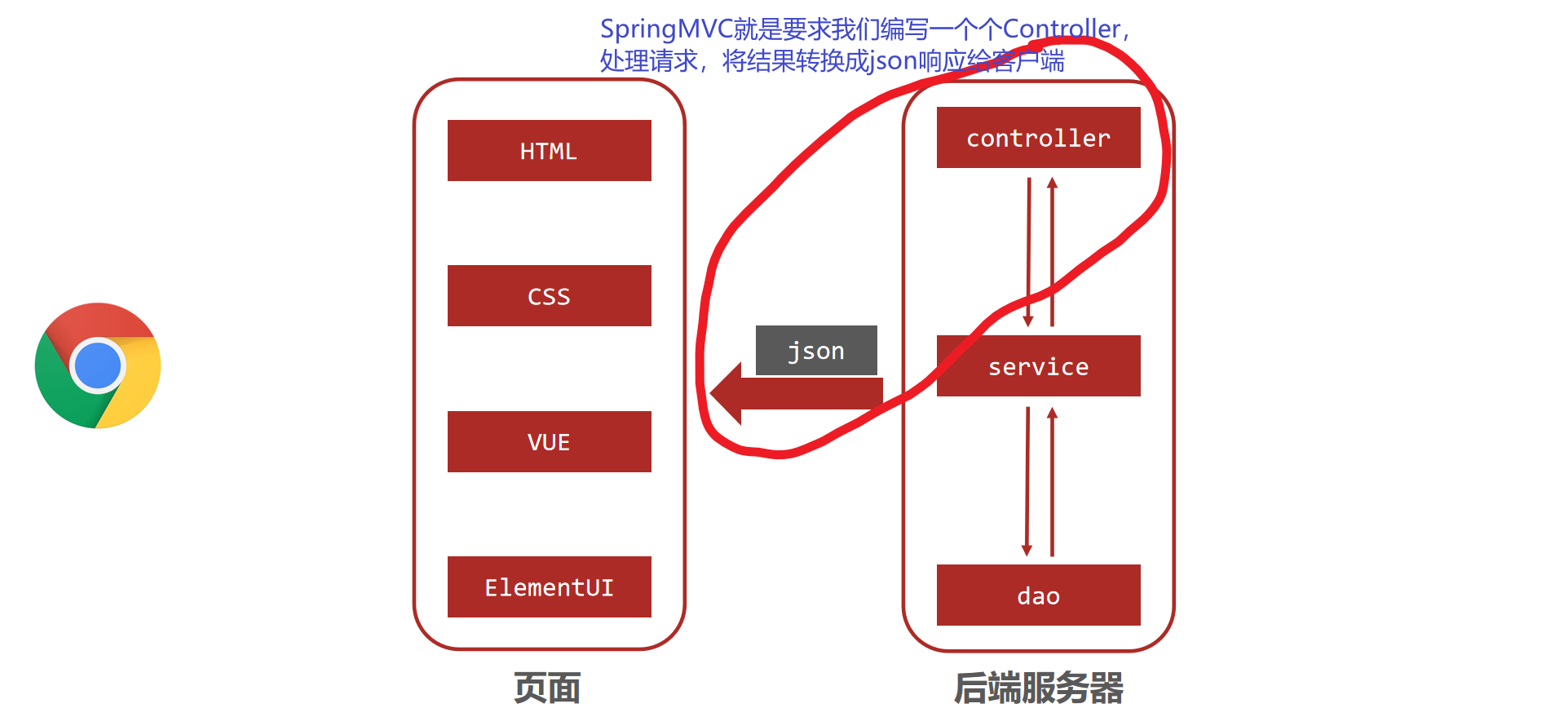
一.JVM简介
jvm及Java virtual machineJava虚拟机,它是一个虚构出来的计算机,一种规范。其实抛开这么专业的句子不说,就知道 JVM 其实就类似于一台小电脑运行在 windows 或者 linux 这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,而操作系统可以帮我们完成和硬件进行交互的工作。
二.JVM运行时数据区
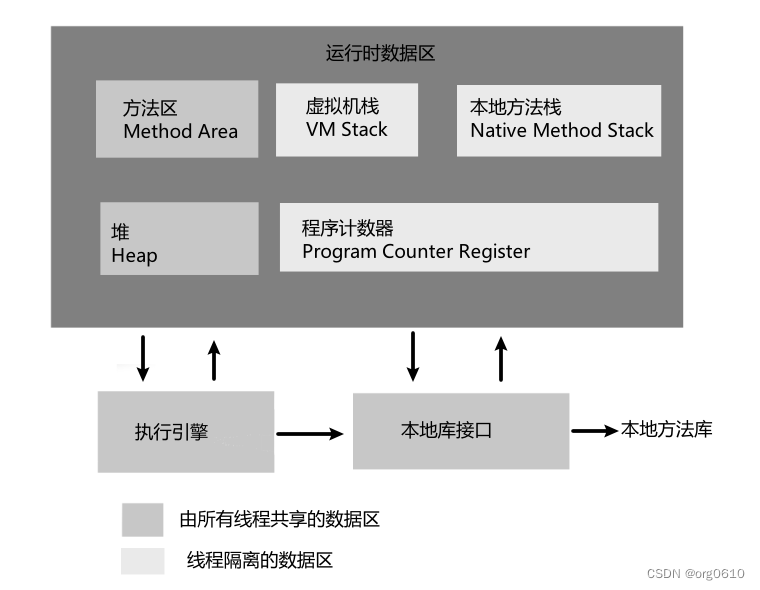
jvm就相当于是一个运行起来的java进程,每运行起来一个进程,jvm就要向内存申请一大块空间,将它划分成不同区域,每个区域有不同作用。jvm运行时数据区也叫做内存布局
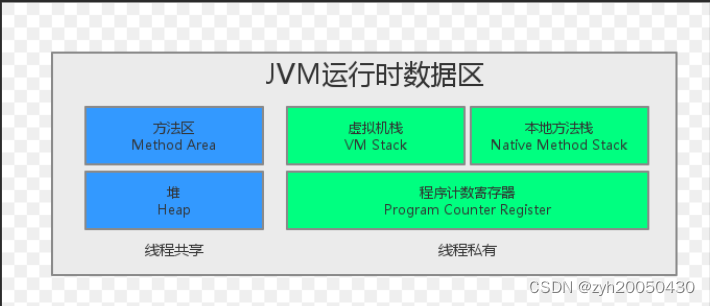
1.方法区/元数据区
存放的是类对象(.class文件加载到内存中就是类对象了)
运行时常量池也在方法区,存放字面量与符号引用。
字面量:字符串,final常量,基本数据类型的值
符号引用:类和结构(struct)的完全限定名,字段的名称和描述符,方法的名称和描述符
2.堆
存放代码中new出来的对象。堆占的空间最大
3.栈/虚拟机栈(线程私有)
存放代码执行过程中方法之间的调用关系。其中的每个元素叫做栈帧,每个栈帧代表了一个方法的调用:栈帧里面包含了方法入口,方法返回的位置,方法的形参,返回值,局部变量……
4.程序计数器(线程私有)
它占的空间最小。主要存放“地址”,表示下一条要执行的指令在内存的哪里(也就是在方法区的哪里。在方法区里,每个方法里面的指令都是以二进制形式存储的)
class A{
public void a(){
}
public void b(){
}
}如上a和b方法会被编译成二进制指令,放到.class文件中,当执行类加载时,就可以把.class文件中的内容加载到内存中,此时,方法的指令就进入到类对象中了。
刚开始调用方法时,程序计数器记录的是方法的入口地址。
5.本地方法栈(线程私有)
存放的是由native修饰的方法的调用关系
总结
总结一下:栈以及程序计数器是每个线程都有一份(比如:一个jvm进程中由10个线程,那么就有10个栈和程序计数器),但公用一份堆和方法区
示例
class A{
public int n=10;
public static int b=100;
}
public class Test {
public static void main(String[] args) {
A a=new A();
}
}
如上,n,b,a,都分别存放在jvm内存的哪里?
