
mutex <- struct{}{}
for i := 0; i < 7; i++ {
count--
}
<-mutex
done <- true
}()
go func() {
<-done
wait.Done()
}()
go func() {
<-done
wait.Done()
}()
wait.Wait()
fmt.Println(count)
}
输出结果为:
3
无缓冲与有缓冲管道在使用中的注意点
- 对无缓冲管道不能同步读写操作,否则会造成管道阻塞
- 不能读取缓存区为空的管道,否则会造成管道阻塞
- 不能写入缓存区已满的管道,否则会造成管道阻塞
- 不能读写
nil的管道 - 不能写入已关闭的管道,否则会panic
- 不能关闭已关闭的管道,否则会panic
- 不能关闭
nil的管道,否则会panic