什么是SQL?
SQL(Structured Query Language) ,结构化查询语言。SQL是一种专用语言,用户关系型数据库管理系统或者在关系流数据管理系统中进行流处理。
- SQL怎么读?两种读法:一个字母一个字母读或者连起来读。 一个字母一个字母读音标: /ˌɛsˌkjuːˈɛl/,连读音标: /ˈsiːkwəl/ 。
什么是关系型数据库?
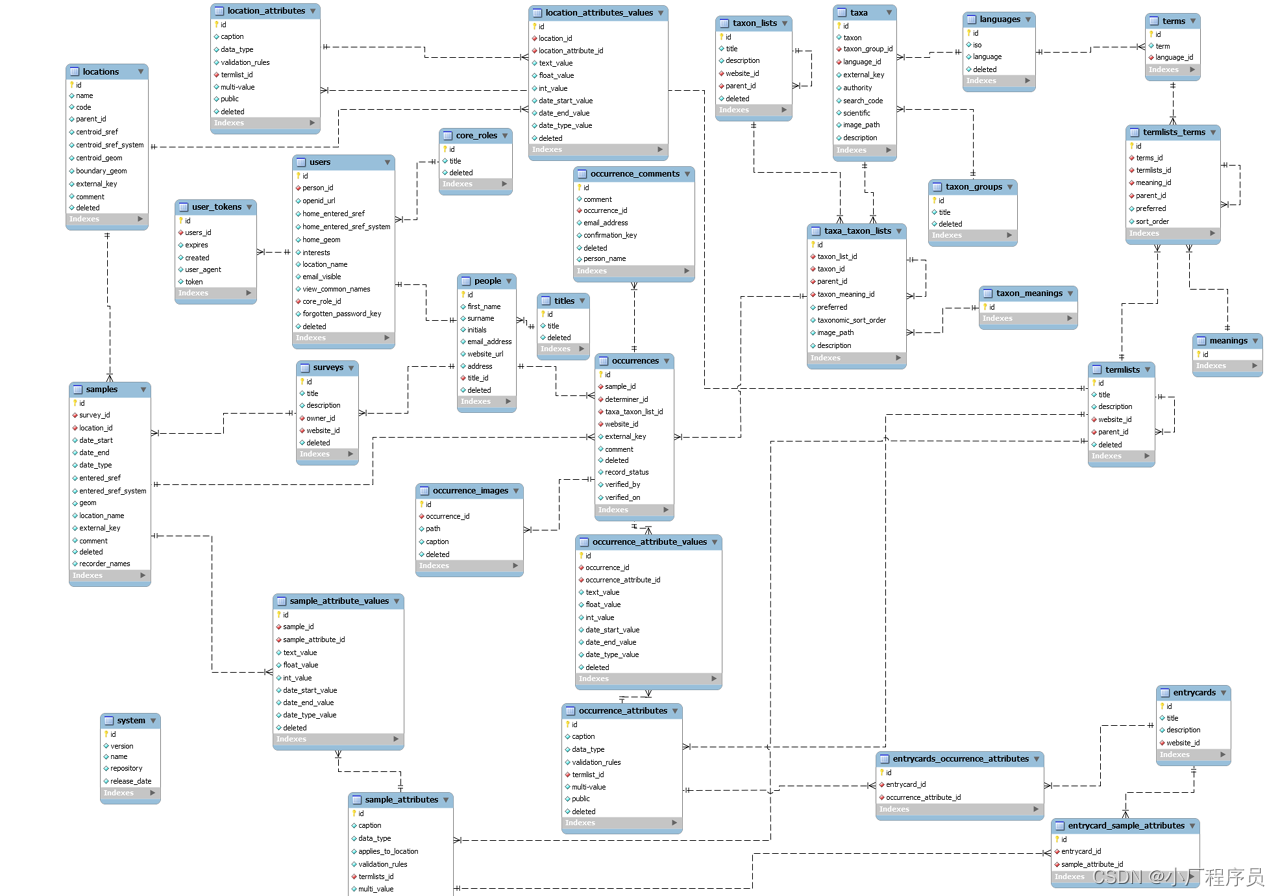
关系型数据是一种数据库类型,关系型数据库存储和提供数据都是相互关联的。关系型数据库是通过关系模型来组织数据的。通常关系型数据通过多张表中的行和列来组织关系。表中的行也叫记录或者元组。列也叫属性。
什么是数据库?
数据库是在按照数据模型来组织,存储和管理数据的集合。数据库一般由很多表组成,这些表之间有直接或者间接的关系。我们可以把表定义为图中的节点,关系为他们之间的边。如下图:
什么是数据库管理系统?
数据库管理系统是数据库系统的核心部分,他复杂各种CRUD,没有它根本就不会存在数据库系统。
常见的数据库管理系统:MySQL, PostgreSQL, MariaDB, Oracle, SQL Server, DB2…一大堆。
什么是数据库系统?
数据库系统是一个生态系统,包括数据库,数据库管理系统和数据库的集成环境还有你的应用程序(我们都是数据库系统开发工程师。。。)。这是说首先你得有一个系统来CRUD你的数据库,然后你得有各种driver能连接数据库系统,或者有GUI的客户端来操作数据库。
比如: 你启动一个MySQL就是启动了一个数据库管理系统,你在MySQL中新建自己的数据库,使用MySQL的driver和dialect(方言)来操作MySQL数据库,那么这个整体就是数据库系统。
什么是关系流数据管理系统?
