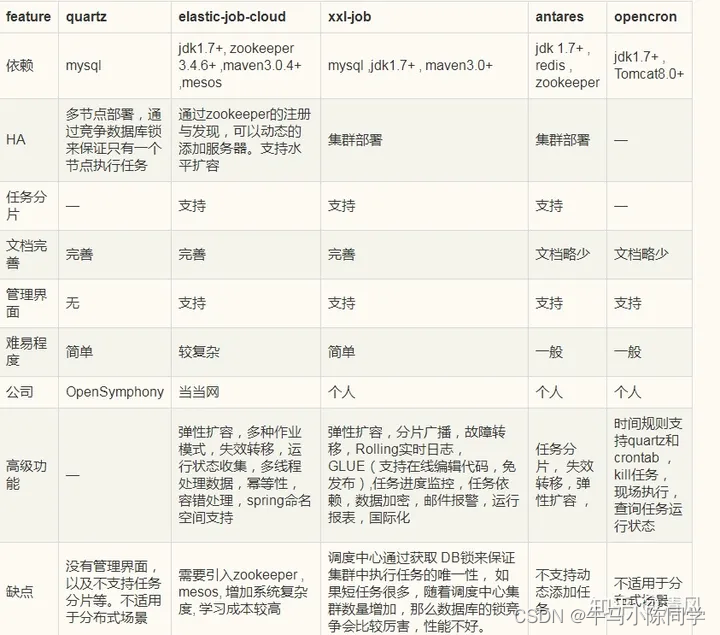
1、模型构建目的:预测下个月产值以及回厂台次用以指导每个店每个月的目标制定
2、数据集构建:
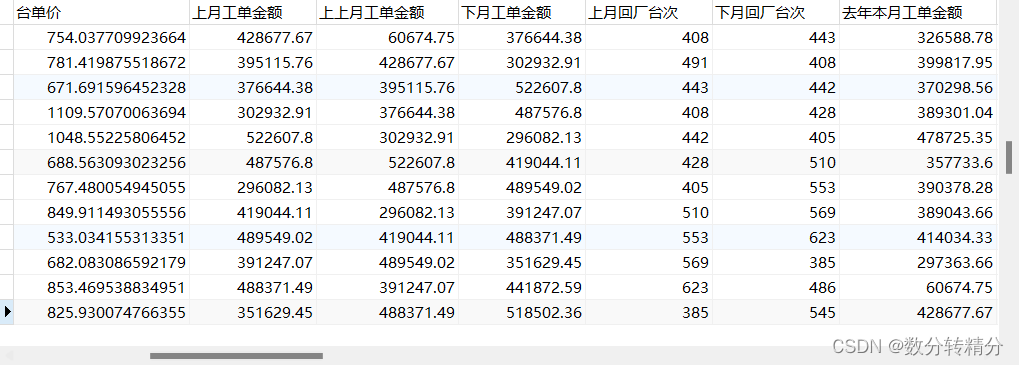
和业务方面进行确定,最终选取42个标签构建初始数据集,其中包括经销商代码、当月工单金额、平均结算时间、本月回厂台次等标签。
数据集为自有数据,通过数据库进行初步处理得出。
3、数据集清洗以及特征构建
(1)空值、缺失值删除该条记录。考虑到并没有办法获得实际的数据,用插补法会影响数据集,导致预测结果不准,所以对空值以及缺失值进行删除。
(2)其他条件。判断该经销商是否退网,以及按照业务方面要求对不符合要求的数据进行剔除,每个保有客户平均回店次数在2次左右,平均每个客户一年的产值大概在1100元左右,从而计算出来每个店平均每月的产值,对差值过大的数据进行剔除。
(3)分类型变量转换。所使用到的分类数据为无序高基数类别特征,所以使用目标编码对其中的四个标签进行转换。
(4)数据特征构建。与业务方面沟通后首先确定几个重要的特征,通过PolynomialFeatures和FunctionTransformer对数据集中的数据生成额外的特征。
4、模型构建
使用二级Stacking对模型进行构建,其中基模型通过对决策树、随机森林、XGboost、LightGBM、CatBoost、Linear Regression、Lasso、Gradient Boosting这些模型进行比较,选取4个作为基模型。
最终选取XGboost、LightGBM、CatBoost、Gradient Boosting这几个模型作为基模型。元模型选择随机森林。
# 模型训练
models = {
'Decision Tree': DecisionTreeRegressor(),
'Random Forest': RandomForestRegressor(),
'XGBoost': XGBRegressor(),
'LightGBM': LGBMRegressor(),
'CatBoost': CatBoostRegressor(),
'Linear Regression': LinearRegression(),
'Lasso': Lasso(),
'Gradient Boosting': GradientBoostingRegressor()
}
# 对训练集中的特征进行目标编码
X_train_encoded = X_train.copy()
X_train_encoded[features_to_encode] = encoder.fit_transform(X_train[features_to_encode], y_train)
# 对测试集中的特征进行目标编码
X_test_encoded = X_test.copy()
X_test_encoded[features_to_encode] = encoder.transform(X_test[features_to_encode])
for name, model in models.items():
model.fit(X_train_encoded, y_train)
y_pred = model.predict(X_test_encoded)
mape = mean_absolute_percentage_error(y_test, y_pred)
print(f'{name} MAPE: {mape}')5、结果
下月产值预测模型的误差在19%,下个月回厂台次预测的模型误差在11%左右