a是局部变量,所以a放在栈上。
n是成员变量,它的产生是依赖对象的,也就是说,只有有lA对象才会有n。恰好在main方法中new了一个A对象,这个对象是存放在堆上的,n是跟随对象的,所以n在堆上
b是一个静态成员变量,b只有一份,跟随类对象,所以b在方法区/元数据区
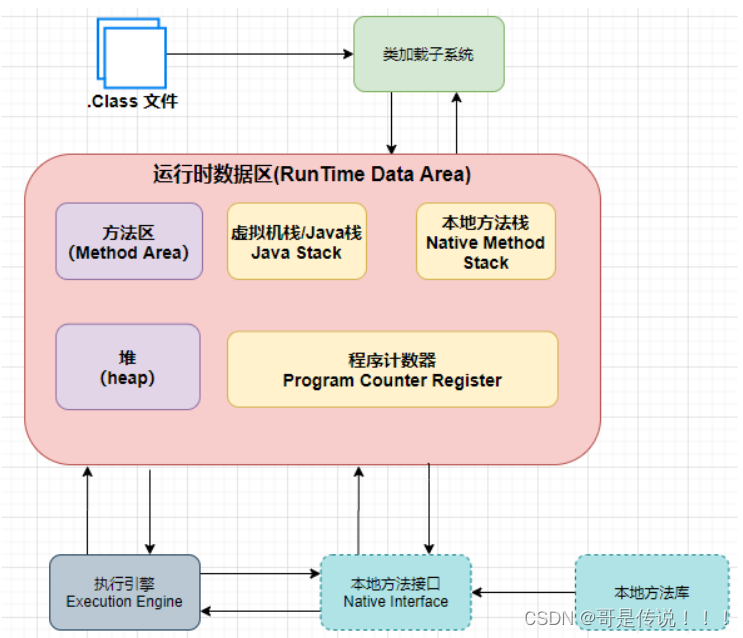
三.JVM类加载
1.类加载过程
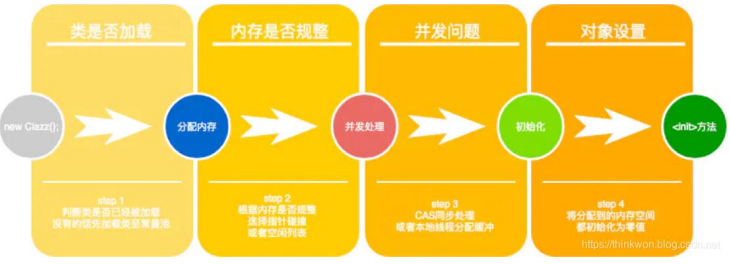
加载:
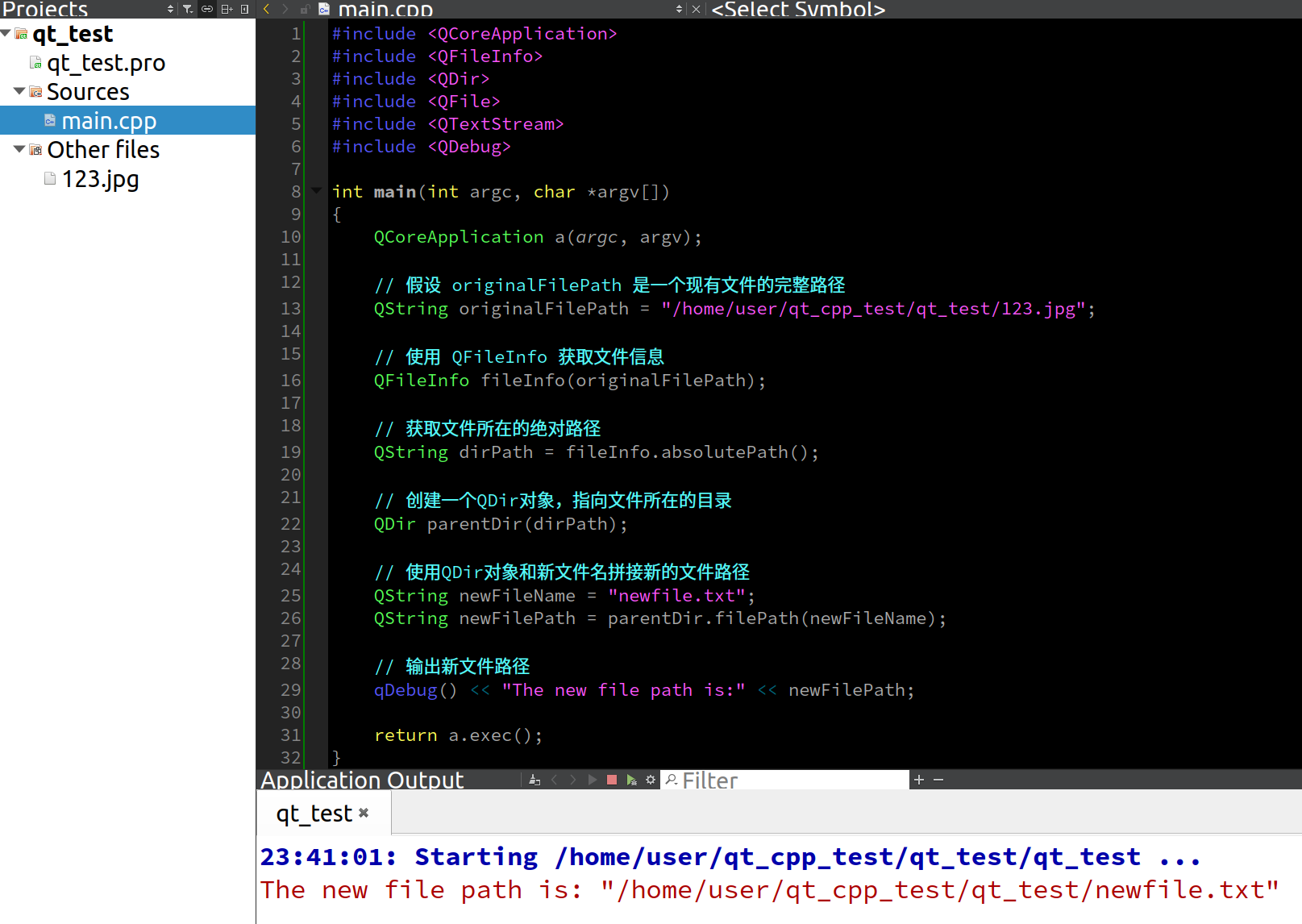
找到.classwen文件,打开文件,读取文件内容。往往代码中会给定某个类的全限定类名(例如java.lang.String),jvm根据类名,在一些指定目录范围内寻找
验证:
.class文件是二进制(每个字节都有特定含义),这个阶段的目的就是确保.class文件的字节流中包含的信息符合《Java虚拟机规范》全部约束要求,保证这些信息被当作代码运行后不会危害到虚拟机自身安全
在java官方文档上就有.class文件的书写规则
准备:
给类对象及其上面的变量分配内存空间,只是分配,还未初始化,此时空间上的内存的数值全为0(此时若尝试打印static成员,就是全0)
解析:
针对类对象中包含的字符串常量进行处理,进行初始化(java代码中用到的字符串常量,在编译后也会进入到.class文件中)。
注意:对于final String s=“text”;这个test会进入到.class文件中,与此同时,.class文件的二进制指令中也会有一个s引用被创建出。按理说,引用变量中存放的是对象的地址,但是.class文件现在只是一个文件,不涉及到地址,所以无法向s中存放text的地址,所以暂时,s中存放的是text在文件中的偏移量,称为文件的偏移量(例如:假设test开头距文件开头为100个字节,那么s中就存放100)等加载到内存中后,再把s的值替换为真正的内存地址)
这个过程也叫做把符号引用替换为直接引用。
初始化:
针对类对象进行初始化:
把类对象需要的各个属性设置好
初始化static成员
执行静态代码块
加载父类
2.双亲委派模型
这个模型用于类加载的第一个阶段:加载过程中寻找.class文件