关系流数据管理系统是借鉴了数据库管理系统的一些概念和技术针对大量流数据进行快速响应的系统。其实我理解就是大数据哪些内容。
常见的关系流数据管理系统:Spark, Flink,Storm。
文章中所有的SQL都是基于MySQL 8.0数据库系统。
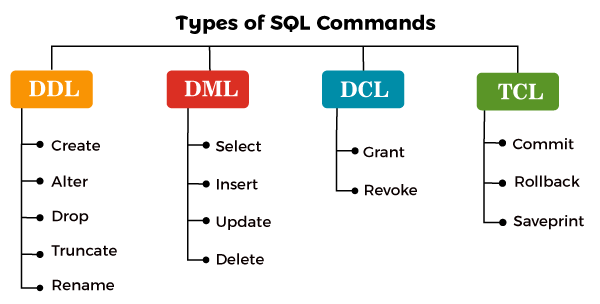
DDL, DQL, DCL 和DML
这些概念整的人头大。
- DDL(Data Defination Language)数据定义语言
- DQL(Data Query Language)数据查询语言:用来查询数据中的数据,专指查询:SELECT
- DCL(Data Control Language)数据控制语言:用来控制权限:Authorization
- DML(Data Manipulation Language) 数据操纵语言,指的就是CRUD
大家对DQL的认可度不高,DDL,DML和DCL听得比较多,我理解是因为SELECT专指SELECT xxxx,如果你使用FROM和WHERE,那么FROM和WHERE就属于DML了,感觉还是挺鸡肋的。
约束
约束就是限制一个数据只能为A不能为B。比如:你设置一个用户的用户名长度不能超过20个中文,性别在数据库中的类型只能为数字,那么数据库会遵守这些约束,当程序向数据库写入用户名超过20个中文时就会报错,性别写入字符串时也会报错。
当然我们对约束的需求还是比较多的,主要有以下几类:
- 主键
- 唯一键
- 外键
- check
- NOT NULL
- Default
- 数据类型
- 字段长度
我们上面列了这么多,MySQL可以通过下面的SQL来查询约束
SELECT * FROM information_schema.table_constraints;COPY
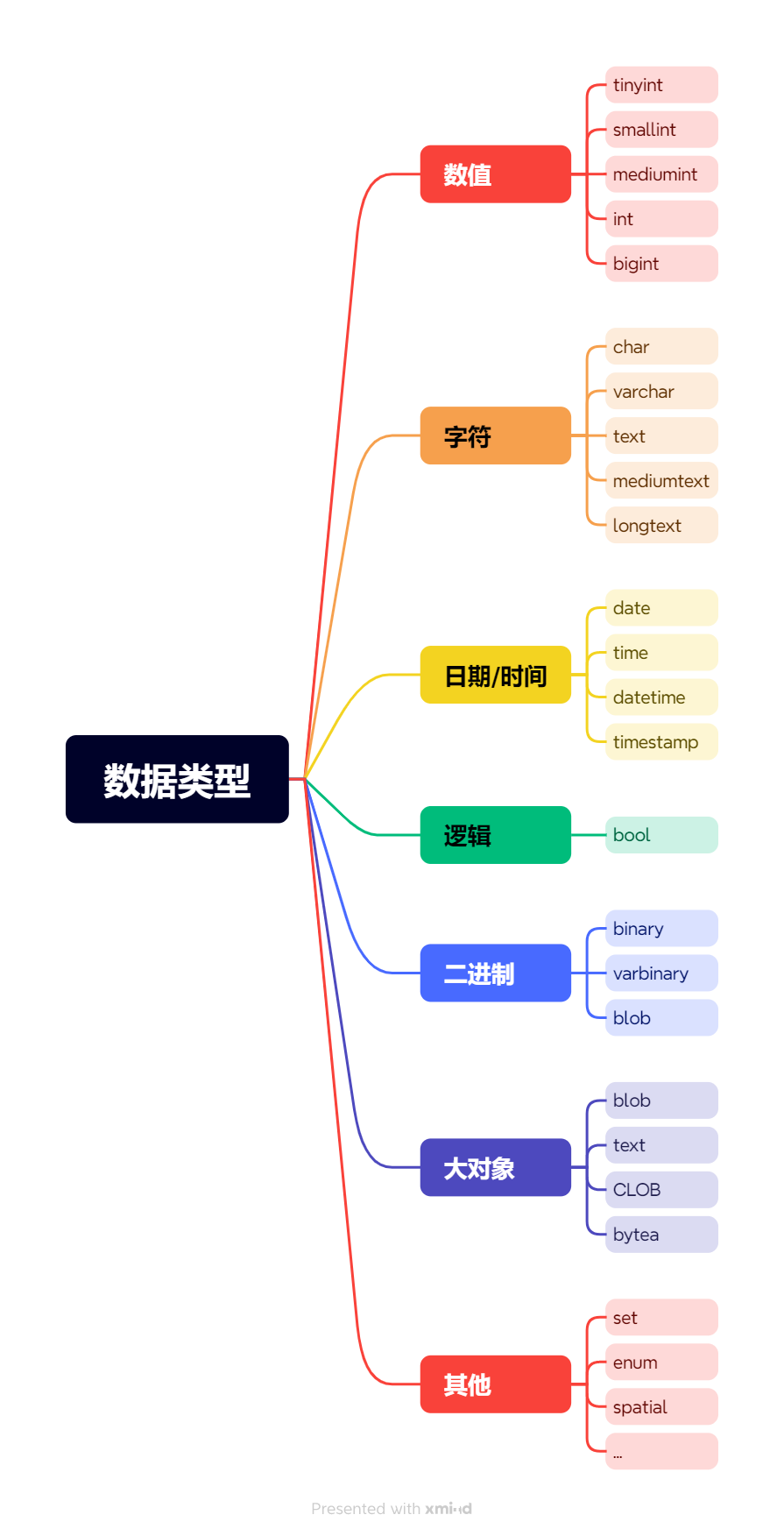
数据类型
数据库提供了很多数据类型以满足我们的应用需求,虽然很多,但是分类一下还是很清晰的,看下数据类型图:
Numberic Types
| Numeric Type | Signed Range | Unsigned Range |
|---|---|---|
| TINYINT | -128 to 127 | 0 to 255 |
| SMALLINT | -32768 to 32767 | 0 to 65535 |
| MEDIUMINT | -8388608 to 8388607 | 0 to 16777215 |
| INT or INTEGER | -2147483648 to 2147483647 | 0 to 4294967295 |
| BIGINT | -9223372036854775808 to 9223372036854775807 | 0 to 18446744073709551615 |
| DECIMAL (M,D) or NUMERIC (M,D) | Depends on M and D values | Depends on M and D values |
| FLOAT (P) | -3.402823466E+38 to -1.175494351E-38, 0, and 1.175494351E-38 to 3.402823466E+38 | 0 to 3.402823466E+38 |
| DOUBLE (M,D) | -1.7976931348623157E+308 to -2.2250738585072014E-308, 0, and 2.2250738585072014E-308 to 1.7976931348623157E+308 | 0 to 1.7976931348623157E+308 |
| BIT (M) | -2^(M-1) to 2^(M-1)-1 | 0 to 2^M-1 |
| BOOLEAN | N/A | N/A |
| SERIAL | N/A | 1 to 18446744073709551615 |
What is the size of column of int(11) in mysql in bytes?
