缺页异常
CPU通过地址总线可以访问连接在地址总线上的所有外设,包括物理内存、IO设备等;但从CPU发出的访问地址并非是这些外设在地址总线上的物理地址,而是一个虚拟地址;有MMU(Memory Management Uint)将虚拟地址转换成物理地址再从地址总线上发出;MMU上的这种虚拟地址和物理地址的转换关系是需要创建的;并且MMU还可以设置这个物理页是否可以进行写操作;当没有创建一个虚拟地址到物理地址的映射,或者创建了这样的映射,但是该物理页不可写的时候,MMU将会通过CPU产生一个缺页异常;
在实际需要某个虚拟内存区域的数据之前,虚拟内存和物理内存之间的关联不会建立;如果进程访问的虚拟地址空间尚未于页帧关联,CPU自动的产生一个缺页异常,内核必须处理此异常;
缺页异常的处理实现因CPU的不同而有所不同;由于CPU采用了不同的内存管理概念,生成缺页异常的细节也不太相同;因此,缺页异常的处理例程在内核代码中位于特定于体系结构的部分;
页表和TLB
页表(Page Table)和TLB(Translation Lookaside Buffer)是在计算机体系结构中用于地址转换的密切相关的概念。
- 页表:
- 页表是一种数据结构,存储了虚拟内存地址和物理内存地址之间的映射关系。当CPU发出内存访问请求时,操作系统通过页表将虚拟地址转换为物理地址。如果页面不在内存中,会发生缺页异常,并触发加载页面到内存中的操作。
- TLB:
- TLB是存储最近使用的页表条目的高速缓存,用于加速地址转换过程。TLB可以在CPU内部或者在MMU内部,存储一部分页表的映射关系,当CPU发出内存访问请求时,会先在TLB中寻找对应的物理地址,以提高地址转换的速度。
因此,页表和TLB之间的关系可以理解为页表提供了全部的地址映射关系,而TLB则是一种缓存机制,存储了最近频繁访问的一部分地址映射关系,用于加速地址转换过程。当CPU访问内存时,会先在TLB中寻找物理地址,如果缺失则会根据页表进行地址转换。
用户缺页异常处理流程
ARM64架构,页错误处理入口函数是do_translation_fault;
/*
* First Level Translation Fault Handler
*
* We enter here because the first level page table doesn't contain a valid
* entry for the address.
*
* If the address is in kernel space (>= TASK_SIZE), then we are probably
* faulting in the vmalloc() area.
*
* If the init_task's first level page tables contains the relevant entry, we
* copy the it to this task. If not, we send the process a signal, fixup the
* exception, or oops the kernel.
*
* NOTE! We MUST NOT take any locks for this case. We may be in an interrupt
* or a critical region, and should only copy the information from the master
* page table, nothing more.
*/
static int __kprobes do_translation_fault(unsigned long addr,
unsigned int esr,
struct pt_regs *regs)
{
if (addr < TASK_SIZE)
return do_page_fault(addr, esr, regs);
do_bad_area(addr, esr, regs);
return 0;
}
如果触发异常的虚拟地址是空户虚拟地址,调用函数do_page_fault来处理;如果触发异常的虚拟地址是内核虚拟地址或不规范地址,调用函数do_bad_area来处理;
do_page_fault最后会委托handle_mm_fault处理用户空间的页错误异常;从函数handle_mm_fault开始的部分是所有处理器架构共用的部分;用户空间页错误异常是指进程访问用户虚拟地址生成的页错误异常,分两种情况:
1)进程在用户模式下访问用户虚拟地址,生成页错误异常;
2)进程在内核模式下访问用户虚拟地址,生成页错误异常;进程通过系统调用进入内核模式,系统调用传入用户空间的缓冲区,进程在内核模式下访问用户空间的缓冲区;
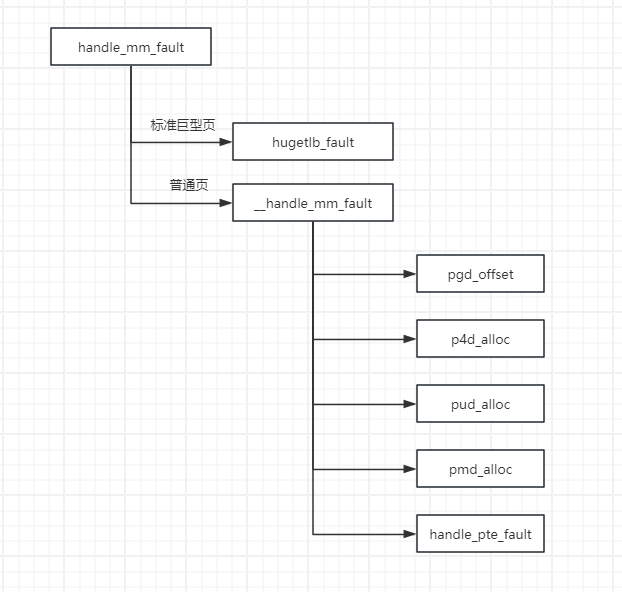
handle_mm_fault处理流程如下:如果虚拟内存区域使用标准巨型页,那么调用函数hugetlb_fault处理标准巨型页的页错误异常;如果虚拟内存区域使用普通页,那么调用函数__handle_mm_fault处理普通页的页错误异常;
/*
* By the time we get here, we already hold the mm semaphore
*
* The mmap_sem may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
*/
int handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
int ret;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
mem_cgroup_count_vm_event(vma->vm_mm, PGFAULT);
/* do counter updates before entering really critical section. */
check_sync_rss_stat(current);
/*
* Enable the memcg OOM handling for faults triggered in user
* space. Kernel faults are handled more gracefully.