类加载器:
这是jvm中的一个模块,jvm一共内置了三个类加载器
1.BootStrapClassLoader 爷爷
2.ExtensionClassLoader父亲
3.ApplicationClassLoader儿子
这三个类从上到下构成了父子关系。这个父子关系不是由继承构成的,而是这几个类里面有一个parent属性,指向了一个”父“类加载器(其实说是双亲,实际不是一父一母,而是只有父亲)
基于双亲委派模型的加载过程
1.给定一个类的全限定名
2.从ApplicationClassLoader作为入口,开始查找逻辑
3.ApplicationClassLoader不会立即扫描自己负责的目录(它负责搜索项目当前目录和第三方库对应的目录),而是把查找任务先交给自己的父亲ExtensionClassLoader
4.ExtensionClassLoader也不会立即扫描自己负责的目录(他负责搜索jdk中一些扩展的库对应的目录),而是把查找任务交给自己父亲BootStrapClassLoader
5.BootStrapClassLoader也不想立即搜索自己负责的目录(他负责的是标准库中的目录)。但发现自己没有父亲,因此只能亲自扫描标准库中的目录。但若不是标准库中的类,任务就会被教给孩子执行
6.BootStrapClassLoader没有搜索到,所以就交给了儿子ExtensionClassLoader,扫描扩展库中的目录。
7.没找到就交给孩子ApplicationClassLoader,扫描当前项目和第三方库中的目录。
8.若还是没有找到,就会抛出ClassNotFoundException
目的:
主要是为了确保标准库中的类被加载的优先级最高,其次是扩展库,最后是自己写的类和第三方库。
双亲委派模型不是必须遵守的,它是可以被打破的(在自定义类加载器时可以不遵循)。就比如Tomcat中加载webapp,其中的类只能在webapp中寻找
四.垃圾回收——GC
Java中的垃圾回收机制,主要就是让jvm自己判断某个内存是否不再使用,若确定不用了,jvm就会自动把内存回收。
1.GC回收的目标
它回收的是内存中new出来的对象。那其他的呢?