String types
| String Type | Description |
|---|---|
| CHAR(M) | A fixed-length string useful when all values are approximately the same length. Pad with space when saved. M can be from 0 to 255. |
| VARCHAR(M) | A variable-length string useful when values are of varying length. M can be from 0 to 65535. |
| TINYTEXT | A tiny text string holding a maximum length of 255 characters. |
| TEXT | A text string holding a maximum length of 65,535 characters |
| MEDIUMTEXT | A medium-sized text string which can hold a string with a maximum length of 16,777,215 characters |
| LONGTEXT | A large text string which can hold a string with a maximum length of 4,294,967,295 characters |
| ENUM(‘value1′,’value2’,…) | A string object with a value chosen from a list of permitted values |
| SET(‘value1′,’value2’,…) | A string objects that can have zero or more values, each of which must be chosen from a list of permitted values |
| BINARY(M) | Similar to CHAR, but stores binary byte strings. Pad with 0x00 bytes when saved. |
| VARBINARY(M) | Similar to VARCHAR, but stores binary byte strings. |
| TINYBLOB | A binary large object column with a maximum length of 255 bytes |
| BLOB | A binary large object column with a maximum length of 65,535 bytes |
| MEDIUMBLOB | A binary large object column with a maximum length of 16,777,215 bytes |
| LONGBLOB | A binary large object column with a maximum length of 4,294,967,295 bytes |
Date types
| Date/Time Type | Description |
|---|---|
| DATE | A date. The supported range is ‘1000-01-01’ to ‘9999-12-31’. |
| DATETIME | A date and time combination. The supported range is ‘1000-01-01 00:00:00’ to ‘9999-12-31 23:59:59’. |
| TIMESTAMP | A timestamp. The range is ‘1970-01-01 00:00:01’ UTC to ‘2038-01-19 03:14:07’ UTC. |
| TIME | A time. The range is ‘-838:59:59’ to ‘838:59:59’. |
| YEAR | A year in four-digit format. Values in the range 1901 to 2155 and 0000. |
有这么数据类型可以供我们选择。
怎么选择?一般就是根据我们的业务需求,然后满足一定的扩展性的情况下选择存储小的类型。存储小的类型占用的磁盘空间小,数据在一个数据叶中的存储就会更多,增删查改I/O就会更少。
字符集和排序规则
字符集(Character Set)和排序规则(Collation)是与字符编码和字符串比较相关的重要概念。
字符集(Character Set):字符集是一个符号集合。在电脑中,每一个符号是由若干位表示的,每个符号对应唯一的位模式。简单的说,字符集就是一个符号与位模式之间的对应关系。
在MySQL中,它支持多种字符集,如utf8(可以用1到3个字节存储字符),utf8mb4(可以用1到4个字节存储字符),latin1(用1个字节存储字符)等等。选择合适的字符集可以确保您的数据库正确存储和显示各种语言的文本。
排序规则(Collation):排序规则决定了字符串之间的比较规则。比如在英文中,字母“a”和“A”是相同的。但在计算机中,“a”的ASCII码是97,“A”的ASCII码是65,它们在计算机看来是不同的。因此,我们需要一个规则来指导计算机在比较时应如何处理这种情况,这个规则就是所谓的排序规则。
不同的语言和地区,排序规则是不一样的。
但是我从来没有修改过排序规则,我只为能够存储emoji表情把utf-8字符集修改为了utf8mb4。但是前提是业务系统能容忍不区分大小写。
DDL语句
DDL语句帮助我们对数据库从0到1的建设。
数据库CRUD
创建数据库
我们得先创建数据库,在MySQL中创建数据库的语法如下:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
| ENCRYPTION [=] {'Y' | 'N'}
}COPY
修改数据库
MySQL ALTER DATABASE无法修改数据库名的,看他的alter_option就可以知道了。
ALTER {DATABASE | SCHEMA} [db_name]
alter_option ...
alter_option: {
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| [DEFAULT] ENCRYPTION [=] {'Y' | 'N'}
| READ ONLY [=] {DEFAULT | 0 | 1}
}COPY
删除数据库
删除数据库的SQL语句是非常简单的,但是却是个高危操作,可能有不少人因为这个SQL而失业。
DROP {DATABASE | SCHEMA} [IF EXISTS] db_nameCOPY
查询数据库
MySQL查询数据库有多种方式:
- show
- 数据字典
-- show查询数据库
SHOW DATABASES;
SHOW DATABASES like '%trade%';
-- 数据字典查询数据库
SELECT `SCHEMA_NAME`
FROM `INFORMATION_SCHEMA`.`SCHEMATA`;
SELECT `SCHEMA_NAME`
FROM `INFORMATION_SCHEMA`.`SCHEMATA` WHERE SCHEMA_NAME LIKE '%trade%';COPY
创建表
MySQL创建表的SQL特别长,我们这儿只给一部分吧,大家平时使用工具自己生成就好了:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[partition_options]
[IGNORE | REPLACE]
[AS] query_expression
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }
create_definition: {
col_name column_definition
| {INDEX | KEY} [index_name] [index_type] (key_part,...)