*/
if (flags & FAULT_FLAG_USER)
mem_cgroup_oom_enable();
if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE,
flags & FAULT_FLAG_INSTRUCTION,
flags & FAULT_FLAG_REMOTE))
return VM_FAULT_SIGSEGV;
if (unlikely(is_vm_hugetlb_page(vma)))
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);
else
ret = __handle_mm_fault(vma, address, flags);
if (flags & FAULT_FLAG_USER) {
mem_cgroup_oom_disable();
/*
* The task may have entered a memcg OOM situation but
* if the allocation error was handled gracefully (no
* VM_FAULT_OOM), there is no need to kill anything.
* Just clean up the OOM state peacefully.
*/
if (task_in_memcg_oom(current) && !(ret & VM_FAULT_OOM))
mem_cgroup_oom_synchronize(false);
}
/*
* This mm has been already reaped by the oom reaper and so the
* refault cannot be trusted in general. Anonymous refaults would
* lose data and give a zero page instead e.g. This is especially
* problem for use_mm() because regular tasks will just die and
* the corrupted data will not be visible anywhere while kthread
* will outlive the oom victim and potentially propagate the date
* further.
*/
if (unlikely((current->flags & PF_KTHREAD) && !(ret & VM_FAULT_ERROR)
&& test_bit(MMF_UNSTABLE, &vma->vm_mm->flags)))
ret = VM_FAULT_SIGBUS;
return ret;
}
EXPORT_SYMBOL_GPL(handle_mm_fault);
__handle_mm_fault处理流程:
1)在页全局目录中查找虚拟地址对应的表项;
2)在页四级目录中查找虚拟地址对应的表项,如果页四级目录不存在,那么先创建页四级目录;
3)在页上层目录中查找虚拟地址对应的表项,如果页上层目录不存在,那么先创建页上层目录;
4)在页中间目录中查找虚拟地址对应的表项,如果页中间目录不存在,那么先创建页中间目录;
5)到达直接页表,调用函数handle_pte_fault来处理;
handle_pte_fault中对处理匿名页的缺页异常、文件页的缺页异常和写时复制;
匿名页的缺页异常
什么情况会触发匿名页的缺页异常呢?
1)函数的局部变量比较大,或者函数调用的层次比较深,导致当前栈不够用,需要扩大栈;
2)进程调用malloc,从堆申请了内存块,只分配了虚拟内存区域,还没有映射到物理页,第一次访问时触发缺页异常;
3)进程直接调用mmap,创建匿名的内存映射,只分配了虚拟内存区域,还没映射到物理页,第一次访问时触发缺页异常;
函数do_anonymous_page处理私有匿名页的缺页异常;
文件页的缺页异常
什么情况会触发文件页的缺页异常呢?
1)启动程序的时候,内核为程序的代码段和数据段创建私有的文件映射,映射到进程的虚拟地址空间,第一次访问的时候触发文件页的缺页异常;
2)进程使用mmap创建文件映射,把文件的一个区间映射到进程的虚拟地址空间,第一次访问的时候触发文件的缺页异常;
函数do_fault处理文件页和共享匿名页的缺页异常;
handle_pte_fault的详细流程,do_anonymous_page,do_fault以及写时复制等,比较复杂,后续进行补充;
内核模式页错误异常,后续补充;
参考文献
- 《linux内核深度解析》,余华兵著