而对于栈中的局部变量,它是跟随栈帧的生命周期,方法接收,局部变量的空间就自动释放了
而对于静态变量,它的生命周期就是整个程序,始终存在,无需释放。
2.GC大致分为两步
寻找垃圾:
在GC圈子中,寻找垃圾主要有两种主流方案(Java使用的是第二种)
引用计数
new出来的对象,会单独在它的旁边安排一块空间用来保存一个引用计数(计数器),这个计数器描述了这个对象有几个引用指向它。当没有引用指向时,该数就会是0,就可以被视为垃圾。
引用计数的缺点:
1.比较浪费内存空间
一个计数器,咋说也得2个字节的空间,假设对象本身很小,那么计数器占据的空间比例就很大。
2.引用计数机制存在循环引用问题
class A{ public A t; } public class Test { public static void main(String[] args) { A a=new A(); A b=new A(); a.t=b; b.t=a; } }上述代码,a、b是局部变量,存放在栈中,堆上的第一个A对象中的t引用存放的是堆上的第二个A对象的地址,堆上的第二个A对象中的t引用存放的是堆上的第一个A对象的地址。所以此时,第一个A对象的引用计数为2(一个是栈上的a,另一个是堆上的第二个A对象的t变量),第二个A对象的引用计数也是2,当代码执行到a=null b=null后,a、b在栈上的内存被释放了,所以a、b变量消失了,所以第一个A对象的引用计数减一,变成了1(这个1就是堆上的第二个A对象的t变量),同理堆上的第二个A对象的引用计数也变成1了。
到此为止,jvm认为两个对象都有引用指向,所以不是垃圾,所以就不回收
但此时,new出来的两个对象已经无法被其他代码访问到了,但是却没有被回收)
可达性分析
本质:用时间换取空间
有一个/组线程,周期性的扫描代码中的所有对象。就是从一些特定的对象触发,把所有能访问到的对象,都标记成可达,反之未标记的就是垃圾
可达性分析的出发点有很多:不仅仅是局部变量,还有常量池中引用的对象,方法区中的静态引用类型引用的变量……这些出发点就被称为GCRoots
可达性分析是周期性进行的,当前某个对象是否是垃圾,会随代码进行发生改变
回收垃圾:
如何回收垃圾?主要有下面三种做法
标记清除(简单粗暴)
就是把被标记到的对象直接释放掉。