[index_option] ...
| {FULLTEXT | SPATIAL} [INDEX | KEY] [index_name] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| check_constraint_definition
}
COPY
这儿给出一个示例吧,创建一个trade_user表,这张表有以下字段:
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | MUL | NULL | |
| email | longtext | YES | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| birthday | datetime | YES | | NULL | |
| created_at | datetime | YES | | NULL | |
| updated_at | datetime | YES | | NULL | |
+------------+------------------+------+-----+---------+----------------+
COPY
对应的建表语句如下:
CREATE TABLE trade_user (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
email LONGTEXT,
age TINYINT UNSIGNED,
birthday DATETIME,
created_at DATETIME,
updated_at DATETIME,
PRIMARY KEY (id),
INDEX idx_name (name)
);
COPY
我们再新建一张trade_order表表示用户的订单方便我们后面进行joinSQL测试。
表结构如下所示:
+--------------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| user_id | bigint unsigned | YES | | NULL | |
| order_no | bigint unsigned | YES | | NULL | |
| created_at | datetime | YES | | NULL | |
| updated_at | datetime | YES | | NULL | |
| total_amount | bigint unsigned | YES | | NULL | |
| paied_amount | bigint unsigned | YES | | NULL | |
+--------------+-----------------+------+-----+---------+----------------+
COPY
建表SQL:
CREATE TABLE trade_order (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT UNSIGNED NOT NULL,
order_no BIGINT UNSIGNED NOT NULL,
created_at DATETIME NOT NULL,
updated_at DATETIME NOT NULL,
total_amount BIGINT UNSIGNED NOT NULL,
paied_amount BIGINT UNSIGNED NOT NULL
);
COPY
建表避坑
有些数据库比如MySQL有一种语法:create tables as select,表示既创建表又从另一张表拷贝数据到新表,但是会有一个问题就会所有的约束和索引会丢失。举个例子:
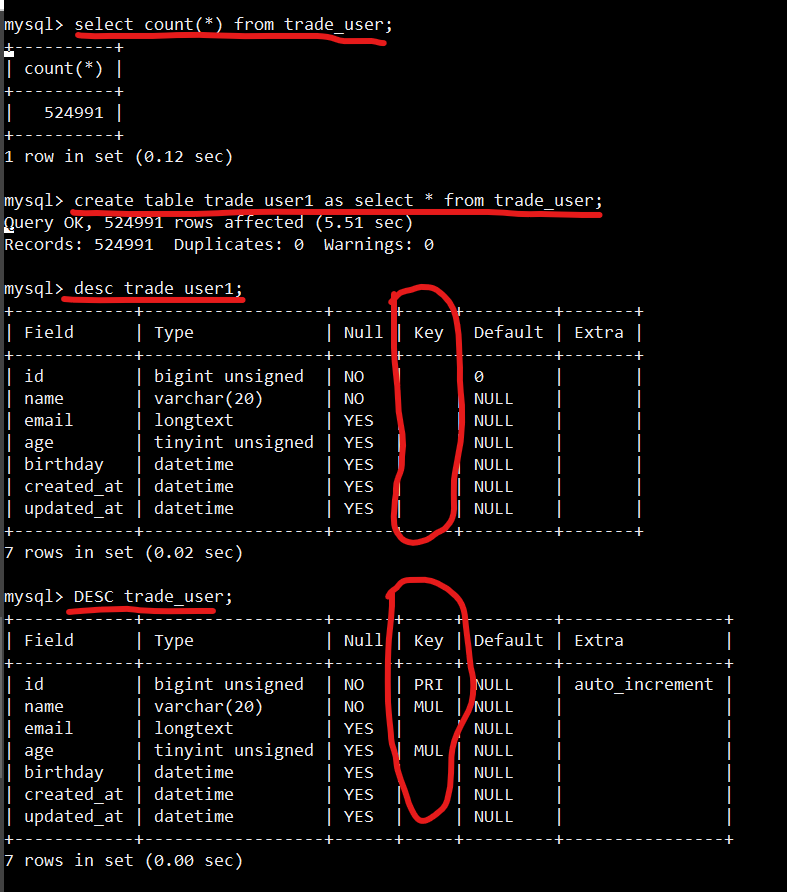
正确姿势
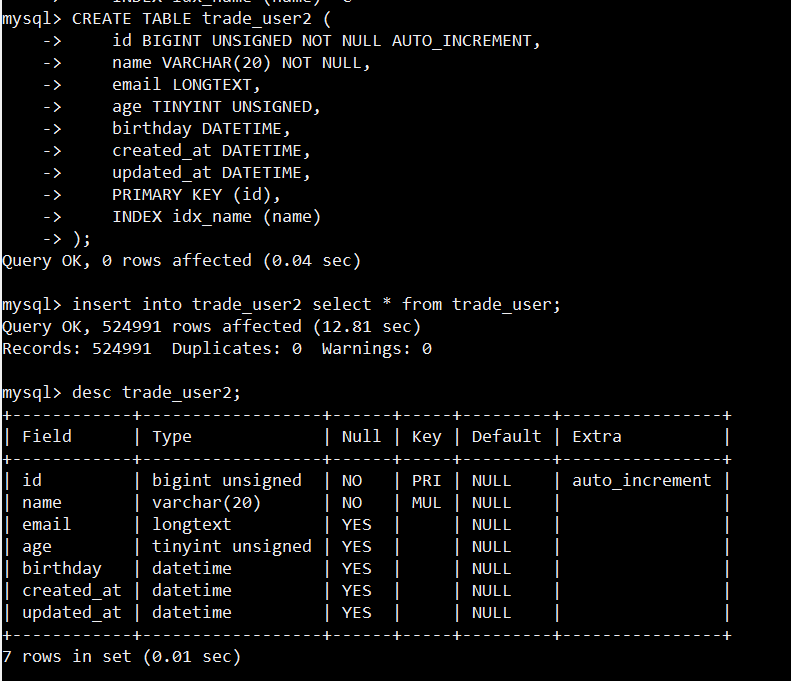
在使用不熟悉的SQL之前要确保理解了它的所有特性。
修改表
修改表使用alter table语句, MySQL alter table语句如下:
alter table的语法也有点多啊,如果要修改大家还是用工具吧,先修改然后生成SQL。
ALTER TABLE tbl_name
[alter_option [, alter_option] ...]
[partition_options]
alter_option: {
table_options
| ADD [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| ADD [COLUMN] (col_name column_definition,...)
| ADD {INDEX | KEY} [index_name]
[index_type] (key_part,...) [index_option] ...
| ADD {FULLTEXT | SPATIAL} [INDEX | KEY] [index_name]
(key_part,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| ADD [CONSTRAINT [symbol]] CHECK (expr) [[NOT] ENFORCED]
| DROP {CHECK | CONSTRAINT} symbol
| ALTER {CHECK | CONSTRAINT} symbol [NOT] ENFORCED
| ALGORITHM [=] {DEFAULT | INSTANT | INPLACE | COPY}
| ALTER [COLUMN] col_name {
SET DEFAULT {literal | (expr)}
| SET {VISIBLE | INVISIBLE}
| DROP DEFAULT
}
COPY
修改表指南
MySQL 8.0版本支持了Instant方式修改表结构,但是只能最多64次,64次以后就回退回重建表的方式,然后有有了64次Instant机会。
具体可以参考:
删除表
MySQL删除表还是很简单的但是执行要慎重,SQL语句如下:
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]
COPY
注意
重要的事情说三遍:
删除之前要完整备份。
删除之前要完整备份。
删除之前要完整备份。
查询数据库中的表
MySQL查询表和查询数据库一样有两种方式:
- SHOW TABLES
- 查询数据字典
SQL如下:
-- show tables方式
show tables in 数据库名
-- 查询数据字典方式
SELECT `TABLE_NAME`
FROM `INFORMATION_SCHEMA`.`TABLES`
WHERE `TABLE_SCHEMA`='数据库名';
COPY
INSERT 插入数据
INSERT向表插入新数据,MySQL中一般有三种形式
- INSERT INTO tbl_name (col_name[, col_name]…) VALUES (value[, value]…); 这种形式是最基本的形式,用于向指定列插入一行或多行数据
- INSERT INTO tbl_name SET col_name=value[, col_name=value]…; 这种形式也可用于插入数据,数据的列名和值是通过“列名=值”的形式一一对应的
- INSERT INTO tbl_name (col_name[, col_name]…) SELECT … ; 这种形式是把查询出的数据直接插入到表中
额外说明下:INSERT INTO SELECT可以适用于复制表,数据转换或者聚合完解决查询新表等场景。INSERT INTO 性能特别高。但是有索引会响应一些性能。
插入数据
我们插入数据都到上面定义的两张表:
-- 普通INSERT
INSERT INTO trade_user (name, email, age, birthday, created_at, updated_at) VALUES
('Alice', 'alice@example.com', 30, '1992-01-10 08:30:00', NOW(), NOW()),
('Bob', 'bob@example.com', 35, '1987-05-20 14:45:00', NOW(), NOW()),
('Charlie', 'charlie@example.com', 25, '1997-08-15 09:00:00', NOW(), NOW()),
('Diana', 'diana@example.com', 28, '1994-04-16 17:30:00', NOW(), NOW()),
('Eva', 'eva@example.com', 32, '1990-11-11 12:00:00', NOW(), NOW()),
('Frank', 'frank@example.com', 40, '1982-12-03 19:15:00', NOW(), NOW());
INSERT INTO trade_order (user_id, order_no, created_at, updated_at, total_amount, paied_amount) VALUES
(1, 1, NOW(), NOW(), 2500, 2500),
(2, 2, NOW(), NOW(), 4500, 4500),
(3, 3, NOW(), NOW(), 3000, 1500),
(4, 4, NOW(), NOW(), 1500, 1500),
(5, 5, NOW(), NOW(), 5200, 5200),
(6, 6, NOW(), NOW(), 1300, 1300);
-- INSERT INTO SELECT
INSERT INTO trade_order (user_id, order_no, created_at, updated_at, total_amount, paied_amount)
SELECT 1000 AS user_id, 1000001 AS order_no, NOW() AS created_at, NOW() AS updated_at, 2500 AS total_amount, 2500 AS paied_amount
UNION ALL
SELECT 1001, 1000002, NOW(), NOW(), 3000, 3000
UNION ALL
SELECT 1002, 1000003, NOW(), NOW(), 4000, 4000
UNION ALL
SELECT 1003, 1000004, NOW(), NOW(), 5000, 5000
UNION ALL
SELECT 1004, 1000005, NOW(), NOW(), 6000, 6000
UNION ALL
SELECT 1005, 1000006, NOW(), NOW(), 7000, 7000;
COPY
删除数据
删除数据使用DELETE,使用非常简单,执行要慎重,否则影响绩效(说是影响绩效是因为误删除还可以通过binlog恢复)。
MySQL的delete语法:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name [[AS] tbl_alias]
[PARTITION (partition_name [, partition_name] ...)]