这样非常不靠谱,会产生很多内存碎片。
随着时间推移,内存碎片的情况会愈演愈烈
复制算法
通过copy的方式,把有效对象集中到一起,再同意释放剩余空间
将内存分成大小相等的两份,每次只用其中的一份,当需要进行垃圾回收时,就会先将不需要回收的对象复制到内存中的另一半(是连续复制,不留空位),然后统一释放那一半。
复制算法的缺点:
1.内存浪费一半,内存利用率不高
2.当有效对象很多时,拷贝操作的开销很大。
标记整理
既能解决内存碎片问题,又能解决内存利用率不高的问题
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
如上,假如1,4,6是被标记的要被清除的垃圾,标记整理就相当于是顺序表删除元素时的搬运操作:将2搬到1位置,将3般到2位置,将5搬到3位置,将7搬到4位置,最后释放5、6、7位置的元素
标记整理未解决的问题就是搬运操作(copy)的开销很大
jvm的垃圾回收机制-分代算法
jvm找到垃圾后是使用那种方法进行垃圾的回收呢?它采用的是上述三种思路的结合体
分代算法就是通过区域划分,实现不同区域和不同垃圾的回收策略,从而实现更好的垃圾回收。。
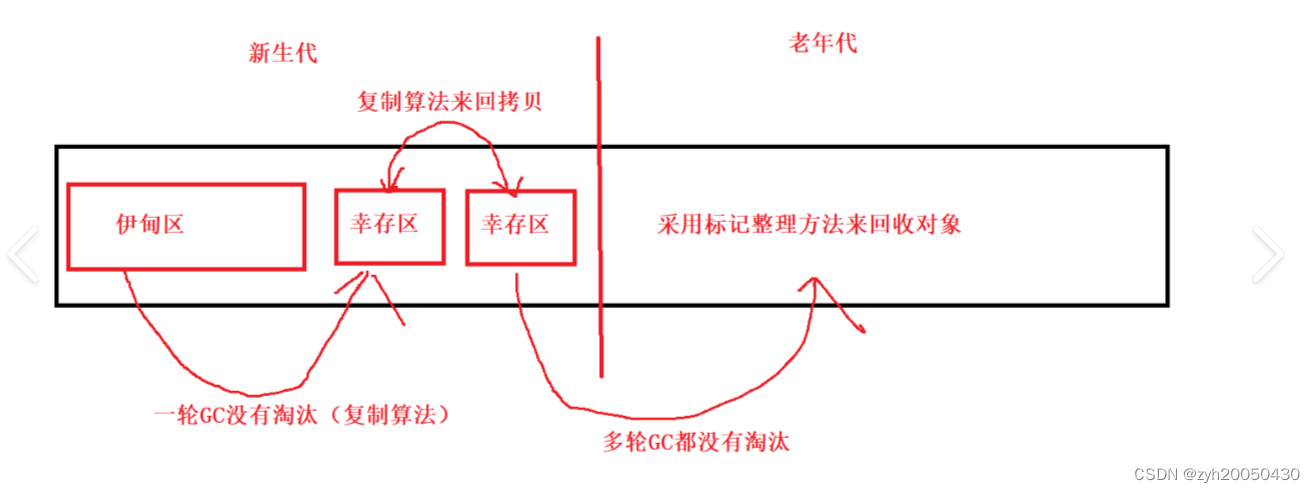
首先将一整个内存分为两大部分(不用平均分配),左边统称为新生代,右边就是老年代。在新生代,又划分为伊甸区和幸存区,其中幸存区被均分成两部分。
刚new的对象被放到伊甸区。从对象诞生到第一轮可达性分析扫描,虽然时间不长,但是凭经验来看,该时间内大部分对象都会变成垃圾,剩余不是垃圾的,就被放到幸存区,这个放就可以说是复制算法。由于经验规律(短时间内大部分对象都会变成垃圾的经验),真正需要复制到对象不多,很适合复制算法。
在幸存区的对象,都是活过了第一轮GC的对象。GC的扫描线程也会扫描幸存区,并将活过GC的对象复制到幸存区的另一半,释放上一半。反复像上面这样在幸存区进行多轮GC,使用的也是复制算法
当对象已经在幸存区活过了很多轮GC后,jvm就会认为它短时间内释放不掉了,就会把它放到老年代
老年代的对象被GC扫描的频率很低,从而减少了GC开销
总结:
新生代主要使用复制算法,老年代主要是标记整理。
而标记清除太不靠谱了,所以不采用