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
COPY
删除数据避坑
- 生产环境SQL不要使用select查询出来的数据作为条件,就让DevOps查出来所有满足数据的ID,然后使用ID删除,一批删除不完就分多批,删除之前一定要备份数据,可以整表备份,可以增量备份。
- 线上删除整表数据不要直接
delete from xxx,你的binlog会受不了,你的下游复制会受不了,DevOps要骂人了,用户要骂人了;备份,备份,备份,重要事情说三遍;使用truncate table;不能用truncate table就分批delete,删除完以后optimize一下。
查询SELECT
我们大部分时间都在select, 同时select也是变换莫测,目前我也没玩出什么花。

简单查询
select * from trade_user;
select username from trade_user;
select username as uname from trade_user;
select distinct username from trade_user;
COPY
where 字段
比较运算符:
select * from trade_user where id>10;
where id < 10;
where id=10;
where id != 10;
where id <> 10;
COPY
逻辑运算符:
select * from trade_user where id=1 and username='';
where id=1 or id=2;
where not id=1;
where not id=1 and not id=2;
where not id=1 or not id=2;
where not (id=1 or id=2);
COPY
逻辑运算符小提示
又使用and又使用or的算是复杂查询了,尽可能使用一个区分度比较高的索引,否则就是index range和Index merge了。
in 查询
select * from trade_user where age in (12, 13);
select * from trade_user where age in (select age from trade_user);
select * from trade_user where (name, age) in (select name, age from trade_user);
select * from trade_user where (name, age) in (select name,age from trade_user where id=1);
select * from trade_user where (name, age) in (('b', 12));COPY
in 避坑
in中有null。
插入一条数据:
insert into trade_user (name, email, age, birthday, created_at, updated_at) values('fofcn.tech', 'fofcn@fofcn.tech', null, '1989-05-25 00:00:00', now(), now());
COPY
查询一下刚插入的数据:
select * from trade_user where age in (null);
COPY
查不出来,emo~

换个姿势,再来一次:
select * from trade_user where age is null;
COPY
查询出来了,完美~

为什么?
在 SQL 中,NULL 不是一个具体的值,而是代表一个“未知”的状态。如果你使用 IN 操作符来查询 NULL,可能会出现问题。
这是因为在 SQL 中, NULL 与任何其他值(包括另一个 NULL)的比较操作都会返回 NULL,而不是布尔值 TRUE 或 FALSE。
使用Go的小伙伴有没有试过nil == nil?
like模糊查询
select * from trade_user where `name` like '%al%';
select * from trade_user where `name` like '%al';
select * from trade_user where `name` like 'al%';
COPY
听说like左边%不会走索引?你说了可不算
这都得视情况而定,不是%在左边就一定不走索引。举个例子:还是我们的trade_user表。
我们的表有50多万数据,索引有3个:主键,idx_name,idx_age。
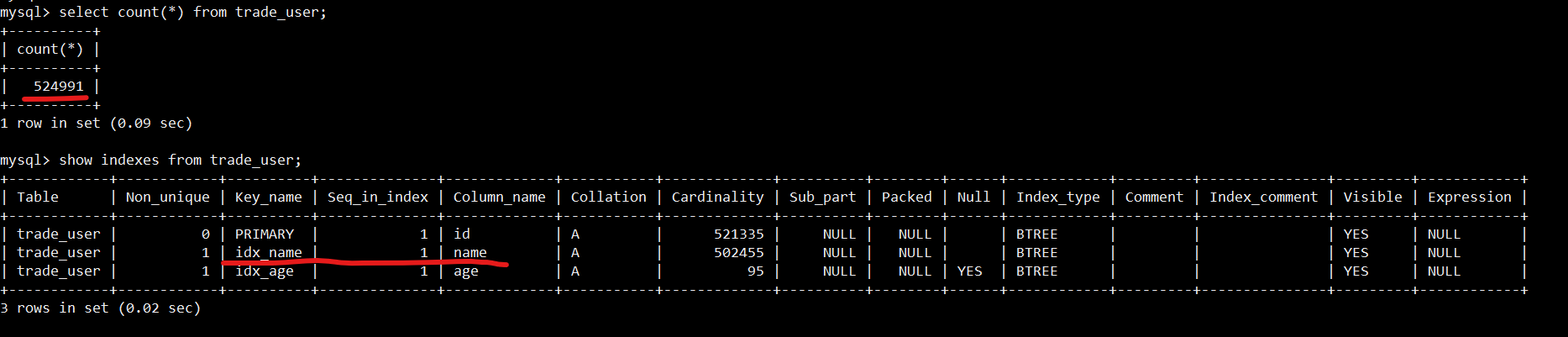
第一条SQL: 查询用户的所有信息,条件是用户名中有51的用户信息
explain select * from trade_user where name like '%51';
COPY
结果是真没走索引,全表扫描。

第二条SQL:查询用户的name,条件不变
explain select name from trade_user where name like '%51';
COPY
结果是走了索引,而且是覆盖索引。

第三条SQL:查询用户的id和name, 条件不变
explain select id,name from trade_user where name like '%51';
COPY
结果和第二条SQL一模一样。

第四条SQL:查询用户的id,name和birthday,查询条件不变
explain select id,name,birthday from trade_user where name like '%51';
COPY
结果和第一条一模一样,全表扫描

Limit M OFFSET N
select * from trade_user limit 10 offset 20000000
COPY
Limit M OFFSET N闭坑
参考:MySQL limit N offset M 速度慢?来实际体验下
聚合查询
计数
// 全表计数
select count(*) from trade_user;
// 去重计数
select count(distinct name) from trade_user;
// 全表计数
select count(1) from trade_user;
// 字段计数,id如果有值为null,不会计入总数
select count(id) from trade_user;
// 分组计数
select count(*) from trade_user group by email;
COPY
又来讨论下count(*), count(1), count(column)了
count()计数:只有有行就+1,不管列值
count(1):
count(column): 列不为空+1,否则+0
结果:count()=count(1)=count(id)=count(非空column) !=count(可空列)
什么?我说的有毛病?那你还是看看Stackoverflow的说法?:What is better in MYSQL count(*) or count(1)?
看看MySQL官网的说法:MySQL Aggregation Function
*InnoDB handles SELECT COUNT() and SELECT COUNT(1) operations in the same way. There is no performance difference.MyISAM COUNT(1) is only subject to the same optimization if the first column is defined as NOT NULL.**
求和
select sum(paid_amount) from trade_order;
COPY
求和避坑
sum()会返回空值,这时候需要应用层判断或者使用数据库函数处理:
select COALESCE(sum(paid_amount), 0) from trade_order;
select IFNULL(sum(paid_amount), 0) from trade_order;COPY
sum()可能会溢出,不过一般不用担心,一般处理钱的问题都是bigint并且以分为单位,如果溢出了说明你家公司效益逆天,扶摇直上九万里。
sum()可能会有性能问题,万一你的条件是全表扫描并且数据很多,那就GG了,所以可以用替代方案,比如:redis 的incr一直加或者减就可以替代某一类的sum。
取平均值
select avg(paid_amount) from trade_order;
COPY
最大值
select max(paid_amount) from trade_order;
COPY
最小值
select min(paid_amount) from trade_order;
COPY
连接(join)
内连接(inner join)
匹配条件左右两边都有值时才会返回记录:
select * from trade_user u inner join trade_order r on r.user_id=u.id;
COPY
inner join在一对多关系下会返回重复记录,记得去重。
左连接(left join)
左边的表有值但右边没有匹配,返回的结果集右表为空:
select * from trade_user u left join trade_order r on r.user_id=u.id;
COPY
那个是左表?trade_user因为它在JOIN的右边。
left join在一对多关系下会返回重复记录,记得去重。
右连接(right join)
左边的表有值但右边没有匹配,返回的结果集右表为空:
select * from trade_user u right join trade_order r on r.user_id=u.id;
COPY
那个是右表?trade_order因为它在JOIN的右边。
right join在一对多关系下会返回重复记录,记得去重。
笛卡尔积(product)
-- 第一种笛卡尔积方式
select * from trade_user, trade_order;
-- 第二种笛卡尔积方式
select * from trade_user join trade_order;
COPY
子查询(subqueries)
子查询是一个嵌套在另一个SQL语句中的SELECT语句。其目的通常是处理复杂的业务逻辑,处理后的结果可以作为外部查询条件使用。子查询可以被嵌套在 SELECT、INSERT、UPDATE、DELETE 语句以及另一个子查询中。
子查询分类:
- 相关子查询(correlated subquery)非相关子查询是一个独立的查询,子查询的结果不依赖于外层查询。他们通常在执行时首先被解析和执行,然后将结果集返回给外部查询以供使用。
- 非相关子查询(non-correlated subquery) 相关子查询依赖于外层查询,并且每一行外层查询的结果都需要执行一次子查询。相关子查询在执行时,对外层查询的每一行记录都进行一次子查询操作。
非相关子查询
select id from trade_user where id > 100000不依赖外层的查询。
select * from trade_order where user_id in (select id from trade_user where id > 100000);
COPY
相关子查询
子查询select 1 from trade_order o where o.user_id=u.id依赖了外层查询。
select u.id, u.name from trade_user u where u.id=1 and exists (select 1 from trade_order o where o.user_id=u.id) ;COPY
排序(ordering)
order by age;
order by age desc;
order by age desc, id asc;
order by age + id;
order by date(created_at);
order by alias_age;
COPY
排序避坑
order by age + id;这条SQL在遇到NULL值的时候会有问题,比如我们的SQL如下:
select * from trade_user order by age + id asc limit 10;
COPY
结果输出:
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
| id | name | email | age | birthday | created_at | updated_at |
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
| 525592 | fofcn.tech | fofcn@fofcn.tech | NULL | 1989-05-25 00:00:00 | 2024-04-10 09:31:24 | 2024-04-10 09:31:24 |
| 1 | b | user9@test.com | 12 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 4 | User 12 | user12@test.com | 15 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 8 | User 16 | user16@test.com | 11 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 3 | User 11 | user11@test.com | 19 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 5 | User 13 | user13@test.com | 18 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 15 | User 5 | user5@test.com | 8 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 16 | User 6 | user6@test.com | 7 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 10 | User 18 | user18@test.com | 13 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 6 | User 14 | user14@test.com | 28 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
10 rows in set (0.27 sec)
COPY
这很疑惑啊,id=525592出来凑什么热闹?分析下?这条数据和其他的区别就在于age=NULL,再翻翻数据库的文档:对NULL列做运算则结果是NULL,NULL在排序中被视为最小值。举个例子:
mysql> select 1+null;
+--------+
| 1+null |
+--------+
| NULL |
+--------+
1 row in set (0.00 sec)
select * from (
select 1+null as id
union all select 2 as id
union all select 3 as id
union all select 4 as id
) t order by id asc limit 2;
+------+
| id |
+------+
| NULL |
| 2 |
+------+
2 rows in set (0.00 sec)
select * from (
select 1+null as id
union all select 2 as id
union all select 3 as id
union all select 4 as id
) t order by id desc limit 2;
+------+
| id |
+------+
| 4 |
| 3 |
+------+
2 rows in set (0.00 sec)
COPY
分组(grouping)
分组(grouping)可能遇到的问题
- this is incompatible with sql_mode=only_full_group_by
原因: COPY
SQL-92及更早版本的标准不允许在查询中,选择列表,HAVING条件或ORDER BY列表引用非聚合列,且这些列在GROUP BY子句中未被命名。例如,以下查询在SQL-92标准中是非法的,因为select列表中的非聚合列name未出现在GROUP BY中:
SELECT o.custid, c.name, MAX(o.payment)
FROM orders AS o, customers AS c
WHERE o.custid = c.custid
GROUP BY o.custid;
要使此查询在SQL-92中合法,必须从select列表中省略name列,或者在GROUP BY子句中命名它。
SQL:1999及以后的版本允许这种非聚合列存在于可选功能T301中,前提是它们在功能上依赖于GROUP BY列:如果name和custid之间存在这样的关系,查询就是合法的。例如,如果custid是customers的主键,那么这种情况就会发生。
解决方式:
```sql
SELECT @@session.sql_mode;
set @@session.sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
set @@global.sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
- NULL值
union/union all
UNION 命令用于合并两个或两个以上 SELECT 语句的结果集。同时,UNION 会删除结果集中重复的行。
UNION 通过比较结果集中所有的行来去除重复行,这一过程对应的是一个完全的行比较,只有两行数据中的所有字段都完全一致,系统才会识别这两行为重复并进行去重。
需要注意的是,UNION 命令只会删除完全一样(所有列的值都一样)的行。
当使用 UNION 时,每个 SELECT 语句必须具有相同数量的列,列也必须具有相像的数据类型,且顺序也必须相同。
如果你不想去除结果集中的重复行,可以使用 UNION ALL。相比 UNION,UNION ALL 不会去除重复行,所以它的执行速度比 UNION 更快。
select 1 as id
union
select 1 as id
union
select 2 as id;
select 1 as id
union all
select 1 as id
union all
select 2 as id;
COPY
union 和 union all 区别?
| 区别 | UNION | UNION ALL |
|---|---|---|
| 去重 | UNION 会自动去除所有重复的行 |
UNION ALL 不会去除重复的行 |
| 性能 | 因为去重的操作,UNION 的性能可能比 UNION ALL 的性能较低 |
UNION ALL 的性能一般会优于 UNION |
| 结果集大小 | UNION 返回的结果集可能小于或等于两个查询结果集的和 |
UNION ALL 返回的结果集大小恰好等于两个查询结果集的和 |
| 操作 | UNION 对两个结果集执行集合并(set union) |
UNION ALL 合并两个结果集,包括所有重复的行 |
select 1 as id
union
select 1 as id
union
select 2 as id;
+----+
| id |
+----+
| 1 |
| 2 |
+----+
2 rows in set (0.00 sec)
select 1 as id
union all
select 1 as id
union all
select 2 as id;
+----+
| id |
+----+
| 1 |
| 1 |
| 2 |
+----+
3 rows in set (0.00 sec)
select 1 as id, 2 as name
union
select 1 as id, 3 as name
union
select 2 as id, 1 as name;
+----+------+
| id | name |
+----+------+
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
+----+------+
3 rows in set (0.00 sec)
select 1 as id, 2 as name
union
select 1 as id, 2 as name
union
select 2 as id, 1 as name;
+----+------+
| id | name |
+----+------+
| 1 | 2 |
| 2 | 1 |
+----+------+
2 rows in set (0.00 sec)COPY
窗口函数(window function)
窗口函数与Group By比较
空值处理 (null handling)
以下是上述内容的口语化版本:
表示不知道或缺失的信息:
NULL可以理解为某条数据中一种"我不知道"或者"信息缺失"的状态。无法用常规方式比较:
NULL不等于任何值,包括它自己。我们不能用=,<,或者<>这样的运算符来检查一个值是否是NULL,但可以使用IS NULL或IS NOT NULL。在排序时的特别位置:在排序时,比如使用
ORDER BY,NULL通常会被看作是最小的值。如果你是升序排序,NULL会排在最前;如果是降序排序,NULL会放在最后。参与运算结果还是未知:在做数学运算时,无论是和什么数运算,只要有
NULL参与,结果就是NULL。在统计运算中被忽视:在做统计运算时,大多数时候
NULL会被忽略掉,但如果我们计算所有的行数,比如用COUNT(*),NULL就会被计进去。在逻辑判断中为假: 在 MySQL 中,
NULL和零都被看作是假,而其他的非零和非NULL的值都被视为真。可以被加索引:如果你使用的是 MyISAM,InnoDB 或者 MEMORY 这些存储引擎,你可以在可能有
NULL值的列上加索引。在分组中被认为是一样的: 当我们做分组计算的时候,所有的
NULL都被认为是一样的。适用于所有数据类型: 几乎所有的数据类型都可以包含
NULL,NULL本身并没有数据类型。不阻止插入零或空字符串:即使列被设定为
NOT NULL也完全可以插入零或空字符串,因为真正被阻止的是NULL,而零和空字符串都是具体的值。无法通过 in 运算符查询:例如,语句
select * from trade_user where age in (null)不会返回任何结果,因为NULL不能被直接查询,如果需要查询NULL值,应使用IS NULL语句。
更新
删除
索引(indexing)
调优(tuning)
事务(transaction)
关于事务和事务隔离级别可以参考:
锁 (locks)
关于锁可以参考:
internals
join
关于join可以参考:





























![天池医疗AI大赛[第一季] Rank5解决方案](https://img-blog.csdnimg.cn/img_convert/0908ad1e2b90b774ba481b52903f4661.png)
![lucas定理+数位dp+组合数学,蓝桥杯真题[组合数问题]](https://img-blog.csdnimg.cn/direct/9d4bf68ae9e44a998d50f21f1382f106.png)